Golf Single-Page Documentation for version 3.3.0
This page contains all of Golf documentation topics combined into one. It may be easier to search. You can also download this page (or the entire site) and use it locally.
123-hello-world
about-golf
abs-number
after-handler
application-setup
article-capi
article-cookies
article-debug
article-distributed
article-encryption
article-fetch-web-page
article-fifo
article-file-manager
article-hello-server
article-hello-world
article-hello-world-service
article-hello-world-service-web
article-how-to-create-golf-application
article-json
article-language
article-mariadb
article-memory-safety
article-memory-safety-web
article-notes-postgres
article-random
article-record-temperature-mariadb
article-record-temperature-postgres
article-record-temperature-sqlite
article-regex
article-remote-call
article-request-function
article-security
article-sendmail
article-server
article-shopping
article-sqlite
article-statements
article-status-check
article-tree
article-tree-web
article-vim-coloring
article-web-framework-for-c-programming-language
article-what-is-golf
article-what-is-web-service
before-handler
begin-handler
begin-transaction
boolean-expressions
break-loop
call-extended
call-handler
call-remote
call-web
CGI
change-dir
change-mode
Client-API
close-file
code-blocks
command-line
commit-transaction
connect-apache-tcp-socket
connect-apache-unix-socket
connect-haproxy-tcp-socket
connect-nginx-tcp-socket
connect-nginx-unix-socket
continue-loop
copy-file
copy-string
count-substring
current-row
database-config-file
db-error
debugging
decode-base64
decode-hex
decode-url
decode-web
decrypt-data
delete-cookie
delete-dir
delete-fifo
delete-file
delete-lifo
delete-list
delete-string
delete-tree
derive-key
devel-versus-release
directories
documentation
do-once
encode-base64
encode-hex
encode-url
encode-web
encrypt-data
error-code
error-handling
examples
exec-program
exit-handler
exit-status
extended-mode
file-position
file-storage
file-uploading
finish-output
flush-output
get-app
get-cookie
get-hash
get-lifo
get-list
get-message
get-param
get-req
get-sys
get-time
get-tree
get-upload
ggcli
gg
golf-license
hash-string
hmac-string
if-defined
if-true
inline-code
install-golf
install-package
json-doc
lock-file
lower-string
mariadb-database
match-regex
memory-handling
mgrg
new-array
new-dir
new-fifo
new-hash
new-lifo
new-list
new-message
new-remote
new-string
new-tree
number-expressions
number-string
open-file
out-header
output-statement
pause-program
permissions
position-list
postgresql-database
print-format
print-out
print-path
purge-array
purge-fifo
purge-hash
purge-lifo
purge-list
purge-tree
quit-process
random-crypto
random-string
read-array
read-fifo
read-file
read-hash
read-json
read-lifo
read-line
read-list
read-message
read-remote
read-split
read-tree
read-xml
rename-file
replace-string
report-error
request-body
request
resize-hash
return-handler
rewind-fifo
rewind-lifo
rollback-transaction
run-query
run-remote
scan-string
SELinux
SEMI
send-file
Server-API
service
set-app
set-bool
set-cookie
set-number
set-param
set-string
silent-header
split-string
sqlite-database
start-loop
statements
stat-file
string-expressions
string-length
string-number
syntax-highlighting
temporary-file
text-utf
trim-string
uninstall
uniq-file
unlock-file
unused-var
upper-string
use-cursor
utf-text
variable-scope
web-framework-for-C-programming-language
write-array
write-fifo
write-file
write-hash
write-lifo
write-list
write-message
write-string
write-tree
xml-doc
123 hello world
First, install Golf.
Create Hello World source file (hello.golf) in a new directory; note it's all one bash command:
echo 'begin-handler /hello public
@Hello World!
end-handler' > hello.golf
Copied!

Create Hello World application:
gg -k helloworld
Copied!
Make Hello World application:
gg -q
Copied!
You can run Hello World both as a service and from command line:
- As a service, first start your Hello World application server:
mgrg -w 3 helloworld
Copied!
then connect to the service:
gg -r --req="/hello" --silent-header --service --exec
Copied!
- Execute as command-line program:
gg -r --req="/hello" --silent-header --exec
Copied!
Hello World!
Copied!
Quick start
123-hello-world
See all
documentation
About golf
Golf's main purpose is easy and rapid development and deployment of high-performance applications on Linux. It is a memory-safe programming language and application server, that creates native compiled executables. It is declarative, functional and service oriented.
Golf is built with industry-standard Free Open Source libraries, extensible with C programming language, and licensed under Apache 2 Free Open Source.
Declarative and functional
All Golf programs are translated into C programming language, which is considered the fastest and most efficient programming language. Golf's goal is to be easy to work with and quick to produce the functionality you want, yet also to create C code that would be comparable to that of an experienced C programmer. This synergy can produce the best performance with memory safety along with very simple yet powerful language statements.
A Golf program works as a service provider, meaning it handles service requests by providing a reply. It can be either a service or a command-line program that processes GET, POST, PUT, PATCH, DELETE or any other HTTP requests.
The URL for a request must state the application name, and a also request name which is the source file handling it. So, "/app-name/my-request" means that application name is "app-name" and that "request_name.golf" file will implement a request handler. A request executes in this order:
A Golf service is served by either
- a fixed number of service processes, or
- a dynamic number based on the request load, from 0 to any maximum number specified.
Each Golf service process handles one request at a time, and all such processes work in parallel. This means you do not need to worry about thread-safety with Golf. Server processes generally stay up across any number of requests, increasing response time. The balance between the number of processes and the memory usage during high request loads can be achieved with adaptive feature of mgrg, Golf's service process manager.
A service can be requested by:
- reverse proxies, such as Apache, Nginx, HAProxy etc.,
- programs written in any language using Client-API,
- Golf's own gg utility (see -r option), or ggcli command-line client.
- another Golf service by means of call-remote (on secure networks) and call-web (on the web via SSL/TSL secure connections).
- standard web utilities like curl.
With call-remote, you can execute remote requests in parallel, and get results, error messages and exit status in a single statement. This makes it easy to distribute and parallelize your application logic and/or build application tiers on a local or any number of remote machines, without having to write any multi-threaded code.
A command-line program handles a single request before it exits. This may be suitable for batch jobs, for use in shell scripts, for testing/mocking, as well as any other situation where it is more useful or convenient to execute a command-line program. Note that a command-line program can double as CGI (Common Gateway Interface) as well.
Golf services and command-line programs can implement most back-end application layers, including
- presentation (eg. building a web page),
- application logic,
- data (eg. database) layers, and any others.
Golf programming language is memory-safe, meaning it will prevent you from accidentally overwriting memory or freeing it when it shouldn't be. Golf's memory-handling is not limited to just memory safety; it also includes automatic freeing of memory at the end of a request, preventing memory leaks which can be fatal to long running processes. Similarly, files open with file-handling statements are automatically closed at the end of each request, serving the same purpose.
Golf goes a step further from memory safety. It also enforces status checking for statements that may cause serious application logic errors. This is done by checking for negative status outcome at run-time, but only if your code does not check for status, and by stopping the application if it happens. This provides for much safer application run-time because it prevents further execution of the program if such outcome happens, and it also forces the developer to add necessary status checks when needed. This feature is automatic and has an extremely low impact on performance.
Golf is a strongly-typed language, with only three primitive types (numbers, strings and booleans) and a number of structured types (array, message, split-string, hash, tree, tree-cursor, fifo, lifo, list, file and service). Golf is a declarative language, with a few lines of code implementing large functionalities. Golf is also very simple, as it's designed to achieve application goals with less coding.
The number type is a signed 64-bit integer (as a decimal, octal or hexadecimal C notation). The boolean type evaluates to true (non-zero) or false (zero). The string type evaluates to any sequence of bytes (binary or text) that is always trailed with a null character regardless, which is not counted in string's length. All constants follow C rules of formatting.
Golf statements are designed for safety, ease of use, and ability to write stable code. Most statements typically perform common complex tasks with options to easily customize them; such options are processed at compile-time whenever possible, increasing run-time performance.
A variable is created the first time it's encountered in any given scope, and is never created again in the same or inner scopes, which avoids common bugs involving more than one variable with the same name in related scopes. You can still of course create variables with the same name in unrelated scopes.
Some structured types (hash, tree, list) as well as primitive types (numbers, strings and booleans) can be created with process-scope, meaning their value persists throughout any requests served by the same process. This is useful for making data-server services that allow keeping and fast querying of data (such as caches or data services).
Numbers and booleans are assigned by value, while strings are assigned by reference (for obvious reason to avoid unnecessary copying).
Golf includes request-processing and all the necessary infrastructure, such as for process management, files, networking, service protocols, database, string processing etc.
Golf is a compiled language. Golf applications are native executables by design, hence no byte-code, interpreters and similar. Since Golf is declarative, just a few statements are needed to implement lots of functionality. These statements are implemented in pure C, and are not slowed down by memory checks as they are safe internally by implementation. Only developer-facing Golf code needs additional logic to enforce memory safety, and that's a very small part of overall run-time cost.
Golf provides access to a number of popular databases, such as MariaDB/mySQL, PostgreSQL and SQLite. (see database-config-file):
- transactional support (begin, commit, rollback),
- protection against SQL injections for safety,
- automatic and persistent database connections with unlimited reuse across all SQL queries.
- prepared SQL statements.
Golf uses well-known and widely used Free Open Source libraries like cURL, openSSL, crypto, libbacktrace, fastcgi, standard database-connectivity libraries from MariaDB, PostgreSQL, SQLite etc., for compliance, performance and reliability.
Web framework for C programming language
Do not use object names (such as variables and request names) that start with "_gg_" or "gg_" (including upper-case variations) as those are reserved by Golf.
See contributions for more information.
Golf programming language (or golf-lang) is created and written by Serge Miatovich (team@golf-lang.com).
General
about-golf
devel-versus-release
directories
permissions
See all
documentation
Abs number
Purpose: Get absolute value of a number.
abs-number <number> to <absolute number>
Copied!
abs-number will store absolute value of <number> to <absolute number>. For example, absolute value of -3 is 3, and absolute value of 3 is 3.
set-number my_num = -10
abs-number my_num to abs_num
print-out abs_num new-line
Copied!
The result is 10.
Numbers
abs-number
number-expressions
number-string
set-number
string-number
See all
documentation
After handler
Purpose: Execute your code after a request is handled.
after-handler
...
end-after-handler
Copied!
Every Golf request goes through a request dispatcher (see request()). In order to specify your code to execute after a request is handled, create source file "after-handler.golf" and implement a handler that starts with "after-handler" and ends with "end-after-handler", which will be automatically picked up and compiled with your application.
If no request executes (for example if your application does not handle a given request), after-handler handler does not execute either. If you use exit-handler to exit current request handling, after-handler handler still executes.
Here is a simple implementation of after-handler handler that just outputs "Hi there!!":
after-handler
@Hi there!!
end-after-handler
Copied!
Service processing
after-handler
before-handler
begin-handler
call-handler
See all
documentation
Application setup
A Golf application must be initialized first. This means creating a directory structure owned by application owner, which can be any Operating System user. To initialize application <app name> while logged-in as application owner:
sudo mgrg -i -u $(whoami) <app name>
Copied!
If your application does not use database(s), you can skip this part.
You can setup your database(s) in any way you see fit, and this includes creating the database objects (such as tables or indexes) used by your application; all Golf needs to know is the connection parameters, which include database login information (but can include other things as well). For each database in use, you must provide a database-config-file in the same directory as your Golf source code. This file contains the database connection parameters - these parameters are database-specific. For example, if your code has statements like:
run-query @mydb = ...
begin-transaction @sales_db
Copied!
then you must have files "mydb" and "sales_db" present. For example, MariaDB config file might look like:
[client]
user=golfuser
password=pwd
database=golfdb
protocol=TCP
host=127.0.0.1
port=3306
Copied!
or for PostgreSQL:
user=myuser password=mypwd dbname=mydb
Copied!
To compile and link the application that doesn't use database(s):
gg -q
Copied!
When you have database(s) in use, for instance assuming in above example that "mydb" is MariaDB database, "sales_db" is PostgreSQL, and "contacts" is SQLite database:
gg -q --db="mariadb:mydb postgres:sales_db sqlite:contacts"
Copied!
See gg for more options.
Stop the application first in case it was running, then start the application - for example:
mgrg -m quit <app name>
mgrg -w 3 <app name>
Copied!
See mgrg for more details.
You can run your application as service, CGI or command-line.
Running application
application-setup
CGI
command-line
service
See all
documentation
Use C language API to talk to Golf Server
Golf application server can be accessed via C API. Most programming languages allow for C linkage, so this makes it easy to talk to Golf server from anywhere. The Client-API is very simple with just a few functions and a single data type. It's also MT-safe (i.e. safe for multi-threaded applications).
In this example, a Golf server will use a tree object to store key/value pairs, which can be added, queried and deleted for as long as the server is running (i.e. it's an in-memory database, or a cache server). Client will insert the key/value pairs, query and delete them.
Create a server and start it
mkdir -p c-api
cd c-api
Copied!
Save this into a file "srv.golf":
begin-handler /srv public
silent-header
do-once
new-tree ind process-scope
end-do-once
get-param op
get-param key default-value ""
get-param data default-value ""
if-true op equal "add"
write-tree ind key (key) value data status st
if-true st equal GG_ERR_EXIST
@Key exists [<<print-out key>>]
else-if
@Added [<<print-out key>>]
end-if
else-if op equal "delete"
delete-tree ind key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found [<<print-out key>>]
else-if
@Deleted, old value was [<<print-out val>>]
end-if
else-if op equal "query"
read-tree ind equal (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found, queried [<<print-out key>>]
else-if
@Value [<<print-out val>>]
end-if
end-if
end-handler
Copied!
Create "index" application ("-k"):
gg -k index
Copied!
Compile the server - this also demonstrates excluding directories from compilation (since Golf will by default try to compile the Golf and C code in all subdirectories). In this case, we're excluding subdirectory "client", which we will create in just a sec and place a C client program in it:
gg -q --exclude-dir=client
Copied!
Start the server, with a single server process running:
mgrg -w 1 index
Copied!
Create directory for a C API client, and switch to it:
mkdir client
cd client
Copied!
Next is the C code for your client. It simply inserts key/value pair, queries it, and then deletes it. Nice little program as a way of demonstration. Create file "cli.c" and copy this to it:
#include "gcli.h"
int golf_client (gg_cli *req, char *connection, char *method, char *app_path, char *request, char *url_params);
int golf_client (gg_cli *req, char *connection, char *method, char *app_path, char *request, char *url_params)
{
memset ((char*)req, 0, sizeof(gg_cli));
req->server = connection;
req->req_method = method;
req->app_path = app_path;
req->req = request;
req->url_params = url_params;
return gg_cli_request (req);
}
void main ()
{
int res;
char *urlreq, *data;
gg_cli req;
char dir[GG_MAX_OS_UDIR_LEN];
gg_dir (GG_DIR_SOCKFILE, dir, sizeof(dir), "index", NULL);
urlreq = "/op=add/key=some_key/data=some_data";
res = golf_client (&req, dir, "GET", "/index", "/srv", urlreq);
if (res != GG_OKAY) printf("Request failed [%d] [%s]\n", res, req.errm); else printf("%s", gg_cli_data(&req));
gg_cli_delete(&req);
urlreq = "/op=query/key=some_key";
res = golf_client (&req, dir, "GET", "/index", "/srv", urlreq);
if (res != GG_OKAY) printf("Request failed [%d] [%s]\n", res, req.errm); else printf("%s", data = gg_cli_data(&req));
gg_cli_delete(&req);
urlreq = "/op=delete/key=some_key";
res = golf_client (&req, dir, "GET", "/index", "/srv", urlreq);
if (res != GG_OKAY) printf("Request failed [%d] [%s]\n", res, req.errm); else printf("%s", data=gg_cli_data(&req));
gg_cli_delete(&req);
}
Copied!
Compile C program:
gcc -o cli cli.c $(gg -i)
Copied!
./cli
Copied!
The result is:
Added [some_key]
Value [some_data]
Deleted, old value was [some_data]
Copied!
Cookies in Golf applications, plus HAProxy
Cookies are used in web development to remember the state of your application on a client device. This way, your end-user on this client device doesn't have to provide the same (presumably fairly constant) information all the time. A "client device" can be just a plain web browser, or it can be anything else, such as any internet connected device.
In practicality, cookies are used to remember user name, session state, preferences and any other information that a web application wishes to keep on a client device.
So cookies are quite important for any web application or service. In this example, we'll set a single cookie (name of the user), and then we will retrieve it later. Very simple, but it's the foundation of what you'd need to do in pretty much any application.
First, in a separate directory, create an application "yum" (as in cookies are delicious):
mkdir cookies
cd cookies
gg -k yum
Copied!
Next, create this source code file "biscuit.golf" (for everyone outside the US who feels it should have been "biscuit" instead of "cookie"):
begin-handler /biscuit
get-param action
if-true action equal "enter-cookie"
@<h2>Enter your name</h2>
@<form action="<<print-path "/biscuit">>" method="POST">
@ <input type="hidden" name="action" value="save-cookie">
@ <label for="cookie-value">Your name:</label><br/>
@ <input type="text" name="cookie-value" value=""><br/>
@ <br/>
@ <input type="submit" value="Submit">
@</form>
else-if action equal "save-cookie"
get-param cookie_value
get-time to cookie_expiration year 1 timezone "GMT"
set-cookie "customer-name" = cookie_value expires cookie_expiration path "/"
@Cookie sent to browser!
@<hr/>
else-if action equal "query-cookie"
get-cookie name="customer-name"
@Customer name is <<print-out name web-encode>>
@<hr/>
else-if
@Unrecognized action<hr/>
end-if
end-handler
Copied!
The code is pretty easy: if "action" URL parameter is "enter-cookie", you can enter your name. Then, when you submit this web form (passing back "action" parameter with value "save-cookie"), the cookie named "customer-name" is saved with the value you entered, and the cookie expiration is set 1 year into the future. Then you'll query the cookie value in another request ("query-cookie" as "action" parameter), and you'll get your name back because it was saved on the client.
Okay, so compile the application (with all request handlers public):
gg -q --public
Copied!
Now, start the Golf server to serve up your yummy application:
mgrg -p 3000 yum
Copied!
"-p 3000" means it will run on socket port 3000, and the reason for that will become apparent momentarily.
We'll use HAProxy as a web server in this instance to demostrate that you can use Golf with pretty much any web server or load balancer. To set it up, here is the simple config file (typically in "/etc/haproxy/haproxy.cfg"). Note that "frontend", "fcgi-app" and "backend" sections are relevant to us here; the rest can be as it is by default in whatever configuration file you have (substitute "your-user" for your OS user name):
frontend front_server
mode http
bind *:90
use_backend backend_servers if { path_reg -i ^.*\/yum\/.*$ }
option forwardfor
fcgi-app golf-fcgi
log-stderr global
docroot /home/your-user/.golf/apps/yum/app
path-info ^.+(/yum)(/.+)$
backend backend_servers
mode http
filter fcgi-app golf-fcgi
use-fcgi-app golf-fcgi
server s1 127.0.0.1:3000 proto fcgi
Copied!
So, the HAProxy server will respond on port 90 from the web. We specify that it will redirect any URL starting with "/yum/" to your Golf application. Obviously, if you change your application name from "yum" to something else, change "yum" here too. Then we specify we'd like to use FastCGI protocol, which Golf uses because it's very fast and capable. And finally, we tell HAProxy we'd like to communicate with our server on port 3000. So that's why we used "-p 3000" above when starting the server!
Restart HAProxy for this to take effect:
sudo systemctl restart haproxy
Copied!
Now you can test your application server. Open a browser, and point it to your server where all the above code took place. If you're testing this on your own local machine, then just use "127.0.0.1" - and that's what we'll do here:
http://127.0.0.1:90/yum/biscuit/action=enter-cookie
Copied!
You'd get something like this:
Enter the name, and click Submit, and you'll get the message that the cookie is saved:
Now, enter this URL to query the cookie you set:
http://127.0.0.1:90/yum/biscuit/action=query-cookie
Copied!
And you'll see:
So now you've learned how to use cookies in Golf, and how to use HAProxy too. Of course, you could have used Apache, Nginx or some other web server as well.
How to debug Golf programs with gdb
Debugging information is always included regardless of how you make your application; what varies is the amount of debugging info included. You can compile your Golf application normally:
gg -q
Copied!
This will create an executable that can be debugged with gdb. You can debug your Golf program with gdb just as if it were a plain C program, which technically it is. This makes it much easier to get to the bottom of any issue directly without having to deal with virtual machines, p-code translation, assembler etc.
For this reason, the debugging ecosystem for Golf programs is already fully developed. For instance you can use Valgrind or Google ASAN with Golf programs just as you'd with a C program.
Note that in order to debug the Golf itself, it's best to be compiled from source, or you need to use the included debugging information (meaning you need to install a debug package). This will be covered in another article here on Golf blog.
Here's an example of debugging using Golf. We'll create a little parsing application to illustrate.
First, let's create a directory for our application "split" (since you'll be splitting a URL query string into name/value pairs):
mkdir split
cd split
gg -k split
Copied!
Create a source file "parse.golf" and copy this:
begin-handler /parse
silent-header
set-string str = "a=1&b=2&c=3"
split-string str with "&" to pair count pair_tot
start-loop repeat pair_tot use pair_count
read-split pair_count from pair to item
split-string item with "=" to equal
read-split 1 from equal to name
read-split 2 from equal to value
print-format "Name [%s] value [%s]\n", name, value
end-loop
end-handler
Copied!
This program will parse the string "a=1&b=2&c=3" to produce name/value pairs - this is obviously a parsing of URL query string. It uses split-string statement which will split the string based on some delimiter string, and then you use read-split statement to get the split pieces one by one. Very simple.
Compile and link this:
gg -q --public
Copied!
What's what here? First of all "-q" will make your project (meaning compile and link it, both command-line executable and application server), while "--public" makes all handlers public, meaning they can handle external requests (i.e. those from a caller outside your application).
Okay so now to execute this with gdb, do this:
gg -r --req="/parse"
Copied!
This will produce something like the following (substitute "your-user" for your OS user name):
export CONTENT_TYPE=
export CONTENT_LENGTH=
unset GG_SILENT_HEADER
export GG_SILENT_HEADER
export REQUEST_METHOD=GET
export SCRIPT_NAME="/split"
export PATH_INFO="/parse"
export QUERY_STRING=""
/home/your-user/.golf/apps/split/.bld/split
Copied!
This is basically setting the necessary environment variables and then executing the "split" program (specified here in full path). Remember, Golf program can execute exactly the same as a web application server as well as command-line executable; hence the web environment variables need to be set.
So if you copy and paste the above into bash shell, you'll get:
Name [a] value [1]
Name [b] value [2]
Name [c] value [3]
Copied!
Which is the proper parsing of the string. Okay so far so good.
Now to debug your program, do:
gdb /home/your-user/.golf/apps/split/.bld/split
Copied!
You are now in gdb debugging shell:
GNU gdb (Ubuntu 15.0.50.20240403-0ubuntu1) 15.0.50.20240403-git
Copyright (C) 2024 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from /home/your-user/.golf/apps/split/.bld/split...
(gdb)
Copied!
Now you can use standard gdb commands. We'll set a break in our code above (which is handler "parse"), and then run the program. Next we'll simply execute one statement at a time, and then we'll print the loop variable:
(gdb) br parse
Breakpoint 1 at 0x3a5e: file /var/lib/gg/bld/split/__parse.o.c, line 4.
(gdb) run
Starting program: /home/your-user/.golf/apps/split/.bld/split
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Breakpoint 1.1, parse () at /home/your-user/tmp/test/split/parse.golf:1
4 void parse () {
(gdb) next
2 silent-header
(gdb)
3 set-string str = "a=1&b=2&c=3"
(gdb)
4 split-string str with "&" to pair count pair_tot
(gdb)
5 start-loop repeat pair_tot use pair_count
(gdb)
6 read-split pair_count from pair to item
(gdb)
5 start-loop repeat pair_tot use pair_count
(gdb)
6 read-split pair_count from pair to item
(gdb)
7 split-string item with "=" to equal
(gdb)
8 read-split 1 from equal to name
(gdb)
9 read-split 2 from equal to value
(gdb)
11 print-format "Name [%s] value [%s]\n", name, value
(gdb)
Name [a] value [1]
6 read-split pair_count from pair to item
(gdb) print pair_count
$1 = 1
Copied!
As you can see, you're stepping through your Golf program, with the code showing exactly as it is in your source file! You can do here anything that you can in a C program, for instance set breakpoints, conditions etc. In this case we also print the value of variable pair_count.
gdb is too powerful to summarize here. There are many tutorials on the web. But suffice it to say you can easily debug your programs and see how they work step by step and a lot more (that's an understatement!).
Finally, if you're so inclined, you can also step through generated C code and see exactly what makes your program tick. To do that, make your program with "--c-lines" flag, which lets you do that:
gg -q --public --c-lines
Copied!
Now, repeat the above to get into gdb, and it may look like this (note that generated code can always change and there's absolutely no guarantee it will stay the same!):
Breakpoint 1.1, parse () at /home/your-user/.golf/apps/split/.bld/__parse.o.c:4
4 void parse () {
(gdb) next
7 gg_get_config ()->ctx.req->silent=1;
(gdb) n
10 char *str = GG_EMPTY_STRING;
(gdb)
17 if (_gg_gstr_once0) {
(gdb)
18 gg_gstr_ret0 = gg_mem_add_const (_gg_gstr0, sizeof(_gg_gstr0)-GG_ALIGN);
(gdb)
19 _gg_gstr_once0 = false;
(gdb)
21 str = gg_gstr_ret0;
(gdb)
22 gg_mem_add_ref (gg_gstr_ret0);
(gdb)
29 if (_gg_gstr_once1) {
(gdb)
30 gg_gstr_ret1 = gg_mem_add_const (_gg_gstr1, sizeof(_gg_gstr1)-GG_ALIGN);
(gdb)
31 _gg_gstr_once1 = false;
(gdb)
33 gg_split_str *pair = NULL;
(gdb)
34 gg_num pair_tot = 0;
(gdb)
35 gg_break_down (str, gg_gstr_ret1, &(pair));
(gdb)
36 pair_tot= (pair)->num_pieces;
(gdb)
39 gg_num pair_count = 0;
(gdb)
Copied!
This is literally the C code that runs your program. It doesn't look as user friendly for sure, but it's useful if you'd like to see what exactly takes place. It's also useful in debugging your program and Golf as well.
Now you know how to debug your Golf programs with gdb.
How to write distributed applications
What is distributed computing
There are many reasons why you might need this kind of setup. It may be that resources needed to complete the task aren't all on a single computer. For instance, your application may rely on multiple databases, each residing on a different computer. Or, you may need to distribute requests to your application because a single computer isn't enough to handle them all at the same time. In other cases, you are using remote services (like a REST API-based for instance), and those by nature reside somewhere else.
In any case, the computers comprising your distributed system may be on a local network, or they may be worldwide, or some combination of those. The throughput (how many bytes per second can be exchanged via network) and latency (how long it takes for a packet to travel via network) will obviously vary: for a local network you'd have a higher throughput and lower latency, and for Internet servers it will be the opposite. Plan accordingly based on the quality of service you'd expect.
Depending on your network(s) setup, different kinds of communication are called for. If two servers reside on a local network, then they would typically used the fastest possible means of communication. A local network typically means a secure network, because nobody else has access to it but you. So you would not need TSL/SSL or any other kind of secure protocol as that would just slow things down.
If two servers are on the Internet though, then you must use a secure protocol (like TSL/SSL or some other) because your communication may be spied on, or worse, affected by man-in-the-middle attacks.
Local network distributed computing
Either way, as far as your application is concerned, you are looking at a local network. Thus, the example here will be for such a case, as it's most likely what you'll have. A local network means different parts of your application residing on different servers will use some efficient protocol based on TCP/IP. One such protocol is FastCGI, a high-performance binary protocol for communication between servers, clients, and in general programs of all kinds, and that's the one used by Golf. So in principle, the setup will look like this (there'll be more details later):
Next, in theory you should have two servers, however in this example both servers will be on the same localhost (i.e. "127.0.0.1"). This is just for simplicity; the code is exactly the same if you have two different servers on a local network - simply use another IP (such as "192.168.0.15" for instance) for your "remote" server instead of local "127.0.0.1". The two servers do not even necessarily need to be physically two different computers. You can start a Virtual Machine (VM) on your computer and host another virtual computer there. Popular free software like VirtualBox or KVM Hypervisor can help you do that.
In any case, in this example you will start two simple application servers; they will communicate with one another. The first one will be called "local" and the other one "remote" server. The local application server will make a request to the remote one.
On a local server, create a new directory for your local application server source code:
mkdir $HOME/local_server
cd $HOME/local_server
Copied!
and then create a new file "status.golf" with the following:
begin-handler /status public
silent-header
get-param server
get-param days
print-format "/server/remote-status/days=%s", days to payload
print-format "%s:3800", server to srv_location
new-remote srv location srv_location \
method "GET" url-path payload \
timeout 30
call-remote srv
read-remote srv data dt
@Output is: [<<print-out dt>>]
end-handler
Copied!
The code here is very simple. new-remote will create a new connection to a remote server, running on IP address given by input parameter "server" (and obtained with get-param) on TCP port 3800. URL payload created in string variable "payload" is passed to the remote server. If it doesn't reply in 30 seconds, then the code would timeout. Then you're using call-remote to actually make a call to the remote server (which is served by application "server" and by request handler "remote-status.golf" below), and finally read-remote to get the reply from it. For simplicity, error handling is omitted here, but you can easily detect a timeout, any network errors, any errors from the remote server, including error code and error text, etc. See the above statements for more on this.
Make and start the local server
gg -k client
Copied!
Make the application (i.e. compile the source code and build the native executable):
gg -q
Copied!
Finally, start the local application server:
mgrg -w 2 client
Copied!
This will start 2 server instances of a local application server.
Okay, now you have a local server. Next, you'll setup a remote server. Login to your remote server and create a new directory for your remote application server:
mkdir $HOME/remote_server
cd $HOME/remote_server
Copied!
Then create file "remote-status.golf" with this code:
begin-handler /remote-status public
silent-header
get-param days
print-format "Status in the past %s days is okay", days
end-handler
Copied!
This is super simple, and it just replies that the status is okay; it accepts the number of days to check for status and displays that back. In a real service, you might query a database to check for status (see run-query).
Make and start remote server
gg -k server
Copied!
Then make your program:
gg -q
Copied!
And finally start the server:
mgrg -w 2 -p 3800 server
Copied!
This will start 2 daemon processes running as background servers. They will serve requests from your local server.
Note that if you're running this example on different computers, some Linux distributions come with a firewall, and you may need to use ufw or firewall-cmd to make port 3800 accessible here.
There is a number of ways you can call the remote service you created. These are calls made from your local server, so change directory to it:
cd $HOME/local_server
Copied!
Here's various way to call the remote application server:
- Execute a command-line program on local server that calls remote application server:
To do this, use "-r" option of gg utility to generate shell commands you can use to call your program:
gg -r --req "/status/days=18/server=127.0.0.1" --exec
Copied!
Here, you're saying that you want to make a request "status" (which is in source file "status.golf" on your local server). You are also saying that input parameter "days" should have a value of "18" and also that input parameter "server" should have a value of "127.0.0.1" - see get-param statements in the above file "status.golf". If you actually have a different server with a different IP, use it instead of "127.0.0.1".
The result will be:
Output is: [Status in the past 18 days is okay]
Copied!
where the part in between "[..]" comes from the remote server, and the "Output is: " part comes from the command line Golf program you executed.
- Call remote application server directly from a command-line program:
Do this:
gg -r --req="/remote-status/days=18" --exec --service --app="/server" --remote="127.0.0.1:3800"
Copied!
The result is, as expected:
Status in the past 18 days is okay
Copied!
In this case, the output comes straight from the remote server, so the "Output is: " part is missing. The above simply copies the output from a remote service to the standard output.
- Use a command-line utility to contact local application server, which then calls the remote server, which replies back to local application server, which replies back to your command-line utility:
You will use gg to do this:
gg -r --req "/status/server=127.0.0.1/days=10" --exec --service
Copied!
The result is:
Output is: [Status in the past 10 days is okay]
Copied!
which is what you'd expect. In this case we first send a request to your local application server, which sends it to a remote service, so there is "Output is: " output.
You have different options when designing your distributed systems, and this article shows how easy it is to implement them.

Encryption: ciphers, digests, salt, IV and a hands-on guide
Encryption is a method of turning data into an unusable form that can be made useful only by means of decryption. The purpose is to make data available solely to those who can decrypt it (i.e. make it usable). Typically, data needs to be encrypted to make sure it cannot be obtained in case of unauthorized access. It is the last line of defense after an attacker has managed to break through authorization systems and access control.
This doesn't mean all data needs to be encrypted, because often times authorization and access systems may be enough, and in addition, there is a performance penalty for encrypting and decrypting data. If and when the data gets encrypted is a matter of application planning and risk assessment, and sometimes it is also a regulatory requirement, such as with HIPAA or GDPR.
Data can be encrypted at-rest, such as on disk, or in transit, such as between two parties communicating over the Internet.
Here you will learn how to encrypt and decrypt data using a password, also known as symmetrical encryption. This password must be known to both parties exchanging information.
Cipher, digest, salt, iterations, IV
A cipher is the algorithm used for encryption. For example, AES256 is a cipher. The idea of a cipher is what most people will think of when it comes to encryption.
A digest is basically a hash function that is used to scramble and lengthen the password (i.e. the encryption key) before it's used by the cipher. Why is this done? For one, it creates a well randomized, uniform-length hash of a key that works better for encryption. It's also very suitable for "salting", which is the next one to talk about.
The "salt" is a method of defeating so-called "rainbow" tables. An attacker knows that two hashed values will still look exactly the same if the originals were. However, if you add the salt value to hashing, then they won't. It's called "salt" because it's sort of mixed with the key to produce something different. Now, a rainbow table will attempt to match known hashed values with precomputed data in an effort to guess a password. Usually, salt is randomly generated for each key and stored with it. In order to match known hashes, the attacker would have to precompute rainbow tables for great many random values, which is generally not feasible.
You will often hear about "iterations" in encryption. An iteration is a single cycle in which a key and salt are mixed in such a way to make guessing the key harder. This is done many times so to make it computationally difficult for an attacker to reverse-guess the key, hence "iterations" (plural). Typically, a minimum required number of iterations is 1000, but it can be different than that. If you start with a really strong password, generally you need less.
IV (or "Initialization Vector") is typically a random value that's used for encryption of each message. Now, salt is used for producing a key based on a password. And IV is used when you already have a key and now are encrypting messages. The purpose of IV is to make the same messages appear differently when encrypted. Sometimes, IV also has a sequential component, so it's made of a random string plus a sequence that constantly increases. This makes "replay" attacks difficult, which is where attacker doesn't need to decrypt a message; but rather an encrypted message was "sniffed" (i.e. intercepted between the sender and receiver) and then replayed, hoping to repeat the action already performed. Though in reality, most high-level protocols already have a sequence in place, where each message has, as a part of it, an increasing packet number, so in most cases IV doesn't need it.
To run the examples here, create an application "enc" in a directory of its own (see mgrg for more on Golf's program manager):
mkdir enc_example
cd enc_example
gg -k enc
Copied!
To encrypt data use encrypt-data statement. The simplest form is to encrypt a null-terminated string. Create a file "encrypt.golf" and copy this:
begin-handler /encrypt public
set-string str = "This contains a secret code, which is Open Sesame!"
encrypt-data str to enc_str password "my_password"
print-out enc_str
@
decrypt-data enc_str password "my_password" to dec_str
print-out dec_str
@
end-handler
Copied!
You can see the basic usage of encrypt-data and decrypt-data. You supply data (original or encrypted), the password, and off you go. The data is encrypted and then decrypted, yielding the original.
In the source code, a string variable "enc_str" (which is created as a "char *") will contain the encrypted version of "This contains a secret code, which is Open Sesame!" and "dec_str" will be the decrypted data which must be exactly the same.
To run this code from command line, make the application first:
gg -q
Copied!
Then have Golf produce the bash code to run it - the request path is "/encrypt", which in our case is handled by function "void encrypt()" defined in source file "encrypt.golf". In Golf, these names always match, making it easy to write, read and execute code. Use "-r" option in gg to specify the request path and get the code you need to run the program:
gg -r --req="/encrypt" --silent-header --exec
Copied!
You will get a response like this:
72ddd44c10e9693be6ac77caabc64e05f809290a109df7cfc57400948cb888cd23c7e98e15bcf21b25ab1337ddc6d02094232111aa20a2d548c08f230b6d56e9
This contains a secret code, which is Open Sesame!
Copied!
What you have here is the encrypted data, and then this encrypted data is decrypted using the same password. Unsurprisingly, the result matches the string you encrypted in the first place.
Note that by default encrypt-data will produce encrypted value in a human-readable hexadecimal form, which means consisting of hexadecimal characters "0" to "9" and "a" to "f". This way you can store the encrypted data into a regular string. For instance it may go to a JSON document or into a VARCHAR column in a database, or pretty much anywhere else. However you can also produce a binary encrypted data. More on that in a bit.
Encrypt data into a binary result
begin-handler /encrypt public
set-string str = "This contains a secret code, which is Open Sesame!"
encrypt-data str to enc_str password "my_password" binary
write-file "encrypted_data" from enc_str
get-app directory to app_dir
@Encrypted data written to file <<print-out app_dir>>/encrypted_data
decrypt-data enc_str password "my_password" binary to dec_str
print-out dec_str
@
end-handler
Copied!
When you want to get binary encrypted data, you should get its length in bytes too, or otherwise you won't know where it ends, since it may contain null bytes in it. Use "output-length" clause for that purpose. In this code, the encrypted data in variable "enc_str" is written to file "encrypted_data", and the length written is "outlen" bytes. When a file is written without a path, it's always written in the application home directory (see directories), so you'd use get-app to get that directory.
When decrypting data, notice the use of "input-length" clause. It says how many bytes the encrypted data has. Obviously you can get that from "outlen" variable, where encrypt-data stored the length of encrypted data. When encryption and decryption are decoupled, i.e. running in separate programs, you'd make sure this length is made available.
Notice also that when data is encrypted as "binary" (meaning producing a binary output), the decryption must use the same.
Make the application:
gg -q
Copied!
Run it the same as before:
gg -r --req="/encrypt" --silent-header --exec
Copied!
The result is:
Encrypted data written to file ~/.golf/apps/enc/app/encrypted_data
This contains a secret code, which is Open Sesame!
Copied!
The decrypted data is exactly the same as the original.
You can see the actual encrypted data written to the file by using "octal dump" ("od") Linux utility:
od -c ~/.golf/apps/enc/app/encrypted_data
Copied!
with the result like:
$ od -c ~/.golf/apps/enc/app/encrypted_data
0000000 r 335 324 L 020 351 i ; 346 254 w 312 253 306 N 005
0000020 370 \t ) \n 020 235 367 317 305 t \0 224 214 270 210 315
0000040 # 307 351 216 025 274 362 033 % 253 023 7 335 306 320
0000060 224 # ! 021 252 242 325 H 300 217 # \v m V 351
0000100
Copied!
There you have it. You will notice the data is binary and it actually contains the null byte(s).
The data to encrypt in these examples is a string, i.e. null-delimited. You can encrypt binary data just as easily by specifying it whole (since Golf keeps track of how many bytes are there!), or specifying its length in "input-length" clause, for example copy this to "encrypt.golf":
begin-handler /encrypt public
set-string str = "This c\000ontains a secret code, which is Open Sesame!"
encrypt-data str to enc_str password "my_password" input-length 12
print-out enc_str
@
decrypt-data enc_str password "my_password" to dec_str
string-length dec_str to res_len
start-loop repeat res_len use i start-with 0
if-true dec_str[i] equal 0
print-out "\\000"
else-if
print-format "%c", dec_str[i]
end-if
end-loop
@
end-handler
Copied!
This will encrypt 12 bytes at memory location "enc_str" regardless of any null bytes. In this case that's "This c" followed by a null byte followed by "ontain" string, but it can be any kind of binary data, for example the contents of a JPG file.
On the decrypt side, you'd obtain the number of bytes decrypted in "output-length" clause. Finally, the decrypted data is shown to be exactly the original and the null byte is presented in a typical octal representation.
Make the application:
gg -q
Copied!
Run it the same as before:
gg -r --req="/encrypt" --silent-header --exec
Copied!
The result is:
6bea45c2f901c0913c87fccb9b347d0a
This c\000ontai
Copied!
The encrypted value is shorter because the data is shorter in this case too, and the result matches exactly the original.
The encryption used by default is AES256 and SHA256 hashing from the standard OpenSSL library, both of which are widely used in cryptography. You can however use any available cipher and digest (i.e. hash) that is supported by OpenSSL (even the custom ones you provide).
To see which algorithms are available, do this in command line:
openssl list -cipher-algorithms
openssl list -digest-algorithms
Copied!
These two will provide a list of cipher and digest (hash) algorithms. Some of them may be weaker than the default ones chosen by Golf, and others may be there just for backward compatibility with older systems. Yet others may be quite new and did not have enough time to be validated to the extent you may want them to be. So be careful when choosing these algorithms and be sure to know why you're changing the default ones. That said, here's an example of using Camellia-256 (i.e. "CAMELLIA-256-CFB1") encryption with "SHA3-512" digest. Replace the code in "encrypt.golf" with:
begin-handler /encrypt public
set-string str = "This contains a secret code, which is Open Sesame!"
encrypt-data str to enc_str password "my_password" \
cipher "CAMELLIA-256-CFB1" digest "SHA3-512"
print-out enc_str
@
decrypt-data enc_str password "my_password" to dec_str \
cipher "CAMELLIA-256-CFB1" digest "SHA3-512"
print-out dec_str
@
end-handler
Copied!
Make the application:
gg -q
Copied!
Run it:
gg -r --req="/encrypt" --silent-header --exec
Copied!
In this case the result is:
f4d64d920756f7220516567727cef2c47443973de03449915d50a1d2e5e8558e7e06914532a0b0bf13842f67f0a268c98da6
This contains a secret code, which is Open Sesame!
Copied!
Again, you get the original data. Note you have to use the same cipher and digest in both encrypt-data and decrypt-data!
You can of course produce the binary encrypted value just like before by using "binary" and "output-length" clauses.
If you've got external systems that encrypt data, and you know which cipher and digest they use, you can match those and make your code interoperable. Golf uses standard OpenSSL library so chances are that other software may too.
To add a salt to encryption, use "salt" clause. You can generate random salt by using random-string statement (or random-crypto if there is a need). Here is the code for "encrypt.golf":
begin-handler /encrypt public
set-string str = "This contains a secret code, which is Open Sesame!"
random-string to rs length 16
encrypt-data str to enc_str password "my_password" salt rs
@Salt used is <<print-out rs>>, and the encrypted string is <<print-out enc_str>>
decrypt-data enc_str password "my_password" salt rs to dec_str
print-out dec_str
@
end-handler
Copied!
Make the application:
gg -q
Copied!
Run it a few times:
gg -r --req="/encrypt" --silent-header --exec
gg -r --req="/encrypt" --silent-header --exec
gg -r --req="/encrypt" --silent-header --exec
Copied!
The result:
Salt used is VA9agPKxL9hf3bMd, and the encrypted string is 3272aa49c9b10cb2edf5d8a5e23803a5aa153c1b124296d318e3b3ad22bc911d1c0889d195d800c2bd92153ef7688e8d1cd368dbca3c5250d456f05c81ce0fdd
This contains a secret code, which is Open Sesame!
Salt used is FeWcGkBO5hQ1uo1A, and the encrypted string is 48b97314c1bc88952c798dfde7a416180dda6b00361217ea25278791c43b34f9c2e31cab6d9f4f28eea59baa70aadb4e8f1ed0709db81dff19f24cb7677c7371
This contains a secret code, which is Open Sesame!
Salt used is nCQClR0NMjdetTEf, and the encrypted string is f19cdd9c1ddec487157ac727b2c8d0cdeb728a4ecaf838ca8585e279447bcdce83f7f95fa53b054775be1bb2de3b95f2e66a8b26b216ea18aa8b47f3d177e917
This contains a secret code, which is Open Sesame!
Copied!
As you can see, a random salt value (16 bytes long in this case) is generated for each encryption, and the encrypted value is different each time, even though the data being encrypted was the same! This makes it difficult to crack encryption like this.
Of course, to decrypt, you must record the salt and use it exactly as you did when encrypting. In the code here, variable "rs" holds the salt. If you store the encrypted values in the database, you'd likely store the salt right next to it.
In practice, you wouldn't use a different salt value for each message. It creates a new key every time, and that can reduce performance. And there's really no need for it: the use of salt is to make each key (even the same ones) much harder to guess. Once you've done that, you might not need to do it again, or often.
Instead, you'd use an IV (Initialization Vector) for each message. It's usually a random string that makes same messages appear different, and increases the computational cost of cracking the password. Here is the new code for "encrypt.golf":
begin-handler /encrypt public
random-string to rs length 16
start-loop repeat 10
random-string to iv length 16
encrypt-data "The same message" to enc_str password "my_password" salt rs iterations 2000 init-vector iv cache
@The encrypted string is <<print-out enc_str>>
decrypt-data enc_str password "my_password" salt rs iterations 2000 init-vector iv to dec_str cache
print-out dec_str
@
end-loop
end-handler
Copied!
Make the application:
gg -q
Copied!
Run it a few times:
gg -r --req="/encrypt" --silent-header --exec
gg -r --req="/encrypt" --silent-header --exec
gg -r --req="/encrypt" --silent-header --exec
Copied!
The result may be:
The encrypted string is 787909d332fd84ba939c594e24c421b00ba46d9c9a776c47d3d0a9ca6fccb1a2
The same message
The encrypted string is 7fae887e3ae469b666cff79a68270ea3d11b771dc58a299971d5b49a1f7db1be
The same message
The encrypted string is 59f95c3e4457d89f611c4f8bd53dd5fa9f8c3bbe748ed7d5aeb939ad633199d7
The same message
The encrypted string is 00f218d0bbe7b618a0c2970da0b09e043a47798004502b76bc4a3f6afc626056
The same message
The encrypted string is 6819349496b9f573743f5ef65e27ac26f0d64574d39227cc4e85e517f108a5dd
The same message
The encrypted string is a2833338cf636602881377a024c974906caa16d1f7c47c78d9efdff128918d58
The same message
The encrypted string is 04c914cd9338fcba9acb550a79188bebbbb134c34441dfd540473dd8a1e6be40
The same message
The encrypted string is 05f0d51561d59edf05befd9fad243e0737e4a98af357a9764cba84bcc55cf4d5
The same message
The encrypted string is ae594c4d6e72c05c186383e63c89d93880c8a8a085bf9367bdfd772e3c163458
The same message
The encrypted string is 2b28cdf5a67a5a036139fd410112735aa96bc341a170dafb56818dc78efe2e00
The same message
Copied!
You can see that the same message appears different when encrypted, though when decrypted it's again the same. Of course, the password, salt, number of iterations, and init-vector must be the same for both encryption and decryption.
Note the use of "cache" clause in encrypt-data and decrypt-data. It effectively caches the computed key (given password, salt, cipher/digest algorithms and number of iterations), so it's not computed each time through the loop. With "cache" the key is computed once, and then a different IV (in "init-vector" clause) is used for each message.
If you want to occasionally rebuild the key, use "clear-cache" clause, which supplies a boolean. If true, the key is recomputed, otherwise it's left alone. See encrypt-data for more on this.
You have learned how to encrypt and decrypt data using different ciphers, digests, salt and IV values in Golf. You can also create a human-readable encrypted value and a binary output, as well as encrypt both strings and binary values (like documents).
How to get the web page source code programmatically
Fetching a web resource (including web page source) is a one-liner in Golf. First, create a new application ("get-page" here):
mkdir get-page
cd get-page
gg -k get-page
Copied!
Edit our sole Golf file (I use vi, but you can use anything):
vi fetch.golf
Copied!
Copy and paste this - it's rather obvious what it does (it gets Google home page HTTP headers and web page source code, and it prints it out):
begin-handler /fetch public
call-web "https://google.com" response text response-headers head
print-out head new-line
print-out text new-line
end-handler
Copied!
Build your application (it makes a native executable):
gg -q
Copied!
Run it (since we run it in command line, skip the HTTP response header, which would normally be sent to a web client):
gg -r --req="/fetch" --exec --silent-header
Copied!
The result is something like this (I used ... for the remainder of the header and the web page, as they are rather long):
HTTP/2 200
date: Sun, 17 Aug 2025 19:03:40 GMT
expires: -1
cache-control: private, max-age=0
content-type: text/html; charset=ISO-8859-1
...
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta content="Search the world's information, including webpages, images, video
s and more. Google has many special features to help you find exactly what you're looking for." name="description"><meta content= ...
Copied!
There you have it. Web programming is easy with Golf.
First In First Out (FIFO) example
Golf has built-in FIFO list type. You can create a FIFO variable and then store key/value string pairs in it, which you can then read back in the order you put them in. You can also rewind the FIFO list and obtain the same key/value pairs over and over again if needed.
This is an example of FIFO list usage. This small command-line application will store key/value pairs "key1"/"value1" and "key2"/"value2" and then obtain them twice.
First, let's create a directory for our application:
mkdir test-list
cd test-list/
Copied!
And then create the application itself:
gg -k list-app
Copied!
Copy and paste the Golf code below to file "list.golf":
begin-handler /list
silent-header
new-fifo mylist
write-fifo mylist key "key1" value "value1"
write-fifo mylist key "key2" value "value2"
start-loop
read-fifo mylist key k value v status st
if-true st not-equal GG_OKAY
break-loop
end-if
@Obtained key <<print-out k>> with value <<print-out v>>
end-loop
rewind-fifo mylist
start-loop
read-fifo mylist key k value v status st
if-true st not-equal GG_OKAY
break-loop
end-if
@Again obtained key <<print-out k>> with value <<print-out v>>
end-loop
purge-fifo mylist
end-handler
Copied!
The code above uses new-fifo statement to create a FIFO variable, write-fifo to add key/value pairs to it, and read-fifo to obtain them back in the order they were put in. You can use rewind-fifo to rewind back to the beginning at any time, as many times as you need.
Make the executable:
gg -q --public
Copied!
Execute the program:
gg -r --req="/list" --app="/list-app" --exec
Copied!
The result is as expected:
Obtained key key1 with value value1
Obtained key key2 with value value2
Again obtained key key1 with value value1
Again obtained key key2 with value value2
Copied!
Web file manager in less than 100 lines of code
Uploading and download files in web browser is a common task in virtually any web application or service. This article shows how to do this with very little coding - in less than 100 lines of code. The database used is PostgreSQL, and the web server is Nginx.
You will use Golf as an application server and the programming language. It will run behind the web server. This way end-user cannot talk to your application server directly because all such requests go through the web server, while your back-end application can talk directly to your application server for better performance.
Assuming your currently logged-on Linux user will own the application, create a source code directory and also create Golf application named "file-manager":
mkdir filemgr
cd filemgr
gg -k file-manager
Copied!
Next, create PostgreSQL database named "db_file_manager", owned by currently logged-on user (i.e. passwordless setup):
echo "create user $(whoami);
create database db_file_manager with owner=$(whoami);
grant all on database db_file_manager to $(whoami);
\q" | sudo -u postgres psql
Copied!
Create database configuration file used by Golf that describes the database (it's a file "db"):
echo "user=$(whoami) dbname=db_file_manager" > db
Copied!
Create SQL table that will hold files currently stored on the server:
echo "create table if not exists files (fileName varchar(100), localPath varchar(300), extension varchar(10), description varchar(200), fileSize int, fileID bigserial primary key);" | psql -d db_file_manager
Copied!
Finally, create source Golf files. First create "start.golf" file and copy and paste:
begin-handler /start public
@<h2>File Manager</h2>
@To manage the uploaded files, <a href="<<print-path "/list">>">click here.</a><br/>
@<br/>
@<form action="<<print-path "/upload">>" method="POST" enctype="multipart/form-data">
@ <label for="file_description">File description:</label><br>
@ <textarea name="filedesc" rows="3" columns="50"></textarea><br/>
@ <br/>
@ <label for="filename">File:</label>
@ <input type="file" name="file" value=""><br><br>
@ <input type="submit" value="Submit">
@</form>
end-handler
Copied!
Create "list.golf" file and copy and paste:
begin-handler /list public
@<h2>List of files</h2>
@To add a file, <a href="<<print-path "/start">>">click here</a><br/><br/>
@<table border="1">
@<tr>
@ <td>File</td><td>Description</td><td>Size</td><td>Show</td><td>Delete</td>
@</tr>
run-query @db= \
"select fileName, description, fileSize, fileID from files order by fileSize desc" \
output file_name, description noencode, file_size, file_ID
@<tr>
@ <td><<print-out file_name web-encode>></td><td><<print-out description web-encode>><td><<print-out file_size web-encode>></td>
@ <td><a href="<<print-path "/download">>/file_id=<<print-out file_ID url-encode>>">Show</a></td>
@ <td><a href="<<print-path "/delete">>/action=confirm/file_id=<<print-out file_ID url-encode>>">Delete</a></td>
@</tr>
end-query
@</table>
end-handler
Copied!
Create "upload.golf" file and copy and paste:
begin-handler /upload public
get-param filedesc
get-upload file local-file file_location size file_size \
extension file_ext client-file file_filename
@<h2>Uploading file</h2>
run-query @db= \
"insert into files (fileName, localPath, extension, description, fileSize) \
values ('%s', '%s', '%s', '%s', '%s')" \
input file_filename, file_location, file_ext, filedesc, $file_size
end-query
@File <<print-out file_filename web-encode>> of size <<print-out file_size >> \
is stored on server at <<print-out file_location web-encode>>. \
File description is <<print-out filedesc web-encode>>.<hr/>
end-handler
Copied!
Create "download.golf" file and copy and paste:
begin-handler /download public
get-param file_id
run-query @db= \
"select localPath,extension from files where fileID='%s'" \
input file_id \
output local_path, ext \
row-count num_files
if-true ext equal ".jpg"
send-file local_path headers content-type "image/jpg"
else-if ext equal ".png"
send-file local_path headers content-type "image/png"
else-if ext equal ".pdf"
send-file local_path headers content-type "application/pdf"
else-if
send-file local_path headers content-type "application/octet-stream" download
end-if
end-query
if-true num_files not-equal 1
@Cannot find this file!<hr/>
exit-handler
end-if
end-handler
Copied!
Create "delete.golf" file and copy and paste:
begin-handler /delete public
@<h2>Delete a file</h2>
get-param action
get-param file_id
run-query @db="select fileName, localPath, description from files where fileID='%s'" output file_name, local_path, desc input file_id
if-true action equal "confirm"
@Are you sure you want to delete file <<print-out file_name web-encode>> (<<print-out desc web-encode>>)? Click <a href="<<print-path "/delete">>?action=delete&file_id=<<print-out file_id url-encode>>">Delete</a> or click the browser's Back button to go back.<br/>
else-if action equal "delete"
begin-transaction @db
run-query @db= "delete from files where fileID='%s'" input file_id error err no-loop
if-true err not-equal "0"
@Could not delete the file (error <<print-out err web-encode>>)
rollback-transaction @db
else-if
delete-file local_path status st
if-true st equal GG_OKAY
commit-transaction @db
@File deleted. Go back to <a href="<<print-path "/start">>">start page</a>
else-if
rollback-transaction @db
@File could not be deleted, error <<print-out st>>
end-if
end-if
else-if
@Unrecognized action <<print-out action web-encode>>
end-if
end-query
end-handler
Copied!
Make the application:
gg -q --db=postgres:db
Copied!
Run your application server:
mgrg file-manager
Copied!
A web server sits in front of Golf application server, so it needs to be setup. This example is for Ubuntu, so edit Nginx config file there:
sudo vi /etc/nginx/sites-enabled/default
Copied!
Add this in "server {}" section ("client_max_body_size" allows for images of typical sizes to be uploaded), replace "your-user" with the name of your OS user:
location /file-manager/ { include /etc/nginx/fastcgi_params; fastcgi_pass unix:///home/your-user/.golf/apps/file-manager/sock/.sock; }
client_max_body_size 100M;
Copied!
Restart Nginx:
sudo systemctl restart nginx
Copied!
Go to your web browser, and enter:
http://127.0.0.1/file-manager/start
Copied!
This is what the end result looks like. Obviously, we used just bare-bone HTML, but that's not the point here at all. You can use any kind of front-end technology, the point is to demonstrate Golf as a back-end server for web applications/services.
Here's the home screen, with the form to upload a file and a link to list of files:
Listing files:
Asking to delete a file:
Confirmation of deletion:
34000 requests per second on a modest laptop
Here's a video showing how to create and start an application server, and how to connect to it and make requests from a C client (or from any language that supports C API extension), you can watch a video here.
Create new directory for the Golf server and also for C API client:
mkdir -p srv-example
cd srv-example
mkdir -p client
Copied!
Create file "srv.golf" and copy this:
begin-handler /srv public
silent-header
@Hello world!
end-handler
Copied!
Create Golf application server:
gg -k hello
Copied!
Build Golf application server (exclude client directory as it contains C API client):
gg -q --exclude-dir=client
Copied!
Start the application server (a single-process server in this case):
mgrg -w 1 hello
Copied!
Next, go to C API client directory:
cd client
Copied!
Then create C file "cli.c" and copy this:
#include "gcli.h"
int golf_client (gg_cli *req, char *connection, char *method, char *app_path, char *request, char *url_params);
int golf_client (gg_cli *req, char *connection, char *method, char *app_path, char *request, char *url_params)
{
memset ((char*)req, 0, sizeof(gg_cli));
req->server = connection;
req->req_method = method;
req->app_path = app_path;
req->req = request;
req->url_params = url_params;
return gg_cli_request (req);
}
void main ()
{
int i;
char dir[GG_MAX_OS_UDIR_LEN];
gg_dir (GG_DIR_SOCKFILE, dir, sizeof(dir), "hello", NULL);
for (i = 0; i < 100000; i++)
{
gg_cli req;
int res = golf_client (&req, dir, "GET", "/hello", "/srv", "/");
if (res != GG_OKAY) printf("Request failed [%d] [%s]\n", res, req.errm);
else printf("%s", gg_cli_data(&req));
gg_cli_delete(&req);
}
}
Copied!
Compile the client:
gcc -o cli cli.c $(gg -i) -O3
Copied!
Run it:
./cli
Copied!
The result is "Hello world!" 100,000 times from each request invocation.
Hello World in Golf
Create a directory for your Hello World application and then switch to it:
mkdir hello-world
cd hello-world
Copied!
Create the application:
mgrg -i -u $(whoami) hello
Copied!
Create a file hello-world.golf:
vim hello-world.golf
Copied!
and copy this code to it:
begin-handler /hello-world public
get-param name
@This is Hello World from <<print-out name>>
end-handler
Copied!
This service takes input parameter "name" (see get-param), and then outputs it along with a greeting message (see output-statement).
Compile the application:
gg -q
Copied!
Run the application by executing this service from command line. Note passing the input parameter "name" with value "Mike":
gg -r --req="/hello-world/name=Mike" --exec --silent-header
Copied!
The output is:
This is Hello World from Mike
Copied!
Hello World as a Service
Writing a service is the same as writing a command-line program in Golf. Both take the same input and produce the same output, so you can test with either one to begin with.
For that reason, create first article-hello-world as a command-line program.
The only thing to do afterwards is to start up Hello World as application server:
mgrg hello
Copied!
Now there's a number of resident processes running, expecting clients requests. You can see those processes:
ps -ef|grep hello
Copied!
The result:
bear 25772 2311 0 13:04 ? 00:00:00 mgrg hello
bear 25773 25772 0 13:04 ? 00:00:00 /var/lib/gg/bld/hello/hello.srvc
bear 25774 25772 0 13:04 ? 00:00:00 /var/lib/gg/bld/hello/hello.srvc
bear 25775 25772 0 13:04 ? 00:00:00 /var/lib/gg/bld/hello/hello.srvc
bear 25776 25772 0 13:04 ? 00:00:00 /var/lib/gg/bld/hello/hello.srvc
bear 25777 25772 0 13:04 ? 00:00:00 /var/lib/gg/bld/hello/hello.srvc
Copied!
"mgrg hello" runs the Golf process manager for application "hello". A number of ".../hello.srvc" processes are server processes that will handle service request sent to application "hello".
Now, to test your service, you can send a request to the server from command line (by using "--service" option):
gg -r --req="/hello-world/name=Mike" --exec --silent-header --service
Copied!
The above will make a request to one of the processes above, which will then reply:
This is Hello World from Mike
Copied!
Web service Hello World
To access a Golf service on the web, you need to have a web server or load balancer (think Apache, Nginx, HAProxy etc.).
This assumes you have completed the article-hello-world-service, with a service built and tested via command line.
In this example, Nginx web server is used; edit its configuration file. For Ubuntu and similar:
sudo vi /etc/nginx/sites-enabled/default
Copied!
while on Fedora and other systems it might be:
sudo vi /etc/nginx/nginx.conf
Copied!
Add the following in the "server {}" section:
location /hello/ { include /etc/nginx/fastcgi_params; fastcgi_pass unix:///home/your-user/.golf/apps/hello/sock/.sock; }
Copied!
"hello" refers to your Hello World application. Finally, restart Nginx:
sudo systemctl restart nginx
Copied!
Now you can call your web service, from the web. In this case it's probably a local server (127.0.0.1) if you're doing this on your own computer. The URL would be:
http://127.0.0.1/hello/hello-world/name=Mike
Copied!
Note the URL request structure: first comes the application path ("/hello") followed by request path ("/hello-world") followed by URL parameters ("/name=Mike"). The result:
How to create a Golf application
To create a Golf application, use "-k" option of gg utility:
gg -k my-app
Copied!
where "my-app" is your application name. If you already have an application with that name, nothing is done, so this is an idempotent operation.
If you already have source code, you can create and compile your application in one step:
gg -k my-app -q
Copied!
which is a neat shortcut.
Fast JSON parser with little coding
Golf's JSON parser produces an array of name/value pairs. A name is a path to value, for instance "country"."state"."name", and the value is simply the data associated with it, for instance "Idaho". You can control if the name contains array indexes or not, for instance if there are multiple States in the document, you might have names like "country"."state"[0]."name" with [..] designating an array element.
You can iterate through this array and get names of JSON elements, examine if they are of interest to you, and if so, get the values. This typical scenario is how Golf's parser is built, since it uses a "lazy" approach, where values are not allocated until needed, speeding up parsing. That is the case in this example. The JSON document below is examined and only the names of the cities are extracted.
You can also store JSON elements into trees or hashes for future fast retrieval, or store them into a database, etc.
To get started, create a directory for this example and position in it:
mkdir -p json
cd json
Copied!
Save this JSON into a file "countries.json" - we will get the names of the cities from it:
{ "country": [
{
"name": "USA",
"state": [
{
"name": "Arizona",
"city": [
{
"name" : "Phoenix",
"population": 5000000
} ,
{
"name" : "Tuscon",
"population": 1000000
}
]
} ,
{
"name": "California",
"city": [
{
"name" : "Los Angeles",
"population": 19000000
},
{
"name" : "Irvine"
}
]
}
]
} ,
{
"name": "Mexico",
"state": [
{
"name": "Veracruz",
"city": [
{
"name" : "Xalapa-Enr\u00edquez",
"population": 8000000
},
{
"name" : "C\u00F3rdoba",
"population": 220000
}
]
} ,
{
"name": "Sinaloa",
"city": [
{
"name" : "Culiac\u00E1n Rosales",
"population": 3000000
}
]
}
]
}
]
}
Copied!
What follows is the code to parse JSON. We open a JSON file, process the document, check for errors, and then read elements one by one. We look for a key "country"."state"."city"."name" because those contains city names. Note use "no-enum" clause in json-doc (which is the Golf's JSON parser), so that element designations aren't showing (meaning we don't have [0], [1] etc. for arrays).
Save this code to "parse-json.golf":
begin-handler /parse-json public
read-file "countries.json" to countries status st
if-true st lesser-equal 0
@Cannot read file or file empty
exit-handler -1
end-if
json-doc countries no-enum status st error-text et error-position ep to json
if-true st not-equal GG_OKAY
@Error [<<print-out et>>] at [<<print-out ep>>]
exit-handler -2
end-if
set-string city_name unquoted ="country"."state"."city"."name"
start-loop
read-json json key k type t
if-true t equal GG_JSON_TYPE_NONE
break-loop
end-if
if-true city_name equal k
read-json json value v
@Value [<<print-out v>>]
@--------
end-if
read-json json next
end-loop
json-doc delete json
end-handler
Copied!
Create "json" application ("-k") and compile it ("-q"):
gg -k json -q
Copied!
Copy the above JSON file into application home directory so we can use it without a path (since this directory is your program's default directory) - you can, of course, also specify any absolute or relative path in Golf code above:
cp countries.json ~/.golf/apps/json/app
Copied!
Run it:
gg -r --req="/parse-json" --exec
Copied!
The result is:
Content-Type: text/html;charset=utf-8
Cache-Control: max-age=0, no-cache
Pragma: no-cache
Status: 200 OK
Value [Phoenix]
--------
Value [Tuscon]
--------
Value [Los Angeles]
--------
Value [Irvine]
--------
Value [Xalapa-Enríquez]
--------
Value [Córdoba]
--------
Value [Culiacán Rosales]
Copied!
Golf programs work exactly the same when you run them from command line as they do as web services or applications, hence you get the HTTP header in the output. You can avoid it by using silent-header in your Golf code, or by using "--silent-header" option in the above gg execution call.
You can also omit "--exec" option in the above gg execution call, which will display environment variable settings and the path to your executable. Then you can run those directly. This is useful if you're running a Golf command line program in batch mode from command line repeatedly, as it's faster than using gg.
Golf is a different kind of programming language
Over the past 50 years, general-purpose programming languages became more complex due to the constant influx of new features (some of which are great, while others are a "feature creep"). Just look at any major programming language in its early days, versus the latest incarnations. From a distance, it may look like you switched from riding a bicycle to flying a passenger jet with a few hundred knobs, buttons and readout consoles. Arguably, the language structure covers many more usage patterns, yields additional power and safety has improved, but the complexity and the learning curve has increased too. While in the beginning there was lots of pitfalls due to the lack of features and safety, which would usually result in too many ways of doing the same thing, in the end there's a minefield due to an overcrowded feature-scape that's paralyzing to deal with and often not quite understood by anyone on the team.
If you look at a moderately involved application written in any major programming language these days, you can intuitively experience this without any need for a formal explanation. This is true especially if you are not familiar with the language involved. The level of "cryptic" in programming languages has gone up notches.
When writing software, useful complexity helps by providing structure as well as the shortest path to actualizing an algorithm. "Useful" complexity stands in contrast to complexity that doesn't yield enough benefits to justify itself. Typically, it's the ability to quickly make workable programs, the power of its constructs, memory safety, performance etc. Often a given benefit compromises another, i.e. you "can't have it all". This is where the perceived benefits become more personal and vary based on where exactly the emphasis is.
Regardless, programming languages tend to favor primitives that, when combined in a clever manner, yield higher-level function, until ultimately such function becomes business or consumer friendly. The process has been this way for over 50 years. Despite a plethora of languages out there, nothing has changed much. The basic blocks of languages remain primitives, and the building of applications from ground up remains the norm, rarely directly, and more by means of libraries building functionality on top of libraries.
The reason for how all this developed in this manner (and why) would be a good topic for a study, and not just of programming languages but indeed first and foremost of human nature and the nature of business. On one hand, the original languages evolved in a relatively simple way with the rise of LALR and LR grammar tools, which made building a parser to be a streamlined process. It's a benefit, but also a trap, in a sense that it pigeon-holes the design of a language. Regardless of which parsing tools are used, it's the conceptually the same ball of yarn. This has resulted in a rather large number of languages that are in their basic nature clones of each other.
While the above applies to general-purpose languages, the situation isn't like that in DSL (Domain-Specific Languages). Take for example SQL, or Structured Query Language. It's withstood the test of time with relatively minor changes, and even those that weren't minor came out well enough. Successful DSLs have something that general-purpose languages don't: firstly the power to cross the chasms of building functionality in very little code, and secondly the ease of use later in the development cycle, long after the dust settles. The former refers to typing a single (or very few) statements that take hundreds in other languages. The latter to being able to understand the code years later, or by other people.
Perhaps now is a good time to make a point. It's simple really: Golf intends to converge a general purpose language concept with a Domain-Specific one, or in a nutshell: a language that's general-purpose but with the two aforementioned benefits of DSLs. The process isn't straighforward because it's not just about grammars and BNF notations, or about pure structure. It's about the interaction between the language and a human. It's about reducing the effect of overly-expressioned languages and escaping the trap of cookie-cutter churning of languages.
Aside from grabbing the benefits of both, there's an additional, emerging one: some things that were "either/or" can now be together at the same time. I am talking about performance. Using memory-safe general-purpose programming languages has a drawback: building "libraries on top of libraries" (or similar, as a method of building up functionality) carries a performance stick: everything written in such a language will exact a performance penalty because the cost of memory safety on every level of development starts to pile up. But if a programming language builds a large number of significant functionalities in just a single or few statements (such as in DSLs), then such functionalities can be built in C, which is the most energy-efficient and fastest programming language, according to this study (and also something that most of us intuitively understand). Building so can be done to include memory safety from the get-go with a much lower impact, and offers lots of customizations at the same time, yet still remain high-performance because it's built entirely in C. And the range of functionalities can be large, including databases, web technologies, regex, strings, files, parsing etc. It can include enough to be useful for building business and consumer applications.
What this implies is that a hybrid between a general-purpose and a set of Domain-Specific language can be simple, memory safe and have high-performance, at the same time. It would emphasise near-expressionless statements that are close to natural way of thinking, instead of one based on mechanical-parsing methods that's easy for a computer. Golf is a hybrid language of that nature. One more benefit is that you may not need AI to summarize what the program does. If a single statement can convey a high-level intent, then you can read a program in such language more as a story of the solution than an algorithm.
Web services with MariaDB
Create a directory for your project, it'll be where this example takes place. Also create Golf application "stock":
mkdir -p stock-app
cd stock-app
mgrg -i -u $(whoami) stock
Copied!
Start MariaDB command line interface:
sudo mysql
Copied!
Create an application user, database and a stock table (with stock name and price):
create user stock_user;
create database stock_db;
grant all privileges on stock_db.* to stock_user@localhost identified by 'stock_pwd';
use stock_db
create table if not exists stock (stock_name varchar(100) primary key, stock_price bigint);
Copied!
Golf wants you to describe the database: the user name and password, database name, and the rest is the default setup for MariaDB database connection. So create a file "db_stock" (which is your database configuration file, one per each you use):
vi db_stock
Copied!
and copy and paste this:
[client]
user=stock_user
password=stock_pwd
database=stock_db
protocol=TCP
host=127.0.0.1
port=3306
Copied!
Now to the code. Here's the web service to insert stock name and price into the stock table - create file "add-stock.golf":
vi add-stock.golf
Copied!
and copy and paste this:
%% /add-stock public
@<html>
@<body>
get-param name
get-param price
run-query @db_stock = "insert into stock (stock_name, stock_price) values ('%s', '%s') on duplicate key update stock_price='%s'" \
input name, price, price error err no-loop
if-true err not-equal "0"
report-error "Cannot update stock price, error [%s]", err
end-if
@<div>
@Stock price updated!
@</div>
@</body>
@</html>
%%
Copied!
Next is the web service to display a web page with all stock names and prices from the stock table - create file "show-stock.golf":
vi show-stock.golf
Copied!
and copy and paste this:
%% /show-stock public
@<html>
@<body>
@<table>
@<tr>
@<td>Stock name</td>
@<td>Stock price</td>
@</tr>
run-query @db_stock = "select stock_name, stock_price from stock" output stock_name, stock_price
@<tr>
@<td>
print-out stock_name
@</td>
@<td>
print-out stock_price
@</td>
@</tr>
end-query
@</table>
@</body>
@</html>
%%
Copied!
You're done! Now it's time to make your application. You need to tell Golf that your database configuration file "db_stock" is MariaDB (because you could use PostgreSQL or SQLite for instance):
gg -q --db="mariadb:db_stock"
Copied!
Test your web service. Here you'd run it as a command line program. That's neat because you can test your web services without even using a web server or a browser:
gg -r --req="/add-stock/name=ABC/price=882" --exec
gg -r --req="/add-stock/name=XYZ/price=112" --exec
Copied!
The result for each:
Content-Type: text/html;charset=utf-8
Cache-Control: max-age=0, no-cache
Pragma: no-cache
Status: 200 OK
<html>
<body>
<div>
Stock price updated!
</div>
</body>
</html>
Copied!
And to test the list of stocks:
gg -r --req="/show-stock" --exe
Copied!
The result:
Content-Type: text/html;charset=utf-8
Cache-Control: max-age=0, no-cache
Pragma: no-cache
Status: 200 OK
<html>
<body>
<table>
<tr>
<td>Stock name</td>
<td>Stock price</td>
</tr>
<tr>
<td>
ABC</td>
<td>
882</td>
</tr>
<tr>
<td>
XYZ</td>
<td>
112</td>
</tr>
</table>
</body>
</html>
Copied!
You can see the actual response, the way it would be sent to a browser, or an API web client, or any other kind of web client.
How is memory organized in Golf
Golf is a memory-safe language. A string variable is the actual pointer to a string (whether it's a text or binary). This eliminates at least one extra memory read. Bytes before the string constitute the ID to a memory table entry as well as the length of a string, with additional info used by memory-safety mechanisms:
- "Ref count" (Reference count), stating how many Golf variables point to string,
- Status is used to describe string, such as whether it's scope is process-wide, if it's a string literal etc,
- "Next free" points to the next available string block (if this one was freed too),
- "Data ptr" points back to the string, which is used to speed up access.
Memory is always null-terminated, regardless of whether it's text or binary. Here's what that looks like in a picture:
Each memory block (ID+Length+string+trailing null) is a memory allocated by standard C'd memory allocation, while memory table is a continuous block that's frequently cached to produce fast access to string's properties.
Golf performs memory-safety check only at the entrance of a statement, meaning at input and output points (if needed). The actual implementation of any Golf statement does not use memory safety internally, because each is implemented in C as a memory safe algorithm to begin with. Because vast majority (probably close to 100%) of the functionality and computation happens inside statements (for a typical web application), the actual cost of memory safety is very small.
This is in contrast to general purpose memory-safe languages where libraries, modules, methods etc. are implemented in the memory-safe language and the entire implementation is subject to memory-safe instrumentation and/or other methods, such as bounds checking etc. It means that inherently such languages may perform more work doing such safe-memory checks.
Finally, by default memory is not deallocated immediately after it's out of scope. Rather, the freeing happens when a request is complete, because the request is really the "unit" of work in a web-service based language like Golf.
Memory safety: what about performance?
Memory safety guards against software security risks and malfunctions by assuring data isn't written to or read from unintended areas of memory. Preventing leaks is a separate feature that's important for web services which are long-running processes - memory leaks usually lead to running out of memory and crashes.
But what of the performance cost of memory safety? Golf is a very high level programming language. It's not like other languages, and you can intuitively experience that just by looking at the code. It feels more like speaking in English than moving bits and bytes or calling APIs.
So when you build your web services, you won't write a lot of code, rather you'd express what you want done in a declarative language. This code is designed to be memory safe, but because it's C, it avoids the penalty of being implemented in a general-purpose memory-safe language, where everything that's done, from bottom up and top down, would be subject to memory-safety checks.
As a result, the cost incurred on memory safety is mostly in checking input data of such statements and significantly less so in the actual implementation which is where most of the performance penalty would be. In addition, the output of Golf statements is generally new immutable memory, hence it needs no checking. This means memory safety checks are truly minimal, and likely close to a theoretical minimum.
Golf also has a light implementation of memory safety. One example is that any memory used in a request is by default released at the end of it, and not every time the memory's out of scope, which saves a lot of run-time checks.
In summary, the choices made when designing and implementing a memory safe programming language profoundly affect the resulting performance.
Multi-tenant SaaS (Notes web application) in 200 lines of code
This is a complete SaaS example (Software-as-a-Service) using PostgreSQL as a database, and Golf as a web service engine; it includes user signup/login/logout with an email and password, separate user accounts and data, and a notes application. All in about 200 lines of code! Here's a video that shows it - two users sign up and create their own notes.
First create a directory for your application, where the source code will be:
mkdir -p notes
cd notes
Copied!
Create PostgreSQL user (with the same name as your logged on Linux user, so no password needed), and the database "db_app":
echo "create user $(whoami);
create database db_app with owner=$(whoami);
grant all on database db_app to $(whoami);
\q" | sudo -u postgres psql
Copied!
Create a database configuration file to describe your PostgreSQL database above:
echo "user=$(whoami) dbname=db_app" > db_app
Copied!
Create database objects we'll need - users table for application users, and notes table to hold their notes:
echo "create table if not exists notes (dateOf timestamp, noteId bigserial primary key, userId bigint, note varchar(1000));
create table if not exists users (userId bigserial primary key, email varchar(100), hashed_pwd varchar(100), verified smallint, verify_token varchar(30), session varchar(100));
create unique index if not exists users1 on users (email);" | psql -d db_app
Copied!
Create application "notes" owned by your Linux user:
mgrg -i -u $(whoami) notes
Copied!
This executes before any other handler in an application, making sure all requests are authorized, file "before-handler.golf":
vi before-handler.golf
Copied!
Copy and paste:
before-handler
set-param displayed_logout = false, is_logged_in = false
call-handler "/session/check"
end-before-handler
Copied!
- Signup users, login, logout
This is a generic session management web service that handles user creation, verification, login and logout. Create file "session.golf":
vi session.golf
Copied!
Copy and paste:
%% /session/login-or-signup private
@<a href="<<print-path "/session/user/login">>">Login</a> <a href="<<print-path "/session/user/new/form">>">Sign Up</a><hr/>
%%
%% /session/login public
get-param pwd, email
hash-string pwd to hashed_pwd
random-string to sess_id length 30
run-query @db_app = "select userId from users where email='%s' and hashed_pwd='%s'" output sess_user_id : email, hashed_pwd
run-query @db_app no-loop = "update users set session='%s' where userId='%s'" input sess_id, sess_user_id affected-rows arows
if-true arows not-equal 1
@Could not create a session. Please try again. <<call-handler "/session/login-or-signup">> <hr/>
exit-handler
end-if
set-cookie "sess_user_id" = sess_user_id path "/", "sess_id" = sess_id path "/"
call-handler "/session/check"
call-handler "/session/show-home"
exit-handler
end-query
@Email or password are not correct. <<call-handler "/session/login-or-signup">><hr/>
%%
%% /session/start public
get-param action default-value "", is_logged_in type bool default-value false
if-true is_logged_in equal true
if-true action not-equal "logout"
call-handler "/session/show-home"
exit-handler
end-if
end-if
call-handler "/session/user/login"
%%
%% /session/show-home private
call-handler "/notes/list"
%%
%% /session/logout public
get-param is_logged_in type bool
if-true is_logged_in equal true
get-param sess_user_id
run-query @db_app = "update users set session='' where userId='%s'" input sess_user_id no-loop affected-rows arows
if-true arows equal 1
set-param is_logged_in = false
@You have been logged out.<hr/>
commit-transaction @db_app
end-if
end-if
call-handler "/session/show-home"
%%
%% /session/check private
get-cookie sess_user_id="sess_user_id", sess_id="sess_id"
set-param sess_id, sess_user_id
if-true sess_id not-equal ""
set-param is_logged_in = false
run-query @db_app = "select email from users where userId='%s' and session='%s'" output email input sess_user_id, sess_id row-count rcount
set-param is_logged_in = true
get-param displayed_logout type bool
if-true displayed_logout equal false
get-param action default-value ""
if-true action not-equal "logout"
@Hi <<print-out email>>! <a href="<<print-path "/session/logout">>">Logout</a><br/>
end-if
set-param displayed_logout = true
end-if
end-query
if-true rcount not-equal 1
set-param is_logged_in = false
end-if
end-if
%%
%% /session/verify-signup public
get-param code, email
run-query @db_app = "select verify_token from users where email='%s'" output db_verify : email
if-true code equal db_verify
@Your email has been verifed. Please <a href="<<print-path "/session/user/login">>">Login</a>.
run-query @db_app no-loop = "update users set verified=1 where email='%s'" : email
exit-handler
end-if
end-query
@Could not verify the code. Please try <a href="<<print-path "/session/user/new/verify-form">>">again</a>.
exit-handler
%%
%% /session/user/login public
call-handler "/session/login-or-signup"
@Please Login:<hr/>
@<form action="<<print-path "/session/login">>" method="POST">
@<input name="email" type="text" value="" size="50" maxlength="50" required autofocus placeholder="Email">
@<input name="pwd" type="password" value="" size="50" maxlength="50" required placeholder="Password">
@<button type="submit">Go</button>
@</form>
%%
%% /session/user/new/form public
@Create New User<hr/>
@<form action="<<print-path "/session/user/new/create">>" method="POST">
@<input name="email" type="text" value="" size="50" maxlength="50" required autofocus placeholder="Email">
@<input name="pwd" type="password" value="" size="50" maxlength="50" required placeholder="Password">
@<input type="submit" value="Sign Up">
@</form>
%%
%% /session/user/new/send-verify private
get-param email, verify
write-string msg
@From: service@your-service.com
@To: <<print-out email>>
@Subject: verify your account
@
@Your verification code is: <<print-out verify>>
end-write-string
exec-program "/usr/sbin/sendmail" args "-i", "-t" input msg status st
if-true st not-equal 0 or true equal false
@Could not send email to <<print-out email>>, code is <<print-out verify>>
set-param verify_sent = false
else-if
set-param verify_sent = true
end-if
%%
%% /session/user/new/create public
get-param email, pwd
hash-string pwd to hashed_pwd
random-string to verify length 5 number
begin-transaction @db_app
run-query @db_app no-loop = "insert into users (email, hashed_pwd, verified, verify_token, session) values ('%s', '%s', '0', '%s', '')" input email, hashed_pwd, verify affected-rows arows error err on-error-continue
if-true err not-equal "0" or arows not-equal 1
call-handler "/session/login-or-signup"
@User with this email already exists.
rollback-transaction @db_app
else-if
set-param email, verify
call-handler "/session/user/new/send-verify"
get-param verify_sent type bool
if-true verify_sent equal false
rollback-transaction @db_app
exit-handler
end-if
commit-transaction @db_app
call-handler "/session/user/new/verify-form"
end-if
%%
%% /session/user/new/verify-form public
get-param email
@Please check your email and enter verification code here:
@<form action="<<print-path "/session/verify-signup">>" method="POST">
@<input name="email" type="hidden" value="<<print-out email>>">
@<input name="code" type="text" value="" size="50" maxlength="50" required autofocus placeholder="Verification code">
@<button type="submit">Verify</button>
@</form>
%%
Copied!
- Notes application
This is the actual application that uses above session management services. Create file "notes.golf":
vi notes.golf
Copied!
Copy and paste:
%% /notes/delete public
call-handler "/notes/header"
get-param sess_user_id, note_id
run-query @db_app = "delete from notes where noteId='%s' and userId='%s'" : note_id, sess_user_id \
affected-rows arows no-loop error errnote
if-true arows equal 1
@Note deleted
else-if
@Could not delete note (<<print-out errnote>>)
end-if
%%
%% /notes/form-add public
call-handler "/notes/header"
@Add New Note
@<form action="<<print-path "/notes/add">>" method="POST">
@<textarea name="note" rows="5" cols="50" required autofocus placeholder="Enter Note"></textarea>
@<button type="submit">Create</button>
@</form>
%%
%% /notes/add public
call-handler "/notes/header"
get-param note, sess_user_id
run-query @db_app = "insert into notes (dateOf, userId, note) values (now(), '%s', '%s')" : sess_user_id, note \
affected-rows arows no-loop error errnote
if-true arows equal 1
@Note added
else-if
@Could not add note (<<print-out errnote>>)
end-if
%%
%% /notes/list public
call-handler "/notes/header"
get-param sess_user_id
run-query @db_app = "select dateOf, note, noteId from notes where userId='%s' order by dateOf desc" \
input sess_user_id output dateOf, note, noteId
match-regex "\n" in note replace-with "<br/>\n" result with_breaks status st cache
if-true st equal 0
set-string with_breaks = note
end-if
@Date: <<print-out dateOf>> (<a href="<<print-path "/notes/ask-delete">>?note_id=<<print-out noteId>>">delete note</a>)<br/>
@Note: <<print-out with_breaks>><br/>
@<hr/>
end-query
%%
%% /notes/ask-delete public
call-handler "/notes/header"
get-param note_id
@Are you sure you want to delete a note? Use Back button to go back,\
or <a href="<<print-path "/notes/delete">>?note_id=<<print-out note_id>>">delete note now</a>.
%%
%% /notes/header private
get-param is_logged_in type bool
if-true is_logged_in equal false
call-handler "/session/login-or-signup"
end-if
@<h1>Welcome to Notes!</h1><hr/>
if-true is_logged_in equal false
exit-handler
end-if
@<a href="<<print-path "/notes/form-add">>">Add Note</a> <a href="<<print-path "/notes/list">>">List Notes</a><hr/>
%%
Copied!
gg -q --db=postgres:db_app
Copied!
Run web services application server
mgrg notes
Copied!
In order to use this example, you need to be able to email local users, which means email addresses such as \"myuser@localhost\". To do that, install postfix (or sendmail). On Debian systems (like Ubuntu):
sudo apt install postfix
sudo systemctl start postfix
Copied!
and on Fedora systems (like RedHat):
sudo dnf install postfix
sudo systemctl start postfix
Copied!
When the application sends an email to a local user, such as <OS user>@localhost, then you can see the email sent at:
sudo vi /var/mail/<OS user>
Copied!
A web server sits in front of Golf application server, so it needs to be setup. This example is for Ubuntu, so edit Nginx config file there:
sudo vi /etc/nginx/sites-enabled/default
Copied!
Add this in "server {}" section (replace "your-user" with your OS user name):
location /notes/ { include /etc/nginx/fastcgi_params; fastcgi_pass unix:///home/your-user/.golf/apps/notes/sock/.sock; }
Copied!
Restart Nginx:
sudo systemctl restart nginx
Copied!
Go to your web browser, and enter:
http://127.0.0.1/notes/session/start
Copied!
Random numbers in Golf
Generating random numbers is important in a wide range of applications. For instance, session IDs often use random numbers; they are also used in generating passwords; another example is load balancing where (say instead of round-robin), the next available process to serve a request is chosen randomly; some applications (like gambling) depend on random qualities; any kind of simulation would heavily rely on random numbers; financial and polling applications use random samples to determine outcomes and policies. The list of possible uses is pretty long.
So with that in mind, generating random numbers in Golf is easy. The most common way is random-string statement:
random-string to rnd
print-out rnd new-line
Copied!
By default "rnd" will be a random string of length 20 consisting of digits (0-9) and letters (a-z and A-Z).
You can specify the length desired:
random-string to rnd length 100
Copied!
which will generate a random string of length 100.
You can also insist that it'd be made of digits only:
random-string to rnd length 100 number
Copied!
And you can make a binary random string, meaning each byte is ranging from 0-255 in value with:
random-string to rnd length 100 binary
Copied!
Of course, such a string could have a zero byte in it. Not to worry, since Golf keeps track of string lengths, and using this string (for instance copying) will perform correctly.
Note that when we say "random" we really mean pseudo-random. Achieving absolutely random value is more in the domain of mother Nature and quantum mechanics. However, Golf strives to deliver very good randomness, which is based on local process properties, such as Process ID (PID) and varied current time.
If you'd like to take the randomness a notch up, then you can use random-crypto statement. This uses a cryptographically secure pseudo random generator (CSPRNG) from OpenSSL library, which is closer to a truly random notion. Note however, for most purposes by far, a random-string will suffice. It delivers good randomness that's suitable for most applications and is much faster than random-crypto, which really should be used for cryptographic purposes only. random-crypto has "length" clause only and it produces binary values always, as is usually the case with cryptography.
More than one table in a database transaction in MariaDB
Here you'll learn how to use a database transaction to insert/update into multiple tables; so that if any of those fail, the entire transaction is cancelled (rollbacked), and if they all succeed, the transaction is committed as a whole, atomically.
What if you wanted to record temperatures in any given zip code, and compute averages as you go along, so both historical temperatures and averages are available at will, without computation? Here's how to do it. Setting up the database is probably the most of it, so that can't be avoided. But the actual application to do the job is super simple.
First, create a new directory for your application, and create a new application "climate":
mkdir temps
cd temps
gg -k climate
Copied!
Here's the database setup. We'll use a little "cat" trick with EOF so we can write directly to files. So in this case, all the lines between "cat << EOF..." and "EOF" are written to file "setup.sql", which is the database setup. We use MariaDB here; you can use other databases too:
cat << EOF > setup.sql
create user weather;
create database weather_journal;
grant all privileges on weather_journal.* to weather@localhost identified by 'pwd';
use weather_journal;
create table if not exists temperature_history (zip varchar(10), temp int, curr_date date, curr_time time);
create table if not exists climate_avg (zip varchar(10) primary key, average_temp int, count int);
EOF
Copied!
Run the database setup:
sudo mysql < setup.sql
Copied!
This file ("weather_db") is the database-config-file. It describes your database the way your database needs it, i.e. natively. So if you'd use PostgreSQL you'd use Postgres format. If you'd use SQLite, you'd use SQLite format. This makes it easy, since there's no new database config file format to learn:
cat << EOF > weather_db
[client]
user=weather
password=pwd
database=weather_journal
socket=/run/mysqld/mysqld.sock
EOF
Copied!
Here's the actual code. It's a Golf file "weather.golf", which contains two services, "/weather/insert" (to insert new temperature data) and "/weather/get-agv" (to get historical data and averages). The code is really quite self-explanatory. In Golf, every statements always starts with the new line (watch out for "\" at end of the line, which continues the line). So you can get documentation for get-param (to get input parameter), or run-query (to run a database query), etc.
In this case, for instance, for "/weather/insert" service, you need to provide "zip_code" and "temperature" parameters. The URL path to do that might be for instance "/weather/insert/zip_code=11111/temperature=75", or "/weather/insert?zip_code=11111&temperature=75", depending on what looks better to you, or to what practices you subscribe. If this is a web service, you can pass those parameters as a part of HTTP request body in a POST request; the point is, there's ways to supply them.
Here's the code:
cat << EOF > weather.golf
%% /weather/insert public
get-param zip_code
get-param temperature
begin-transaction
run-query @weather_db = "insert into temperature_history (zip, temp, curr_date, curr_time) \
values ('%s', '%s', CURRENT_DATE(), CURRENT_TIME())" \
input zip_code, temperature no-loop error-text et
if-true et not-equal ""
@Error in inserting temperature history [<<print-out et>>]
rollback-transaction @weather_db
exit-handler
else-if
run-query @weather_db = "insert into climate_avg (zip, average_temp, count) values ('%s', '%s', 1) \
on duplicate key update count=count+1, average_temp=(average_temp*(count-1)+'%s')/count" \
input zip_code, temperature, temperature no-loop error-text et
if-true et not-equal ""
@Error in updating temperature average [<<print-out et>>]
rollback-transaction @weather_db
exit-handler
end-if
end-if
commit-transaction @weather_db
@Data stored and average updated.
%%
%% /weather/get-avg public
get-param zip_code
run-query @weather_db = "select temp, curr_date, curr_time from temperature_history \
where zip='%s' order by curr_date, curr_time asc" input zip_code output temp, date, time
print-format "Temp [%4ld] Date [%s %s]\n", #temp, date, time
end-query
run-query @weather_db = "select average_temp, count from climate_avg where zip='%s'" input zip_code output avg, count
@Average is [<<print-out avg>>] from the total of [<<print-out count>>] samples
end-query
%%
EOF
Copied!
Make the application:
gg -q --db="mariadb:weather_db"
Copied!
Insert the data. Note we're using gg utility. You can skip the "--exec" here, and see the bash code to run your native application directly from command line.
gg -r --req="/weather/insert/zip_code=11111/temperature=82" --exec --silent-header
gg -r --req="/weather/insert/zip_code=11111/temperature=102" --exec --silent-header
gg -r --req="/weather/insert/zip_code=11111/temperature=91" --exec --silent-header
Copied!
The result is:
Data stored and average updated.
Data stored and average updated.
Data stored and average updated.
Copied!
And now you can query the data:
gg -r --req="/weather/get-avg/zip_code=11111" --exec --silent-header
Copied!
With the result like:
Temp [ 82] Date [2025-09-07 09:47:42]
Temp [ 102] Date [2025-09-07 09:47:42]
Temp [ 91] Date [2025-09-07 09:47:42]
Average is [92] from the total of [3] sample
Copied!
That's the application! You can run it from command-line or as a web service (see article-tree-web for an example of a setup).
More than one table in a database transaction in PostgreSQL
Here you'll learn how to use a database transaction to insert/update into multiple tables; so that if any of those fail, the entire transaction is cancelled (rollbacked), and if they all succeed, the transaction is committed as a whole, atomically.
What if you wanted to record temperatures in any given zip code, and compute averages as you go along, so both historical temperatures and averages are available at will, without computation? Here's how to do it. Setting up the database is probably the most of it, so that can't be avoided. But the actual application to do the job is super simple.
First, create a new directory for your application, and create a new application "climate":
mkdir temps
cd temps
gg -k climate
Copied!
Here's the database setup. We'll use a little "cat" trick with EOF so we can write directly to files. So in this case, all the lines between "cat << EOF..." and "EOF" are written to file "setup.sql", which is the database setup. We use MariaDB here; you can use other databases too:
cat << EOF > setup.sql
create user $(whoami)
create database weather_pdb with owner=$(whoami)
grant all on database weather_pdb to $(whoami)
\c weather_pdb
create table if not exists temperature_history (zip varchar(10), temp int, curr_date date, curr_time time);
create table if not exists climate_avg (zip varchar(10) primary key, average_temp int, count int);
EOF
Copied!
Run the database setup:
sudo -u postgres psql < setup.sql
Copied!
This file ("weather_pdb") is the database-config-file. It describes your database the way your database needs it, i.e. natively. So if you'd use MariaDB you'd use MariaDB format. If you'd use SQLite, you'd use SQLite format. This makes it easy, since there's no new database config file format to learn:
cat << EOF > weather_pdb
user=bear dbname=weather_pdb
EOF
Copied!
Here's the actual code. It's a Golf file "weather.golf", which contains two services, "/weather/insert" (to insert new temperature data) and "/weather/get-agv" (to get historical data and averages). The code is really quite self-explanatory. In Golf, every statements always starts with the new line (watch out for "\" at end of the line, which continues the line). So you can get documentation for get-param (to get input parameter), or run-query (to run a database query), etc.
In this case, for instance, for "/weather/insert" service, you need to provide "zip_code" and "temperature" parameters. The URL path to do that might be for instance "/weather/insert/zip_code=11111/temperature=75", or "/weather/insert?zip_code=11111&temperature=75", depending on what looks better to you, or to what practices you subscribe. If this is a web service, you can pass those parameters as a part of HTTP request body in a POST request; the point is, there's ways to supply them.
Here's the code:
cat << EOF > weather-postgres.golf
%% /weather-postgres/insert public
get-param zip_code
get-param temperature
begin-transaction @weather_pdb
run-query @weather_pdb = "insert into temperature_history (zip, temp, curr_date, curr_time) \
values ('%s', '%s', CURRENT_DATE, CURRENT_TIMESTAMP)" \
input zip_code, temperature no-loop error-text et
if-true et not-equal ""
@Error in inserting temperature history [<<print-out et>>]
rollback-transaction @weather_pdb
exit-handler
else-if
run-query @weather_pdb = "insert into climate_avg (zip, average_temp, count) values ('%s', '%s', 1) \
on conflict(zip) do update set count=climate_avg.count+1, \
average_temp=(climate_avg.average_temp*(climate_avg.count)+'%s')/(climate_avg.count+1)" \
input zip_code, temperature, temperature no-loop error-text et
if-true et not-equal ""
@Error in updating temperature average [<<print-out et>>]
rollback-transaction @weather_pdb
exit-handler
end-if
end-if
commit-transaction @weather_pdb
@Data stored and average updated.
%%
%% /weather-postgres/get-avg public
get-param zip_code
run-query @weather_pdb = "select temp, curr_date, curr_time from temperature_history \
where zip='%s' order by curr_date, curr_time asc" input zip_code output temp, date, time
print-format "Temp [%4ld] Date [%s %s]\n", #temp, date, time
end-query
run-query @weather_pdb = "select average_temp, count from climate_avg where zip='%s'" input zip_code output avg, count
@Average is [<<print-out avg>>] from the total of [<<print-out count>>] samples
end-query
%%
EOF
Copied!
Make the application:
gg -q --db="postgres:weather_pdb"
Copied!
Insert the data. Note we're using gg utility. You can skip the "--exec" here, and see the bash code to run your native application directly from command line.
gg -r --req="/weather-postgres/insert/zip_code=11111/temperature=82" --exec --silent-header
gg -r --req="/weather-postgres/insert/zip_code=11111/temperature=102" --exec --silent-header
gg -r --req="/weather-postgres/insert/zip_code=11111/temperature=91" --exec --silent-header
Copied!
The result is:
Data stored and average updated.
Data stored and average updated.
Data stored and average updated.
Copied!
And now you can query the data:
gg -r --req="/weather-postgres/get-avg/zip_code=11111" --exec --silent-header
Copied!
With the result like:
Temp [ 82] Date [2025-09-07 09:47:42]
Temp [ 102] Date [2025-09-07 09:47:42]
Temp [ 91] Date [2025-09-07 09:47:42]
Average is [91] from the total of [3] sample
Copied!
That's the application! You can run it from command-line or as a web service (see article-tree-web for an example of a setup).
More than one table in a database transaction in SQLite
Here you'll learn how to use a database transaction to insert/update into multiple tables; so that if any of those fail, the entire transaction is cancelled (rollbacked), and if they all succeed, the transaction is committed as a whole, atomically.
What if you wanted to record temperatures in any given zip code, and compute averages as you go along, so both historical temperatures and averages are available at will, without computation? Here's how to do it. Setting up the database is probably the most of it, so that can't be avoided. But the actual application to do the job is super simple.
First, create a new directory for your application, and create a new application "climate":
mkdir temps
cd temps
gg -k climate
Copied!
Here's the database setup. We'll use a little "cat" trick with EOF so we can write directly to files. So in this case, all the lines between "cat << EOF..." and "EOF" are written to file "setup.sql", which is the database setup. We use MariaDB here; you can use other databases too:
cat << EOF > setup.sql
drop table if exists temperature_history;
drop table if exists climate_avg;
create table if not exists temperature_history (zip varchar(10), temp int, curr_date date, curr_time time);
create table if not exists climate_avg (zip varchar(10) primary key, average_temp int, count int);
EOF
Copied!
Run the database setup:
sqlite3 $HOME/.golf/apps/func-test/app/weather_sdb.db < setup.sql
Copied!
This file ("weather_sdb") is the database-config-file. It describes your database the way your database needs it, i.e. natively. So if you'd use PostgreSQL you'd use Postgres format. If you'd use MariaDB, you'd use MariaDB format. This makes it easy, since there's no new database config file format to learn:
cat << EOF > weather_sdb
~/.golf/apps/func-test/app/weather_sdb.db
EOF
Copied!
Here's the actual code. It's a Golf file "weather.golf", which contains two services, "/weather/insert" (to insert new temperature data) and "/weather/get-agv" (to get historical data and averages). The code is really quite self-explanatory. In Golf, every statements always starts with the new line (watch out for "\" at end of the line, which continues the line). So you can get documentation for get-param (to get input parameter), or run-query (to run a database query), etc.
In this case, for instance, for "/weather/insert" service, you need to provide "zip_code" and "temperature" parameters. The URL path to do that might be for instance "/weather/insert/zip_code=11111/temperature=75", or "/weather/insert?zip_code=11111&temperature=75", depending on what looks better to you, or to what practices you subscribe. If this is a web service, you can pass those parameters as a part of HTTP request body in a POST request; the point is, there's ways to supply them.
Here's the code:
cat << EOF > weather-sqlite.golf
%% /weather-sqlite/insert public
get-param zip_code
get-param temperature
begin-transaction @weather_sdb
run-query @weather_sdb = "insert into temperature_history (zip, temp, curr_date, curr_time) \
values ('%s', '%s', date('now'), time('now'))" \
input zip_code, temperature no-loop error-text et
if-true et not-equal ""
@Error in inserting temperature history [<<print-out et>>]
rollback-transaction @weather_sdb
exit-handler
else-if
run-query @weather_sdb = "insert into climate_avg (zip, average_temp, count) values ('%s', '%s', 1) \
on conflict(zip) do update set count=count+1, average_temp=(average_temp*(count)+'%s')/(count+1)" \
input zip_code, temperature, temperature no-loop error-text et
if-true et not-equal ""
@Error in updating temperature average [<<print-out et>>]
rollback-transaction @weather_sdb
exit-handler
end-if
end-if
commit-transaction @weather_sdb
@Data stored and average updated.
%%
%% /weather-sqlite/get-avg public
get-param zip_code
run-query @weather_sdb = "select temp, curr_date, curr_time from temperature_history \
where zip='%s' order by curr_date, curr_time asc" input zip_code output temp, date, time
print-format "Temp [%4ld] Date [%s %s]\n", #temp, date, time
end-query
run-query @weather_sdb = "select average_temp, count from climate_avg where zip='%s'" input zip_code output avg, count
@Average is [<<print-out avg>>] from the total of [<<print-out count>>] samples
end-query
%%
EOF
Copied!
Make the application:
gg -q --db="sqlite:weather_sdb"
Copied!
Insert the data. Note we're using gg utility. You can skip the "--exec" here, and see the bash code to run your native application directly from command line.
gg -r --req="/weather-sqlite/insert/zip_code=11111/temperature=82" --exec --silent-header
gg -r --req="/weather-sqlite/insert/zip_code=11111/temperature=102" --exec --silent-header
gg -r --req="/weather-sqlite/insert/zip_code=11111/temperature=91" --exec --silent-header
Copied!
The result is:
Data stored and average updated.
Data stored and average updated.
Data stored and average updated.
Copied!
And now you can query the data:
gg -r --req="/weather-sqlite/get-avg/zip_code=11111" --exec --silent-header
Copied!
With the result like:
Temp [ 82] Date [2025-09-07 09:47:42]
Temp [ 102] Date [2025-09-07 09:47:42]
Temp [ 91] Date [2025-09-07 09:47:42]
Average is [91] from the total of [3] sample
Copied!
That's the application! You can run it from command-line or as a web service (see article-tree-web for an example of a setup).
Using Regex in Golf
Regex (or "REGular EXpressions") is a powerful way to search strings, as well as to replace parts of strings. It makes it easier to reliably do so, since regular expressions are usually short; at the same time there's a learning curve in becoming proficient. However, given that regex is ubiquitous, it is worth learning at least some of it, as it can come handy.
Golf's implementation of regex is via match-regex statement, which allows for both searching and replacing in a single statement. It also has a caching capability (meaning caching of compiled regex process), which can increase performance by up to 500%.
This article will show a few basic ways to use match-regex statement in your Golf code.
Create directory for your application:
mkdir -p regex
cd regex
Copied!
Create "reg" application:
gg -k reg
Copied!
Copy the following code to file "reg.golf":
%% /reg public
match-regex "(word)\\s+(order)" in "Reverse word order" replace-with "\\2 \\1" result res
print-out res new-line
match-regex "[abc]{3}" in "Recognize 'aaa' or 'aa' or 'abc' or 'cab'" status st
print-out st new-line
match-regex "[abc]{3}" in "Recognize 'aa' or 'aa' or 'bc' or 'ca'" status st
print-out st new-line
match-regex "[abc]{3}" in "Recognize 'aAa' or 'aa' or 'aBc' or 'Cab'" case-insensitive status st
print-out st new-line
XXXXXXXXX
match-regex "[abc]{3}" in "Recognize 'aAa' or 'aa' or 'aBc' or 'Cab'" replace-with "XXX" result res case-insensitive status st
print-out res new-line
print-out st new-line
%%
Copied!
Build your application server as a native executable:
gg -q
Copied!
Run it from the command line:
gg -r --req="/reg" --exec --silent-header
Copied!
The result is:
Reverse order word
3
0
3
Recognize 'XXX' or 'aa' or 'XXX' or 'XXX'
3
Copied!
Let's go over this one by one.
The first statement uses back-references, which is a way to refer to something that's found in the string:
match-regex "(word)\\s+(order)" in "Reverse word order" replace-with "\\2 \\1" result res
print-out res new-line
Copied!
Here, "word" and "order" are found. Since they are in parenthesis (meaning within "()"), they can be used as back-references. The first one would be \1, the second one \2 etc. In "replace-with" clause, we refer to them as "\\1" and "\\2" just because backslash in a special character used to escape others and needs to be escaped itself. "\\s+" means find any spaces ("\\s") which repeat at least one time ("+"). So we're looking for essentially a snippet like "word order" or "word order", and we are then replacing that with "\\2 \\1". Keep in mind that "\\1" refers to "word" and "\\2" refers to "order". So the result will be "order word", i.e. the two words will be output in reverse order.
Finding pattern, and counting them
match-regex "[abc]{3}" in "Recognize 'aaa' or 'aa' or 'abc' or 'cab'" status st
print-out st new-line
Copied!
Here, you're looking for any of the characters "a", "b" or "c" that repeat 3 times (which is what "{3}" does). Obviously "aaa", "abc" and "cab" fit that bill, while "aa" does not, so the output is 3.
Conversely, in this case, there are no instances of 3 characters (with each being "a", "b" or "c"), since all of them of length 2 (such as "aa", "bc" etc.), so the result will be 0:
match-regex "[abc]{3}" in "Recognize 'aa' or 'aa' or 'bc' or 'ca'" status st
print-out st new-line
Copied!
By default, the search is case sensitive. You can make it case insensitive with "case-insensitive" clause:
match-regex "[abc]{3}" in "Recognize 'aAa' or 'aa' or 'aBc' or 'Cab'" case-insensitive status st
print-out st new-line
Copied!
In this case, there are also 3 matches ("aAa", "aBc" and "Cab").
In the following example, we search for a pattern and replace it with something:
match-regex "[abc]{3}" in "Recognize 'aAa' or 'aa' or 'aBc' or 'Cab'" replace-with "XXX" result res case-insensitive status st
print-out res new-line
print-out st new-line
Copied!
Just like in previous example, 3 patterns will be recognized and replaced with "XXX" and with 3 matches as the status, the result is:
Recognize 'XXX' or 'aa' or 'XXX' or 'XXX'
3
Copied!
Some times you'd like to search for a pattern, but only if there's another pattern before it ("lookbehind") or after it ("lookahead").
Call web service from web service: stacking them up
A web service doesn't necessarily need to be called from "the web", meaning from the web browser or via API across the web. It can be called from another web service that's on a local network.
Typically, when called from the web, HTTPS protocol is used to ensure safety of that call. However, local networks are usually secure, meaning no one else has access to it but your own web services.
Thus, communication between local web services will be much faster if it doesn't use a secure protocol as it incurs the performance cost. Simple, fast and unburdened protocols, such as FastCGI, may be better.
FastCGI is interesting because it actually carries the same information as HTTP, so a web service can operate normally, using GET/POST/etc. request methods, passing parameters in URL, request body, environment variables etc. But at the same time, FastCGI is a fast binary protocol that doesn't incur cost of safety - and for local web-service to web-service communication, that's a good thing.
Just like HTTP, FastCGI can separate standard output from standard error, allowing both streams to be intermixed, but retrieved separately.
Overall, inter-web-service communication can be implemented with the aforementioned protocols in a way that preserves high-level HTTP functionality innate to web services, but with overall better performance.
Functions and parameters in Golf
In Golf, there are no "functions" or "methods" as you may be used to in other languages. Any encapsulation is a request handler - you can think of it as a simple function that executes to handle a request - it can an external request (i.e. from an outside caller such as web browser, web API, or from a command-line), or internal requests from another handler in your application.
By the same token, there are no formal parameters in a way that you may be used to. Instead, there are named parameters, basically name/value pairs, which you can set or get anywhere during the request execution. In addition, your request handler can handle the request body, environment variables, the specific request method etc. (see request). Here though, we'll focus on parameters only.
You'll use set-param to set a parameter, which can then be obtained anywhere in the current request, including in the current handler's caller or callee. Use get-param to obtain a parameter that's set with set-param.
Parameters are very fast - they are static creatures implemented at compile time, meaning only fixed memory locations are used to store them (making for great CPU caching), and any name-based resolution is used only when necessary, and always with fast hash tables and static caching.
Calling one handler from another
Here you'll see a few examples of passing input and output parameters between requests handlers. These handlers are both running in the same process of an application (note that application can run as many processes working in parallel). To begin, create an application:
mkdir param
cd param
gg -k param
Copied!
You'll also create two source files ("local.golf" and "some.golf") a bit later with the code below.
Let's start with a simple service that provides current time based on a timezone as an input parameter (in file "local.golf"):
begin-handler /local/time
get-param tzone default-value "MST"
get-time to curr_time timezone tzone
@<div>Current time is <<print-out curr_time>></div>
end-handler
Copied!
In this case, HTML code is output. Make the application:
gg -q --public
Copied!
and run it from command line (just as if it were called from a web browser):
gg -r --req="/local/time" --silent-header --exec
Copied!
with the result something like:
<div>Current time is Mon, 02 Dec 2024 16:27:03 EST</div>
Copied!
Calling request from another, example #1
For instance, here's the caller code which calls the above "/local/time" service (in file "some.golf"):
begin-handler /some/service
set-param tzone="EST"
call-handler "/local/time"
end-handler
Copied!
and in this case the output of the "/local/time" would simply become output of "/some/service" (and be presumably sent to a client like web browser).
You can also, however, return the string to the caller using set-param - here's the reworked "/local/time" service (in file "local.golf"):
begin-handler /local/time
get-param tzone default-value "MST"
get-time to curr_time timezone tzone
set-param curr_time
end-handler
Copied!
The result parameter will be obtained in the caller, and then output as HTML from there (we could save it to a file instead, or whatever), so here's what it'd be now in file "some.golf":
begin-handler /some/service
set-param tzone="EST"
call-handler "/local/time"
get-param curr_time
@<div>Current time is <<print-out curr_time>></div>
end-handler
Copied!
Make the project and run it:
gg -q --public
gg -r --req="/some/service" --silent-header --exec
Copied!
with the similar end result.
Calling request from another, example #2
begin-handler /check/even
get-param num type number
if-true num every 2
set-param is_even = true
else-if
set-param is_even = false
end-if
end-handler
Copied!
Here's calling it from another handler (add this to file "some.golf"):
begin-handler /some/task
set-param num = 23
call-handler "/check/even"
get-param is_even type bool
if-true is_even equal true
@EVEN
else-if
@ODD
end-if
end-handler
Copied!
Make the project and run it:
gg -q --public
gg -r --req="/some/task" --silent-header --exec
Copied!
with the result (since 23 is an odd number):
ODD
Copied!
Golf is a language and a platform built to provide native web services, and everything in it is centered around the notion of handling service calls. Simple name/value constructs rule the communication between handlers on the network as well as locally. Suffice it to say, Golf's not a classic C-like programming language (though ironically is built in C and compiles to C).
Security of web services
The security of web services is a broad subject, but there are a few common topics that one should be well aware. They affect if your web application, or an API service, will be a success or not.
Many web services provide an interface to a database. SQL injection is a very old, but nonetheless important issue. A naive implementation of SQL execution inside your code could open the door for a malicious actor to drop your tables, insert/update/delete records etc. Be sure that your back-end software is SQL injection proof.
No matter how careful you are about writing your web service code, memory safety is an important feature to have. It avoids exploitations such as buffer overwrites or underwrites, which can cause unexpected behavior. In addition, proper memory leak detection and prevention is important, especially because back-end services typically run as long-running processes, often times weeks and months without down-time. A leak could crash such a process simply because it would run out of memory, or could no longer open a new file.
A common issue is one of the security design. Some services are internal (or private), and some are external (or public). The external ones can be called by an end-user from a web browser, or via an API from an outside caller. In fact, calling such service could be huge security hole. Imagine if you had a service that updates your internal application data. Such a service clearly must never be external, rather it should only be accessible to your own services acting on behalf of outside actors. Be sure that the back-end software you use has simple and clearly-defined ability to handle such scenarios. Even if so, sometimes overly complicated security schemes can be hard to implement correctly and can be just as detrimental.
Virtually all web services authenticate their users. It usually means using email address and password for login, as well as cookies for browser users, or tokens otherwise. Never keep passwords in plain text or even obscured, only as a one-way hash. This way even if your user database is stolen, passwords cannot be (easily) recovered.
How to send email with Golf
This example shows how to send email with Golf. The web service you'll create here is very simple and it will display an HTML form to collect info needed to send email, such as "From" and "To" (the sender and the recipient emails), the Subject and of course the Message itself. Once user clicks Submit, email is sent.
Create directory for your application:
mkdir -p mail
cd mail
Copied!
Create "mail-sender" application:
gg -k mail-sender
Copied!
Copy the following code to file "mail.golf":
begin-handler /mail public
get-param action
if-true action equal "show_form"
@<h2>Enter email and click Send to send it</h2>
@Note: 'From' field must be the email address from the domain of your server.<br/><br/>
@<form action="<<print-path "/mail">>" method="POST">
@ <input type="hidden" name="action" value="submit_form">
@ <label for="from_mail">From:</label><br>
@ <input type="text" name="from_mail" value=""><br>
@ <label for="to_mail">To:</label><br>
@ <input type="text" name="to_mail" value=""><br><br>
@ <label for="subject_mail">Subject:</label><br>
@ <input type="text" name="subject_mail" value=""><br><br>
@ <label for="message">Message:</label><br>
@ <textarea name="message" rows="3" columns="50"></textarea>
@ <br/><br/>
@ <input type="submit" value="Send">
@</form>
else-if action equal "submit_form"
get-param from_mail
get-param to_mail
get-param message
get-param subject_mail
write-string msg
@From: <<print-out from_mail>>
@To: <<print-out to_mail>>
@Subject: <<print-out subject_mail>>
@
<<print-out message>>
end-write-string
exec-program "/usr/sbin/sendmail" args "-i", "-t" input msg status st
if-true st not-equal GG_OKAY
@Could not send email!
else-if
@Email sent!
end-if
@<hr/>
else-if
@Unrecognized action!<hr/>
end-if
end-handler
Copied!
The example uses exec-program to invoke a MTA (Mail Transfer Agent), in this case postfix or sendmail, but you can use any other that you like!
Build your application server as a native executable:
gg -q
Copied!
Run the application server using Golf's application server manager, called mgrg:
mgrg mail-sender
Copied!
You may or may not have MTA (Mail Transfer Agent) installed on your system. Install it anyway, for Ubuntu and Debian:
sudo apt install postfix
sudo systemctl start postfix
Copied!
and on RedHat and Fedora systems:
sudo dnf install postfix
sudo systemctl start postfix
Copied!
Now, since this application server will be accessed via web server, we'll need to setup a web server (aka "reverse proxy"). We'll use Apache, so follow the instructions to set up Apache, with <app path> being your application name, which is "mail-sender", and the "ProxyPass" directive in Step 3 will be (replace "your-user" with the name of your OS user):
ProxyPass "/mail-sender/" unix:///home/your-user/.golf/apps/mail-sender/sock/.sock|fcgi://localhost/mail-sender
Copied!
Once you've restarted Apache web server, go to your browser and try it. In this case, everything is happening locally on your computer. If your server were running on the Internet, then you would use that server's name instead of "127.0.0.1", and email would be with an actual provider instead of a local user name. To get the form that sends email:
http://127.0.0.1/mail-sender/mail/action=show_form
Copied!
In this case local user name we're sending email to is "bear", but you'd put your own user name:
And once you click Submit:
What is an application server
Every Golf application is built as both an application server and a command-line program. You can use both, depending on what's the nature of your application. Some programs are meant to be used in scripts, or executed directly from command line. Others need to stay in memory and execute user requests as servers. The nice thing is that they both work the same, meaning you can run from command line anything that an application server does, and vice versa. This is also handy for testing; it makes writing tests for an application server much easier because you can run such tests in a plain bash script.
What is an application server? It is a set of background resident processes. Each such process can be contacted via socket with a request, and it will provide a reply. An application server often sits behind a web server which accepts user requests, passes them to the application server, receives its reply and the passes this reply back to the user. This is a "reverse proxy" configuration. Note that this configuration, though typical, isn't a hard rule; end users can talk to an application server directly in some cases, such as on a secure local network.
A socket is always opened by an application server and it's listening for user requests. In fact, each application server process listens on the same socket, and an incoming user request will be automatically routed by the Operating System to the first available server process. This reduces contention and makes the serving of processes very fast, without unnecessary delays.
The socket used can be a Unix or TCP socket. Unix socket is the default one, and it works locally, meaning the caller and the application server must be on the same physical server. This is the most common scenario, and it's also the fastest method of delivering requests and replies. TCP sockets are used when the caller and the application server are on two separate machines - their performance depends on the bandwidth and especially the latency of network connection. A Unix socket is a kind of a special kernel file, while TCP socket is the the same kind of socket most network/internet programs use.
Golf application server uses FastCGI protocol over TCP, a fast binary multiplexing protocol built for performance. It doesn't have any built-in security, and for the purpose it's used for it shouldn't have any. Essentially, standard input, output and error streams can be sent simultaneously (but retrieved separately). This makes for sturdier and more streamlined architecture because these are standard streams any program will understand. This protocol is widely supported by web languages and web servers (PHP, Apache, Nginx, HAProxy etc.).
A Golf server process can serve an unlimited number of requests without having to be restarted and without having to spawn any new processes or threads - meaning lightening fast. Any number of such processes comprises the application server, which can then serve incoming requests truly in parallel. The number of server processes is typically determined by the number of available CPUs.
How to build a Web Service API
This article will show a simple shopping web API with basic functions, such as adding customers, items and orders, as well as updating and deleting them. It's easy to write and easy to understand with Golf; that's the reason code doesn't have much in a way of comments - there's no need.
The API returns a valid JSON reply, even if it's just a single string (such as created ID for a customer, item or order). Listing an order returns a JSON document showing the order details.
If you'd like to be as RESTful as possible, you can use POST, PUT, GET or DELETE request methods. We'll cover that in another post.
The example is an open web service, i.e. it doesn't check for any permissions. You can add that separately (see article-notes-postgres).
This example will use PostgreSQL database, but you can use other databases too.
Keep this project in its own directory
mkdir shop
cd shop
gg -k shopping
Copied!
Create the database "db_shopping":
echo "create user $(whoami);
create database db_shopping with owner=$(whoami);
grant all on database db_shopping to $(whoami);
\q" | sudo -u postgres psql
Copied!
Create the "customers", "items", "orders" and "orderItems" tables we'll use:
echo "drop table if exists customers; create table if not exists customers (firstName varchar(30), lastName varchar(30), customerID bigserial primary key);
drop table if exists items; create table if not exists items (name varchar(30), description varchar(200), itemID bigserial primary key);
drop table if exists orders; create table if not exists orders (customerID bigint, orderID bigserial primary key);
drop table if exists orderItems; create table if not exists orderItems (orderID bigint, itemID bigint, quantity bigint);" | psql -d db_shopping
Copied!
Tell Golf about your database
echo "user=$(whoami) dbname=db_shopping" > db
Copied!
This tells Golf that a database "db" is setup (with database user being the same as your Operating System user, and the database name being "db_shopping"). Golf makes this easy by letting you use a given database's native format for client configuration, which you're likely to be familiar with. So if you used MariaDB or SQLite for instance, you would have used their native client configuration files.
Source code for web service
- Add a new customer
Create file "add-customer.golf" and copy the following to it:
begin-handler /add-customer
out-header use content-type "application/json"
get-param first_name
get-param last_name
run-query @db ="insert into customers (firstName, lastName) \
values ('%s', '%s') returning customerID" output customerID : \
first_name, last_name
@"<<print-out customerID>>"
end-query
end-handler
Copied!
- Add new item for sale
Create file "add-item.golf" and copy the following to it:
begin-handler /add-item
out-header use content-type "application/json"
get-param name
get-param description
run-query @db ="insert into items (name, description) \
values ('%s', '%s') returning itemID" output item_id : name, description
@"<<print-out item_id>>"
end-query
end-handler
Copied!
- Add an item to an order
Create file "add-to-order.golf" and copy the following to it:
begin-handler /add-to-order
out-header use content-type "application/json"
get-param order_id
get-param item_id
get-param quantity
run-query @db ="insert into orderItems (orderId, itemID, quantity) values ('%s', '%s', '%s')" \
: order_id, item_id, quantity no-loop affected-rows arows
@"<<print-out arows>>"
end-handler
Copied!
- Create a new order
Create file "create-order.golf" and copy the following to it:
begin-handler /create-order
out-header use content-type "application/json"
get-param customer_id
run-query @db ="insert into orders (customerId) \
values ('%s') returning orderID" output order_id : customer_id
@"<<print-out order_id>>"
end-query
end-handler
Copied!
- Delete an order
Create file "delete-order.golf" and copy the following to it:
begin-handler /delete-order
out-header use content-type "application/json"
get-param order_id
begin-transaction
run-query @db ="delete from orders where orderID='%s'" : order_id \
no-loop affected-rows order_rows
run-query @db ="delete from orderItems where orderID='%s'" : order_id \
no-loop affected-rows item_rows
commit-transaction
@{ "orders":"<<print-out order_rows>>", "items":"<<print-out item_rows>>" }
end-handler
Copied!
- Make a JSON document describing an order
Create file "json-from-order.golf" and copy the following to it:
begin-handler /json_from_order
get-param order_id type string
get-param curr_order type number
get-param order_count type number
get-param customer_id type string
get-param first_name type string
get-param last_name type string
@ {
@ "orderID": "<<print-out order_id>>",
@ "customer":
@ {
@ "customerID": "<<print-out customer_id>>",
@ "firstName": "<<print-out first_name>>",
@ "lastName": "<<print-out last_name>>"
@ },
@ "items": [
set-number curr_item = 0
run-query @db ="select i.itemID, t.name, t.description, i.quantity \
from orderItems i, items t where i.orderID='%s' \
and t.itemID=i.itemID" \
output itemID, itemName, itemDescription, itemQuantity : order_id \
row-count item_count
@ {
@ "itemID": "<<print-out itemID>>",
@ "itemName": "<<print-out itemName>>",
@ "itemDescription": "<<print-out itemDescription>>",
@ "itemQuantity": "<<print-out itemQuantity>>"
set-number curr_item=curr_item+1
if-true curr_item lesser-than item_count
@ },
else-if
@ }
end-if
end-query
@ ]
set-number curr_order = curr_order+1
if-true curr_order lesser-than order_count
@},
else-if
@}
end-if
end-handler
Copied!
- List orders
Create file "list-orders.golf" and copy the following to it:
begin-handler /list-orders
out-header use content-type "application/json"
get-param order_id default-value ""
set-number curr_order = 0
@{ "orders": [
if-true order_id not-equal ""
run-query @db = "select o.orderID, c.customerID, c.firstName, c.lastName \
from orders o, customers c \
where o.customerID=c.customerID and o.orderId='%s'" \
output customer_id, first_name, last_name \
row-count order_count : order_id
set-param order_id, curr_order, order_count, customer_id, first_name, last_name
call-handler "/json_from_order"
end-query
else-if
run-query @db ="select o.orderID, c.customerID, c.firstName, c.lastName \
from orders o, customers c \
where o.customerID=c.customerID order by o.orderId" \
output order_id, customer_id, first_name, last_name \
row-count order_count
set-param order_id, curr_order, order_count, customer_id, first_name, last_name
call-handler "/json_from_order"
end-query
end-if
@ ]
@}
end-handler
Copied!
- Update an order
Create file "update-order.golf" and copy the following to it:
begin-handler /update-order
out-header use content-type "application/json"
get-param order_id, item_id, quantity
set-number arows
if-true quantity equal "0"
run-query @db ="delete from orderItems where orderID='%s' and itemID='%s'" \
: order_id, item_id no-loop affected-rows arows
else-if
run-query @db ="update orderItems set quantity='%s' where orderID='%s' and itemID='%s'" \
: quantity, order_id, item_id no-loop affected-rows arows
end-if
@"<<print-out arows>>"
end-handler
Copied!
Specify the database "db" (remember we set it up above), and make all handlers public (i.e. they can handle external calls from the outside callers, and not just from within the application):
gg -q --db=postgres:db --public
Copied!
The following is just playing with the API. Golf lets you run your web services from command line, so you can see byte-for-byte exactly what's the response. So the responses below include HTTP header, which in this case is very simple. You can disable HTTP output by specifying "--silent-header" in gg invocations below.
Add new customer:
gg -r --req="/add-customer/first-name=Mike/last-name=Gonzales" --exec
Copied!
Resulting JSON (showing the ID of a new customer):
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"1"
Copied!
Add an item for sale (showing the ID of a newly added item):
gg -r --req="/add-item/name=Milk/description=Lactose-Free" --exec
Copied!
The result:
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"1"
Copied!
Add a new order for the customer we created (showing the ID of order):
gg -r --req="/create-order/customer-id=1" --exec
Copied!
The result:
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"1"
Copied!
Add an item to order, in quantity of 2 (showing number of items added, not the quantity):
gg -r --req="/add-to-order/order-id=1/item-id=1/quantity=2" --exec
Copied!
The result:
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"1"
Copied!
List orders:
gg -r --req="/list-orders" --exec
Copied!
Here's the JSON showing current orders (just one in our case):
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
{ "orders": [
{
"orderID": "1",
"customer":
{
"customerID": "1",
"firstName": "Mike",
"lastName": "Gonzales"
},
"items": [
{
"itemID": "1",
"itemName": "Milk",
"itemDescription": "Lactose-Free",
"itemQuantity": "2"
}
]
}
]
}
Copied!
Add another item for sale (showing the ID of this new item):
gg -r --req="/add-item/name=Bread/description=Sliced" --exec
Copied!
The result (showing the ID of a newly added item):
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"2"
Copied!
Add a quantity of 3 of the new item we added (ID of 2):
gg -r --req="/add-to-order/order-id=1/item-id=2/quantity=3" --exec
Copied!
The result (showing the number of items added, not the quantity):
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"1"
Copied!
List orders again:
gg -r --req="/list-orders" --exec
Copied!
The result, now there's new items here:
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
{ "orders": [
{
"orderID": "1",
"customer":
{
"customerID": "1",
"firstName": "Mike",
"lastName": "Gonzales"
},
"items": [
{
"itemID": "1",
"itemName": "Milk",
"itemDescription": "Lactose-Free",
"itemQuantity": "2"
},
{
"itemID": "2",
"itemName": "Bread",
"itemDescription": "Sliced",
"itemQuantity": "3"
}
]
}
]
}
Copied!
Update order, by changing the quantity of item (we specify order ID, item ID and the new quantity):
gg -r --req="/update-order/order-id=1/item-id=2/quantity=4" --exec
Copied!
The result showing number of items updated:
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
"1"
Copied!
List orders to show the update:
gg -r --req="/list-orders" --exec
Copied!
And it shows:
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
{ "orders": [
{
"orderID": "1",
"customer":
{
"customerID": "1",
"firstName": "Mike",
"lastName": "Gonzales"
},
"items": [
{
"itemID": "1",
"itemName": "Milk",
"itemDescription": "Lactose-Free",
"itemQuantity": "2"
},
{
"itemID": "2",
"itemName": "Bread",
"itemDescription": "Sliced",
"itemQuantity": "4"
}
]
}
]
}
Copied!
Delete an order:
gg -r --req="/delete-order/order-id=1" --exec
Copied!
The result JSON (showing the number of items deleted in it):
Content-Type: application/json
Cache-Control: max-age=0, no-cache
Status: 200 OK
{ "orders":"1", "items":"2" }
Copied!
You can see that building web services can be easy and fast. More importantly, what matters is also how easy it is to come back to it 6 months later and understand right away what's what. You can try that 6 months from now and see if it's true for you. I'd say chances are pretty good.
SQLite with Golf
This example will create a service that inserts key and value into SQLite table. It's tested from command line.
Create a directory and then switch to it:
mkdir sqlite
cd sqlite
Copied!
Setup SQLite database in file "mydata.db":
echo 'drop table if exists key_value;
create table if not exists key_value (key varchar(50) primary key, value varchar(100));' | sqlite3 mydata.db
Copied!
Create configuration file "mydb" that describes the SQLite database "mydata.db":
echo "$(pwd)/mydata.db"> mydb
Copied!
Create the application:
gg -k sqlite
Copied!
Create file insert.golf:
vim insert.golf
Copied!
Copy and paste to it (note use of database configuration "mydb" in @mydb):
%% /insert public
get-param key
get-param value
run-query @mydb = "insert into key_value(key,value) values ('%s', '%s')" input key, value error err affected-rows aff_rows no-loop
@Error <<print-out err>>, affected rows <<print-out aff_rows>>
%%
Copied!
Compile the application - we specify that file "mydb" is describing SQLite database:
gg -q --db=sqlite:mydb
Copied!
Run the application by executing this service from command line. Note passing the input parameters "key" and "value" to it:
gg -r --req="/insert/key=1/value=one" --exec --silent-header
Copied!
The output is:
Error 0, affected rows 1
Copied!
Verify data inserted:
echo -e ".headers off\n.mode line\nselect key "Key", value "Value" from key_value"|sqlite3 mydata.db
Copied!
The result:
Key = 1
Value = one
Copied!
Statements in Golf
Golf is a new programming language and framework for developing web services and web applications. The reason for Golf is to make software development easier and more reliable.
Golf is a declarative language designed for simplicity. That means top-down approach, rather than bottom-up: it's more about describing what to do than coding it. It's a modeling language where pieces are assembled together quickly and with confidence. It's about the framework to create and deploy web services based on what they need to do from human perspective, more so than the technical one.
Underlying Golf's functionality are industry-standard Open Source libraries, such as SSL, Curl, MariaDB and others, in addition to native Golf's.
In extended mode, Golf is extensible with any standard libraries. You can also include C files directly in your project to compile with it. In this mode, Golf (obviously) does not guaratee memory safety, but it does not necessarily mean it's not safe either.
Example of auto status checking with Golf
When talking about safety in programming, it is memory safety that usually takes the spotlight. However, here we'll touch on another common safety issue that typically causes application logic errors, meaning your program won't function correctly. It's about checking the status of any kind of statement that provides it. Not checking the status could mean that the result of a statement isn't correct, yet your program is proceeding as if it were. Of course, this is bound to cause problems, and this is true for any programming language.
Golf now has a built-in mechanism to help prevent issues like this. The approach taken (at this time at least) is not to force the developer to check status for every statement. Rather if status isn't checked, your program will stop in an orderly fashion and tell you exactly in which source file and which line number you didn't check the status that may cause an issue. It's a default fine line between code bloat and safety. Not every status needs to be checked. And this approach helps pinpoint the most pressing spots in your code where failure is the most likely to happen.
Another future enhancement is in the queue, which would allow (as an option) to force status checking on all statements.
Create an application in a separate directory:
mkdir status-check
cd status-check
gg -k file-transform
Copied!
Put the following code in file "file-name.golf":
%% /file-name public
silent-header
get-param fname
change-dir run-dir
read-file fname to file_content
match-regex "File: ([0-9]+).imp" in file_content replace-with "\\1" result res cache
print-out res
%%
Copied!
This will take file name ("fname") as an input parameter, read that file, and transform any text in it that starts with "File: " followed by a file name that's made up of digits (without an extension), and outputs those file names. So a bit contrived example, and arguably the point here has nothing to do with matching regex patterns. But it's an example from a real-world application, so I plugged it in just the same.
So, let's say the input file is "myfile" with contents:
File: 99281.imp
File: 3716243.imp
File: 124.imp
Copied!
Make the application:
gg -q
Copied!
Run it:
gg -r --req="/file-name/fname=myfile" --exec
Copied!
And the output is, as it should be:
99281
3716243
124
Copied!
Okay, so far so good. But let's run this program by specifying a non-existent file:
gg -r --req="/file-name/fname=nonexistant" --exec
Copied!
The output is (among other things like stack trace):
File [file-name.golf], line [5], Statement failed without status being obtained and/or checked [-1]
Copied!
Aha! So your program will safely stop as soon there's a failure in code where you didn't check for status, namely this line (number 5) from the code above:
read-file fname to file_content
Copied!
Now, let's add status and check it, so replace "file-name.golf" with this:
%% /file-name public
silent-header
get-param fname
change-dir run-dir
read-file fname to file_content status st
if-true st not-equal GG_OKAY
@Sorry, cannot open file <<print-out fname>>!
end-if
match-regex "File: ([0-9]+).imp" in file_content replace-with "\\1" result res cache
print-out res
%%
Copied!
Compile it and run again:
gg -q
gg -r --req="/file-name/fname=nonexistant" --exec
Copied!
And the result is:
Sorry, cannot open file noexistant!
Copied!
So now you can see how useful the automatic "static checking" feature is. It prevented unsafe execution (logic-wise) from moving forward, and provided you with a clear clue as to how to fix the issue.
Cache server in 30 lines
This is a cache server that can add, delete and query key/value pairs, with their number limited only by available memory.
We'll use "tree" type, which is a high-performance data structure. For example, with 1,000,000 keys it will take only about 20 comparisons to find any key; and the range search is just one hop. Index is based on a modified AVL/B tree.
Create new "tree" application first, in a new directory (you can name it anything you like):
mkdir -p tree
cd tree
Copied!
The mgrg command is a Golf service manager and here it will create a new application named "tree" (it can be different from the directory it's in):
gg -k tree
Copied!
Create a source code file "srv.golf":
vi srv.golf
Copied!
and copy and paste this:
begin-handler /srv public
do-once
new-tree ind process-scope
end-do-once
get-param op
get-param key
get-param data default-value ""
if-true op equal "add"
write-tree ind key (key) value data status st
if-true st equal GG_ERR_EXIST
@Key exists [<<print-out key>>]
else-if
@Added [<<print-out key>>]
end-if
else-if op equal "delete"
delete-tree ind key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found [<<print-out key>>]
else-if
@Deleted, old value was [<<print-out val>>]
end-if
else-if op equal "query"
read-tree ind equal (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found, queried [<<print-out key>>]
else-if
@Value [<<print-out val>>]
end-if
end-if
end-handler
Copied!
A service will run as a single process because each operation is handled very fast, even with large number of concurrent requests.
gg -q
Copied!
mgrg -w 1 tree
Copied!
The above will start a single server process (-w 1) to serve incoming requests.
This is a bash test script to insert 3 keys into your cache server, query them, then delete them. Create "test_tree" file:
vi test_tree
Copied!
And copy/paste the following:
for i in {1..3}; do
gg -r --req="/srv/op=add/key=$i/data=data_$i" --exec --service --app="/tree" --silent-header
done
echo "Keys added"
for i in {1..3}; do
gg -r --req="/srv/op=query/key=$i" --exec --service --app="/tree" --silent-header
done
echo "Keys queried"
ERR="0"
for i in {1..3}; do
gg -r --req="/srv/op=delete/key=$i" --exec --service --app="/tree" --silent-header
done
echo "Keys deleted"
Copied!
Make sure it's executable and run it:
chmod +x test_tree
./test_tree
Copied!
The result is this:
Added [1]
Added [2]
Added [3]
Keys added
Value [data_1]
Value [data_2]
Value [data_3]
Keys queried
Deleted, old value was [data_1]
Deleted, old value was [data_2]
Deleted, old value was [data_3]
Keys deleted
Copied!
Cache as a web service
This example shows Apache as the front-end (or "reverse proxy") for article-tree - it's assumed you've completed it first. Three steps to setting up Apache quickly:
- Enable FastCGI proxy used to communicate with Golf services - this is one time only:
- If you use Ubuntu and similar:
sudo a2enmod proxy
sudo a2enmod proxy_fcgi
Copied!
- If you use Fedora and similar:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
and if you use OpenSUSE:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
Add the following at the end of httpd.conf:
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_fcgi_module modules/mod_proxy_fcgi.so
Copied!
- Edit Apache configuration file:
- If you use Debian (such as Ubuntu):
sudo vi /etc/apache2/apache2.conf
Copied!
- If you use Fedora (such as RedHat), Archlinux:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
- If you use OpenSUSE:
sudo vi /etc/apache2/httpd.conf
Copied!
Add this to the end of the configuration file - note "tree" is the application name you created in the above example (replace "your-user" with your OS user name):
ProxyPass "/tree/" unix:///home/your-user/.golf/apps/tree/sock/.sock|fcgi://localhost/tree
Copied!
- Restart Apache.
- On Debian systems (like Ubuntu) or OpenSUSE:
sudo systemctl restart apache2
Copied!
- On Fedora systems (like RedHat) and Arch Linux:
sudo systemctl restart httpd
Copied!
- Test web service
Now you can call your web service, from the web. In this case it's probably a local server (127.0.0.1) if you're doing this on your own computer. The URLs would be, for example to add, query and delete a key/value pair:
http://127.0.0.1/tree/srv/op=add/key=1/data=d_1
Copied!
http://127.0.0.1/tree/srv/op=query/key=1
Copied!
http://127.0.0.1/tree/srv/op=delete/key=1
Copied!
Note the URL request structure: first comes the application path ("/tree") followed by request path ("/srv") followed by URL parameters (such as "/op=add/key=1/data=d_1"). The result in web browser are messages informing you that the key was added, queried or deleted.
Using Vim color schemes with Golf
Golf installation comes with a Vim module for highlighting Golf code. After installing Golf, run this to install the Vim module:
gg -m
Copied!
The default color scheme looks like this:
To change color scheme, type ":colorscheme " in command mode, then press Tab to see available color schemes. Press Enter to choose one. For instance, in 'darkblue' color scheme, it may look like:
To make the change permanent, edit file ".vimrc" in home directory:
vi ~/.vimrc
Copied!
and append line:
colorscheme darkblue
Copied!
Web framework for C programming language
Golf has an "extended" mode, which allows for C code to be used directly. Normally, this is not allowed, but if you use extended-mode statement in your .golf file, then you can call C code from it.
In extended mode, Golf is effectively a web framework for C programming language; read this for more about implications on memory safety.
Here's the example of using Golf as a web framework for C. In this case it's a simple C function to calculate the factorial of a a number. Then we'll expose this functionality in an equally simple web application.
Create the Golf application
mkdir -p c-for-web
cd c-for-web
Copied!
Create "fact" application ("-k"):
gg -k fact
Copied!
Save the following into a file "calc-fact.golf". This is the web service which will interact with web clients (such as browsers); it will also call the C function we'll create a bit further below:
extended-mode
%% /calc-fact public
get-param par
string-number par to num
set-number result
call-extended factorial(num, &result)
@Factorial of <<print-out par>> is <<print-out result>>
%%
Copied!
Add C code to Golf application
#include "golf.h"
void factorial(gg_num f, gg_num *res)
{
*res = 1;
gg_num i;
for (i = 2; i <= f; i++) {
*res *= i;
}
}
Copied!
And an include file "factorial.h" to declare any function(s) we will use in Golf code:
void factorial(gg_num f, gg_num *res);
Copied!
Compile and start the server
gg -q
Copied!
Start the server:
mgrg fact
Copied!
Test the server from command line
gg -r --req=/calc-fact/par=12 --exec --service
Copied!
The result is:
Content-Type: text/html;charset=utf-8
Cache-Control: max-age=0, no-cache
Pragma: no-cache
Status: 200 OK
Factorial of 12 is 479001600
Copied!
This is the exact data that would be sent to an actual web client.
Test the server with web browser
First, edit Nginx config file, which for Ubuntu/Debian is at:
/etc/nginx/sites-enabled/default
Copied!
and on Fedora/RedHat is at:
/etc/nginx/nginx.conf
Copied!
Note you might have to use "sudo" to edit these files as they're generally not writable by ordinary users.
Find the "server" section, and add this inside it (replace "your-user" with your OS user name):
location /fact/ { include /etc/nginx/fastcgi_params; fastcgi_pass unix:///home/your-user/.golf/apps/fact/sock/.sock; }
Copied!
This will connect Nginx with the "fact" server you started above. Any requests with a URL path that start with "/fact/" will be delivered to your server, and the reply will go in reverse, ultimately being delivered to the client (such as web browser).
Restart Nginx server for this to take effect:
sudo systemctl restart nginx
Copied!
Try it from web browser with this URL:
http://127.0.0.1/fact/calc-fact/par=8
Copied!
If your Nginx runs on another port, specify it, for instance if it runs on port 81, use "127.0.0.1:81" instead.
The result is:
Factorial of 8 is 40320
Copied!
Of course, if you have a server on the web, just substitute "127.0.0.1" for your server's web address.
Introduction to Golf
Golf is a new programming language and framework for developing web services and web applications. It is:
- declarative language designed for simplicity,
- memory-safe,
- functional statically-typed,
- high-performance compiled language, designed to create fast and small native executables without interpreters or p-code,
- built on top of industry-standard Open Source libraries, such as SSL, Curl, MariaDB and others, in addition to native Golf's,
- extensible with any standard libraries,
- very simple to work with by design to reduce comlexity and improve performance.
Golf is at https://golf-lang.com/.
What is web service
Web service is code that responds to a request and provides a reply over HTTP protocol. It doesn't need to work over the web, despite its name. You can run a web service locally on a server or on a local network. You can even run a web service from command line. In fact, that's an easy way to test them.
The input comes from an HTTP request - this means via URL parameters plus (optional) request body.
The parameters could be in URL's path (such as "/a=b/c=d/...") or in its query string (such as "?a=b&c=d...") or both - this data is typically limited in size to 2KB. Additional parameters could be appended to the request body - this is for instance how files are uploaded in an HTML form.
Request body itself can be any data of any size really - web services typically have an adjustable size limit for this data just to avoid mistakenly (or maliciously) huge ones. A request body could contain for example a JSON document, or some other kind of data.
The output of web service can be HTML code, JSON, XML, an image such as JPG or just about anything really. It's up to the caller of web service to interpret it. One such caller is web browser, another one could be API from an application etc.
What's the difference between a web application and a web service? Well, technically a web application should be a collection of web services, which are typically more basic service providers. That's why web services are often used as endpoints for remote APIs. They generally have a well defined input and output and are not too big. They serve a specialized purpose most of the time.
Before handler
Purpose: Execute your code before a request is handled.
before-handler
...
end-before-handler
Copied!
Every Golf request goes through a request dispatcher (see request()), which is auto-generated. In order to specify your code to execute before a request is handled, create source file "before-handler.golf" and implement code that starts with "before-handler" and ends with "end-before-handler", which will be automatically picked up and compiled with your application.
If no request executes (for example if your application does not handle a given request), before-handler handler does not execute either.
Here is a simple implementation of before-handler handler that just outputs "Getting Started!!":
before-handler
@Getting Started!!
end-before-handler
Copied!
Service processing
after-handler
before-handler
begin-handler
call-handler
See all
documentation
Begin handler
Purpose: Define a request handler.
begin-handler <request path> [ private | public ]
<any code>
end-handler
Copied!
begin-handler starts the implementation of a request handler for <request path> (see request), which is <any code> up to end-handler. <request path> is not quoted.
A <request path> is a path consisting of any number of path segments. A request path can have alphanumeric characters, hyphens and forward slashes, and can start only with a forward slash.
For example, a <request path> can be "/wine-items" or "/items/wine" etc. In general, it represents the nature of a request, such as an action on an object, a resource path handled by it etc. There is no specific way to interpret a request path, and you can construct it in a way that works for you.
The source ".golf" file name that implements a given begin-handler matches its path and name, fully or partially (see request). For example, <request path> of "/items/wine" might be implemented in "items/wine.golf" file (meaning in file "wine.golf" in subdirectory "items").
Note that you can also use "%%" instead of either begin-handler or end-handler or both. A <request path> cannot be a C reserved word, such as for instance "main" or "typedef" etc.
Security of request calls
If "private" clause is used, then a handler cannot be called from an outside caller; it can only be called from another handler by using call-handler statement.
If neither "public" nor "private" is used, then the default is "private". This default mechanism automatically guards direct execution by outside callers of all handlers not marked "public"; it provides automatic safety guard.
You can change this default behavior with "--public" option in gg, in which case the default is "public". This is useful if either all request handlers should be public, or if only a handful fixed ones are private.
The following begin-handler is implemented in file "items/wines/red-wine.golf":
begin-handler /items/wines/red-wine public
@This is a request handler to display a list of red wines!
end-handler
Copied!
Another way to write this is:
%% /items/wines/red-wine public
@This is a request handler to display a list of red wines!
%%
Copied!
Service processing
after-handler
before-handler
begin-handler
call-handler
See all
documentation
Begin transaction
Purpose: Begins database transaction.
begin-transaction [ @<database> ] \
[ on-error-continue | on-error-exit ] \
[ error <error> ] [ error-text <error text> ] \
[ options <options> ]
Copied!
This statement begins a database transaction.
<options> (in "options" clause) is any additional options to send to database you wish to supply for this functionality.
Once you start a transaction with begin-transaction, you must either commit it with commit-transaction or rollback with rollback-transaction. If you do neither, your transaction will be rolled back once the request has completed and your program will stop with an error message. This is because opening a transaction and leaving without committing or a rollback is a bug in your program.
You must use begin-transaction, commit-transaction and rollback-transaction instead of calling this functionality through run-query.
<database> is specified in "@" clause and is the name of the database-config-file. If omitted, your program must use exactly one database (see --db option in gg).
The error code is available in <error> variable in "error" clause - this code is always "0" if successful. The <error> code may or may not be a number but is always returned as a string value. In case of error, error text is available in "error-text" clause in <error text> string.
"on-error-continue" clause specifies that request processing will continue in case of an error, whereas "on-error-exit" clause specifies that it will exit. This setting overrides database-level db-error for this specific statement only. If you use "on-error-continue", be sure to check the error code.
Note that if database connection was lost, and could not be reestablished, the request will error out (see error-handling).
begin-transaction @mydb
run-query @mydb="insert into employee (name, dateOfHire) values ('%s', now())" input "Terry" no-loop
commit-transaction @mydb
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Boolean expressions
A boolean expression uses operators "!" (not), "&&" (and) and "||" (or), as well as parenthesis (). For example:
set-bool b1 = ! (b2 && b3) || b4
Copied!
You can use boolean expressions anywhere a boolean is expected as an input to any statement.
You can use boolean variables as well as constants such as "true" and "false" in boolean expressions.
You can reference boolean arrays elements (see new-array) by using subscription operator ([]), for instance:
new-array barr type boolean
write-array barr key 0 value true
set-bool bv = !barr[0]
Copied!
Booleans
boolean-expressions
set-bool
See all
documentation
Break loop
Purpose: Exit a loop.
break-loop
Copied!
break-loop will exit a loop between start-loop and end-loop, run-query and end-query, or read-line and end-read-line statements. Execution continues right after the end of the loop.
Exit the loop after 300 loops:
set-number max_loop = 300
start-loop repeat 1000 use i start-with 1
@Completed <<print-out i>> loops so far
if-true i equal max_loop
break-loop
end-if
end-loop
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Call extended
Purpose: Call external function or macro (extended mode only).
call-extended <function> "( " [ & ]<variable> [ , ... ] " )"
Copied!
call-extended calls <function> (which can be a function or macro) with a list of parameter variables. The <function> is defined either in:
- a library with C interop - note that such library can be written in many different languages. Most compiled languages can produce such libraries (such as Rust, C/C++ and others),
- a ".c" file residing in the directory that contains application source code - again such a C file can in turn call code from libraries produced by any language that supports C interop (most do).
- if a macro, in a ".h" file residing in the directory that contains application source code.
The <function> must be declared via C-style declaration in a ".h" file residing in the application source code directory. You can use "--lflag" and "--cflag" options of gg to supply libraries used. In addition, if you need to, you can also have any number of ".c" and ".h" files which will be automatically included in your project. A macro must be defined in ".h" file.
call-extended statement can only be used in extended mode (see extended-mode). By default, Golf code runs in safe mode which does not allow use of call-extended statement. Note that using call-extended statement does not automatically make your application unsafe; rather, extended code can be written in a memory-safe language (such as Rust), or even if written in C it can be made in such a way not to cause out-of-band memory reads and writes.
C signature, input/output variables, types
- "gg_num" which is a signed integer 8 bytes in length (int64_t type). This represents Golf number.
- "char *" which is a pointer to an array of characters. This represents Golf string value.
- "bool" which is a boolean variable. This represents Golf boolean.
A <function> should not return a value. Rather, use a variable passed as a pointer if you wish to pass the function's output back to your Golf code.
For more on using C in <function>s, see Server-API.
Changing current working directory
Web framework for C programming language
For instance, consider C file "calc.c":
#include "golf.h"
void factorial(gg_num f, gg_num *res)
{
*res = 1;
gg_num i;
for (i = 2; i <= f; i++) {
*res *= i;
}
}
Copied!
Declare this C function in a header file, for instance "calc.h":
void factorial(gg_num f, gg_num *res);
Copied!
You can also have macros in a header file, so for example "calc.h" could be:
void factorial(gg_num f, gg_num *res);
#define mod10(n, m) m=(n)%10
Copied!
In this case you have defined a macro that calculates the moduo of 10 and stores a result into another variable.
Use these in your Golf code with call-extended statement, for instance to use a function "factorial()":
extended-mode
begin-handler /fact public
set-number fact
call-extended factorial (10, &fact)
print-out fact
end-handler
Copied!
In the above example, number "fact" is passed by reference (as a pointer), and it will contain the value of factorial of 10 on return. The result printed out is "3628800".
To use macro "mod10()":
extended-mode
begin-handler /mod public
set-number mod
call-extended mod10(103, mod)
print-out mod
end-handler
Copied!
In this example, you are using a C macro, so number "fact" is assigned a value directly, per C language rules. The result printed out is "3".
C language
call-extended
extended-mode
web-framework-for-C-programming-language
See all
documentation
Call handler
Purpose: Call another handler within the same process.
call-handler <request path> [ return-value <return value> ]
Copied!
Calls another handler within the same request in the same process. You can call any handler within the same application. "Calling a handler" means executing it solely within the context of the top handler currently running; no before-handler or after-handler will execute for the called handler.
<request path> is the request path served by the handler being called. It can be a string variable or a constant.
Use set-param and get-param to pass parameters between the caller and callee handlers.
You can obtain a <return value> from the called handler <request path> by using "return-value" clause. See return-handler on how to return a number value from <request path> handler.
call-handler uses the same high-performance hash table used by a request to route requests by name; if <request path> is a constant string, then a hash table lookup is performed only once for the life of the process and all subsequent calls use a cached address of the request handler.
There is a limit on the call depth, including recursion in order to prevent application and system stability issues. See get-app and set-app with "stack-depth" clause for details and on how to change the defaults.
The following example demonstrate calling a call-handler twice, and also using its output inline in the caller. An input parameter is passed to it, and an output obtained:
Copy to file "callsub.golf":
%% /callsub public
set-param inp = "some string"
(( s
call-handler "/sub/service"
))
get-param out type string
@<<print-out s>> with output [<<print-out out>>]
set-param inp = "new string"
(( s
@Output: <<call-handler "/sub/service">>
))
get-param out type string
@<<print-out s>> with output [<<print-out out>>]
%%
Copied!
And in "sub/service.golf" file (meaning file "service.golf" in subdirectory "sub"):
%% /sub/service private
@This is sub!
get-param inp
(( out
@got input: <<print-out inp>>
))
set-param out = out
%%
Copied!
Create and build an application:
gg -k subhandler
gg -q
Copied!
Run it:
gg -r --req="/callsub" --exec --silent-header
Copied!
The output:
This is sub! with output [got input: some string]
Output: This is sub! with output [got input: new string]
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
Service processing
after-handler
before-handler
begin-handler
call-handler
See all
documentation
Call remote
Purpose: Make a remote service call.
call-remote <service> [ ,... ] \
[ status <status> ] \
[ started <started> ] \
[ finished-okay <finished okay> ]
Copied!
call-remote will make service call(s) as described in a single <service> or a list of <service>s. Unless only a single <service> is specified, each call will execute in parallel with others (as multiple threads). call-remote finishes when all <service> calls do. Each <service> must have beed created with new-remote.
A <service> call is made to a remote service. "Remote service" means a process accepting requests that is not the same process executing call-remote; it may be running on the same or a different computer, or it may be a different process started by the very same application.
- Multiple service calls in parallel
Executing multiple <service> calls in parallel is possible by specifying a list of <service>s separated by a comma.
There is no limit on how many <service>s you can call at the same time; it is limited only by the underlying Operating System resources, such as threads/processes and sockets.
- Call status
<status> number (in "status" clause) will be GG_OKAY if all <service> calls have each returned GG_OKAY; this means all have started and all have finished with a valid message from the service; or GG_ERR_FAILED if at least one did not (for example if the service could not be contacted, if there was a network error etc.); or GG_ERR_MEMORY if out of memory; or GG_ERR_TOO_MANY if there is too many calls (more than 1,000,000).
Note that GG_OKAY does not mean that the reply is considered a success in any logical sense; only that the request was made and a reply was received according to the service protocol.
- Request(s) status
Note that the actual application status for each <service>, as well as data returned and any application errors can be obtained via "exit-status", "data" and "error" clauses of read-remote statement, respectively.
- Request(s) duration
call-remote will wait for all <service> requests to finish. For that reason, it is a good idea to specify "timeout" clause in new-remote for each <service> used, in order to limit the time you would wait. Use read-remote to detect a timeout, in which case "exit-status" clause would produce GG_CLI_ERR_TIMEOUT.
- How many calls started and finished
<started> (in "started" clause) will be the number of service calls that have started. <finished okay> (in "finished-okay" clause) is the number of calls that have finished with return value of GG_OKAY as described above. By using <status>, <started> and <finished okay> you may surmise whether the results of call-remote meet your expectations.
- Performance, security
call-remote is faster than call-web because it does not use HTTP protocol; rather it only uses small and binary protocol, which is extremenly fast, especially when using Unix sockets on the same machine (see new-remote). Note that the binary protocol does not have any inherent security built-in; that is part of the reason why it is fast. As such, it is very well suited for remote service calls on the same machine or between networked machines on a secure network.
This example will connect to local Unix socket file "$HOME/.golf/app_name/sock/sock" (a Golf application named "app_name"), and make a request named "server" (i.e. it will be processed by source code file "server.golf") with URL path of "/op=add/key=2" (meaning with input parameters "op=add" and "key=2"). Then, service reply is read and displayed.
get-app user-directory to user_dir
new-remote srv location user_dir+"/app_name/sock/sock" \
method "GET" app-path "/app_name" request-path "/server" \
url-params "/op=add/key=2"
call-remote srv finished-okay sfok
read-remote srv data rdata
@Data from service is <<print-out rdata>>
Copied!
If you are connecting to a service via TCP (and not with a Unix socket like in the example above), the "location" clause in new-remote might be:
new-remote srv location "192.168.0.28:2400" \
method "GET" app-path "/app_name" request-path "/server" \
url-params "/op=add/key=2"
Copied!
In this case, you are connecting to another service (running on IP "192.168.0.28") on port 2400. See mgrg on how to start a service that listens on a TCP port. You would likely use TCP connectivity only if a service you're connecting to is on a different computer.
See also new-remote.
Distributed computing
call-remote
new-remote
read-remote
run-remote
See all
documentation
Call web
Purpose: Get content of URL resource (call a web address).
call-web <URL> \
response <result> \
[ response-code <response code> ] \
[ response-headers <headers> ] \
[ status <status> ] \
[ method <request method> ] \
[ request-headers \
[ content-type <content type> ] \
[ content-length <content length> ] \
custom <header name>=<header value> [ , ... ] ] \
[ request-body \
( [ fields <field name>=<field value> [ , ... ] ] \
[ files <file name>=<file location> [ , ... ] ] ) \
| \
( content <body content> ) \
] \
[ error <error> ] \
[ cert <certificate> | no-cert ] \
[ cookie-jar <cookie jar> ] \
[ timeout <timeout> ]
Copied!
With call-web, you can get the content of any accessible URL resource, for example web page, image, PDF document, XML document, REST API etc. It allows you to programmatically download URL's content, including the header. For instance, you might want to obtain (i.e. download) the source code of a web page and its HTTP headers. You can then save such downloaded items into files, analyze them, or do anything else.
<URL> is the resource locator, for example "https://some.web.page.com" or if you are downloading an image (for instance) it could be "https://web.page.com/image.jpg". Anything you can access from a client (such as web browser), you can also obtain programmatically. You can specify any URL parameters, for example "https://some.web.page.com?par1=val1&par2=val2".
The result is obtained via "response" clause into variable <result>, and the length (in bytes) of such response is obtained via "status" clause in <status> variable.
The response code (such as 200 for "OK", 404 for "Not Found" etc.) is available via "response-code" clause in number <response code>; the default value is 0 if response code is unavailable (due to error for instance).
"response-headers" clause allows for retrieval of response headers (such as HTTP headers) in <headers> variable, as a single string variable.
You can specify the request method using "method" clause. <method> has a string value of the request method, such as "GET", "POST", "PUT", "PATCH", "DELETE" or any other.
In case of error, <status> is negative, and has value of GG_ERR_FAILED (typically indicating system issue, such as lack of memory, library or system issue or local permissions), GG_ERR_WEB_CALL (error in accessing URL or obtaining data) - otherwise <status> is the length in bytes of the response (0 or positive). Optionally, you can obtain the error message (if any) via "error" clause in <error> variable. Error is an empty string ("") if there is no error.
If "timeout" clause is specified, call-web will timeout if operation has not completed within <timeout> seconds. If this clause is not specified, the default timeout is 120 seconds. If timeout occurs, <status> will be GG_ERR_WEB_CALL and <error> will indicate timeout. Timeout cannot be negative nor greater than 86400 seconds.
You can call any valid URL that uses protocol supported by the underlying library (cURL). If you're using https protocol (or any other that requires a SSL/TSL certificate), you can either use the local CA (certificate authority) issued, specify the location of a certificate with "cert" clause, or if you do not want it checked, use "no-cert". By default, the locally installed certificates are used; if the URL you are visiting is not trusted via those certificates, and you still want to visit it, use "no-cert"; and if you do have a no-CA (i.e. self-signed certificate) for that URL, use "cert" to provide it as a file name (either a full path or a name relative to current working directory, see directories).
If you'd like to obtain cookies (for example to maintain session or examine their values), use "cookie-jar" clause. <cookie jar> specifies the location of a file holding cookies. Cookies are read from this file (which can be empty or non-existent to begin with) before making a call-web and any changes to cookies are reflected in this file after the call. This way, multiple calls to the same server maintain cookies the same way browser would do. Make sure the same <cookie jar> file is not used across different application spaces, meaning it should be under the application home directory (see directories) and not used by multiple requests simultaneously (use different cookie jar file names for that), which is the most likely method of implementation.
The result of call-web (which is <result>) can be a text value or a binary value (for example if getting "JPG", "PNG", "PDF" or other documents). Either way, <status> is the number of bytes in a buffer that holds the value, which is also the value's string-length.
Request body, sending files and arbitrary content
- Structured content
Use "fields" and/or "files" subclauses to send a structured body request in the form of name/value pairs, the same as sent from an HTML form. To do that, you can specify fields with "fields" subclause in the form of <field name>=<field value> pairs separated by a comma. For instance, here two fields are set (field "source" with value "web" and field "act" with value "setcookie"):
To include files, use "files" subclause in the form of <file name>=<file location> separated by commas. For example, here "file1" is the file name sent (which can be anything), and local file "uploadtest.jpg" is the file whose contents is sent; and "file23" is the file name sent (which can be anything), and "fileup4.pdf" is the actual local file read and sent. In this case files are in the application home directory (see directories), but in general you can specify a relative or absolute path:
call-web "http://website.com" response resp response-code rc status len \
request-body files "file1"="uploadtest.jpg", "file23"="fileup4.pdf"
Copied!
You can specify both "files" and "fields" fields, for instance (along with getting error text and status):
call-web "http://website.com/app_name/some_request" response resp response-code rc
request-body fields "source"="web","act"="setcookie" \
files "file1"="uploadtest.jpg", "file23"="fileup4.pdf" \
status st error err
Copied!
There is no limit on the number of files and fields you can specify, other than of the underlying HTTP protocol.
- Non-structured content
To send any arbitrary (non-structured) content in the request body, such as JSON text for example, use "content" subclause:
call-web "https://website.com" response resp \
request-headers content-type "application/json" \
request-body content "{ \
\"employee\": { \
\"name\": \"sonoo\", \
\"salary\": 56000, \
\"married\": true \
} \
}"
Copied!
<content length> number in "content-length" subclause (in "request-headers" clause) can be specified to denote the length of body content:
read-file "somefile" to file_contents status file_length
call-web "https://website.com" response resp \
request-headers content-type "image/jpeg" \
request-headers content-length file_length \
request-body content file_contents
Copied!
If "content-length" is not used, then it is assumed to be the length of string <content>.
Request headers
If your request has a body (i.e. "request-body" clause is used), you can set the content type with "content-type" subclause of a request-headers clause:
call-web "https://<web address>/resource" \
request-headers content-type "application/json" \
request-body content some_json
Copied!
Note that using "content-type" without the request body may be ignored by the server processing your request or may cause it to consider the request invalid. If "content-type" is not used, the default is "multipart/form-data" if "fields" or "files" subclause(s) are used with "body-request" clause. Otherwise, if you use "content" subclause to send other types of data, you must set content type explicitly via "content-type" subclause of "request-headers" clause.
You can also specify custom request headers with "request-headers" clause, using "custom" subclause with a list of <header name>=<header value> pairs separated by a comma. For example, here custom header "Golf-header" has value of "Some_ID", and "Another-Header" a value of "New_ID":
call-web "http://website.com/<app name>/<request name>?act=get_file" response resp response-code rc status len \
request-headers custom "Golf-header"="Some_ID", "Another-Header"="New_ID"
Copied!
On the receiving side you can get any such custom header by using "header" clause of the get-req statement:
get-req header "Golf-header" to hvh0
get-req header "Another-Header" to hvh1
Copied!
Get the web page and print it out:
Get the "JPG" image from the web and save it to a file "pic.jpg":
Web
call-web
out-header
send-file
silent-header
See all
documentation
CGI
You can run Golf application as a CGI (Common Gateway Interface) program, if your web server supports CGI. This is not recommended in general, as CGI programs do not exhibit great performance. However in some cases you may need to use CGI, such as when performance is not of critical importance, or when other methods of execution are not feasible.
To run your application with CGI, use command-line program. Since Golf applications require running in the security context of the user who owns the application, you must use "suexec" (or similar feature) of your web server.
The following script sets up an application named "func_test" (any kind of application will do) to run as CGI (after it's been compiled with gg) on Apache web server running on Ubuntu 18 and up. For other web servers/distros, consult their documentation on how to setup CGI for a program.
sudo apt update
sudo a2enmod cgid
sudo service apache2 restart
sudo apt-get -y install apache2-suexec-custom
sudo a2enmod suexec
sudo service apache2 restart
sudo mkdir -p /usr/lib/cgi-bin/gg
sudo chown $(whoami):$(whoami) /usr/lib/cgi-bin/gg
sudo sed -i '1c\/usr/lib/cgi-bin/gg' /etc/apache2/suexec/www-data
sudo mv $HOME/.golf/apps/func-test/.bld/func-test /usr/lib/cgi-bin/gg
sudo chown $(whoami):$(whoami) /usr/lib/cgi-bin/gg/func-test
sudo chmod 700 /usr/lib/cgi-bin/gg/func-test
sudo sed -i "/SuexecUserGroup/d" /etc/apache2/sites-enabled/000-default.conf
sudo sed -i "s/<\/VirtualHost>/SuexecUserGroup $(whoami) $(whoami)\n<\/VirtualHost>/g" /etc/apache2/sites-enabled/000-default.conf
sudo service apache2 restart
Copied!
Running application
application-setup
CGI
command-line
service
See all
documentation
Change dir
Purpose: Change current working directory.
change-dir [ <directory> | home | run-dir ] [ status <status> ]
Copied!
change-dir will change current working directory to <directory> (which is a string that can be an absolute or relative path), or to application home directory (see directories) if "home" clause is used.
If "run-dir" clause is used, then current working directory is changed to the directory where you ran the program from. Note that this only applies to command-line programs. If you program runs as a service, then this clause has the same effect as "home" clause.
If "status" clause is used, then number <status> is GG_OKAY if change-dir is successful, or GG_FAILED if not (in which case you can use "errno" clause in get-req to find the specific reason why).
Note that if you change current working directory with call-extended, then you must set Golf internal boolean variable "gg_path_changed" to true.
change-dir "/home/user/new_dir" status s
if-true s equal GG_OKAY
@Directory changed
else
get-req errno to eno
@Error <<print-out eno>>
end-if
Copied!
Use relative path:
change-dir "./new_dir"
Copied!
Go back to application home directory:
change-dir home
Copied!
Directories
change-dir
change-mode
delete-dir
directories
new-dir
See all
documentation
Change mode
Purpose: Change permission mode for a file or directory.
change-mode <file-or-directory> mode <mode> [ status <status> ]
Copied!
change-mode will change permission mode for <file-or-directory> to <mode> as specified in "mode" clause. <mode> is a number, typically specified as octal (such as for instance 0750), see permissions. <file-or-directory> is a string that may be an absolute or relative path.
If "status" clause is used, then number <status> is GG_OKAY if succeeded, GG_ERR_EXIST if file or directory does not exist, or GG_ERR_FAILED for other errors (in which case you can use "errno" clause in get-req to find the specific reason why).
To give read and write privilege to user's group members ("6" means that as a second digit):
change-mode "myfile" mode 0760
Copied!
Directories
change-dir
change-mode
delete-dir
directories
new-dir
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Client API
You can use C API client library to connect to Golf:
- The API has only a few functions, and the main one is "gg_cli_request()", which makes a call to the service.
- There is only a single data type used, which is "gg_cli" and it is used to specify a request and its options, as well as to retrieve results.
- There is a single include file ("gcli.h").
- When building your client executable, you can either specify build flags by using the result of "gg -i" (if you have Golf installed), or use self-contained source files directly.
- It is MT-safe, so you can use it in multi-threaded applications, such as to make many requests in parallel.
See Examples section below for detailed examples.
Sending a request to Golf service
int gg_cli_request (gg_cli *req);
Copied!
All input and output is contained in a single variable of type "gg_cli", the pointer to which is passed to "gg_cli_request()" function that sends a request to the service. A variable of type "gg_cli" must be initialized to zero before using it (such as with {0} initialization, "memset()" or "calloc()"), or otherwise some of its members may have random values:
gg_cli req = {0};
...
...
int result = gg_cli_request (&req);
Copied!
Type "gg_cli" is defined as (i.e. public members of it):
typedef struct {
const char *server;
const char *req_method;
const char *app_path;
const char *req;
const char *url_params;
const char *content_type;
int content_len;
const char *req_body;
char **env;
int timeout;
int req_status;
int data_len;
int error_len;
char *errm;
gg_cli_out_hook out_hook;
gg_cli_err_hook err_hook;
gg_cli_done_hook done_hook;
int thread_id;
volatile char done;
int return_code;
} gg_cli;
Copied!
- Mandatory input
The following members of "gg_cli" type must be supplied in order to make a call to a service:
- "server" represents either a Unix socket or a TCP socket, and is:
- for a Unix socket, a fully qualified name to a Unix socket file used to communicate with the service (use gg_dir() function to obtain it for any Golf application, see below), or
- for a TCP socket, a host name and port name in the form of "<host name>:<port number>", specifying where is the server listening on (for instance "127.0.0.1:2301" if the Golf service is local and runs on TCP port 2301).
- "req_method" is a request method, such as "GET", "POST", "PUT", "DELETE" or any other.
- "app_path" is an application path (see request). By default it's "/<application name>".
- "req" is a request path, i.e. a request name preceded by a forward slash, as in "/<request name>" (see request).
- Get Unix socket file
To get Unix socket file path, use gg_dir() function, where "type" is the type of Golf's file or directory, "dir" is the string buffer for the path, "dir_size" is its size, "app" is the application name, and "user" is Operating System user name who owns the application (NULL if your own):
size_t gg_dir (int type, char *dir, size_t dir_size, char *app, char *user);
Copied!
Specifically to get the Unix socket file path, use GG_DIR_SOCKFILE for "type" parameter, and with "app-name" being the application name owned by you:
char dir[GG_MAX_OS_UDIR_LEN];
gg_dir (GG_DIR_SOCKFILE, dir, sizeof(dir), "app-name", NULL);
Copied!
Note that you can use GG_DIR_USER to get user base directory (where all Golf files are for a given user), GG_DIR_APPS to get the directory under which all applications are, GG_DIR_APP to get the directory under which all application files are, GG_DIR_FILE to get the file directory, GG_DIR_TRACE to get the directory where stack trace files are, and GG_DIR_BLD to get the directory where Golf application executables are (see directories).
- URL parameters
"url_params" is the URL parameters, meaning input parameters (as path segments and query string, see request). URL parameters can be NULL or empty, in which case it is not used.
- Request body (content)
"req_body" is the request body, which can be any text or binary data. "content_type" is the content type of request body (for instance "application/json" or "image/jpg"). "content_len" is the length of request body in bytes. A request body is sent only if "content_type" and "req_body" are not NULL and not empty, and if "content_len" is greater than zero.
- Passing environment to service
"env" is any environment variables that should be passed along to the service. You can access those in Golf via "environment" clause of get-sys statement. This is an array of strings, where name/value pairs are specified one after the other, and which always must end with NULL. For example, if you want to use variable "REMOTE_USER" with value "John" and variable "MY_VARIABLE" with value "8000", then it might look like this:
char *env[5];
env[0] = "REMOTE_USER";
env[1] = "John"
env[2] = "MY_VARIABLE";
env[3] = "8000"
env[4] = NULL;
Copied!
Thus, if you are passing N environment variables to the service, you must size "env" as "char*" array with 2*N+1 elements.
Note that in order to suppress output of HTTP headers from the service, you can include environment variable "GG_SILENT_HEADER" with value "yes"; to let the service control headers output (either by default, with "-z" option of mgrg or with silent-header) simply omit this environment variable.
- Timeout
"timeout" is the number of seconds a call to the service should not exceed. For instance if the remote service is taking too long or if the network connection is too slow, you can limit how long to wait for a reply. If there is no timeout, then "timeout" value should be zero. Note that DNS resolution of the host name (in case you are using a TCP socket) is not counted in timeout. Maximum value for timeout is 86400.
Even if timeout is set to 0, a service call may eventually timeout due to underlying socket and network settings. Note that even if your service call times out, the actual service executing may continue until it's done.
- Thread ID
"thread_id" is an integer that you can set and use when your program is multithreaded. By default it's 0. This number is set by you and passed to hooks (your functions called when request is complete or data available). You can use this number to differentiate the data with regards to which thread it belongs to.
- Completion indicator and return code
When your program is multithreaded, it may be useful to know when (and if) a request has completed. "done" is set to "true" when a request completes, and "return_code" is the return value from gg_cli_request() (see below for a list). In a single-threaded program, this information is self-evident, but if you are running more than one request at the same time (in different threads), you can use these to check on each request executing in parallel (for instance in a loop in the main thread).
Note that "done" is "true" specifically when all the results of a request are available and the request is about to be completed. In a multithreaded program, it means the thread is very soon to terminate or has already terminated; it does not mean that thread has positively terminated. Use standard "pthread_join()" function to make sure the thread has terminated if that is important to you.
Return value of gg_cli_request()
- GG_OKAY if request succeeded,
- GG_CLI_ERR_RESOLVE_ADDR if host name for TCP connection cannot be resolved,
- GG_CLI_ERR_PATH_TOO_LONG if path name of Unix socket is too long,
- GG_CLI_ERR_SOCKET if cannot create a socket (for instance they are exhausted for the process or system),
- GG_CLI_ERR_CONNECT if cannot connect to server (TCP or Unix alike),
- GG_CLI_ERR_SOCK_WRITE if cannot write data to server (for instance if server has encountered an error or is down, or if network connection is no longer available),
- GG_CLI_ERR_SOCK_READ if cannot read data from server (for instance if server has encountered an error or is down, or if network connection is no longer available),
- GG_CLI_ERR_PROT_ERR if there is a protocol error, which indicates a protocol issue on either or both sides,
- GG_CLI_ERR_BAD_VER if either side does not support protocol used by the other,
- GG_CLI_ERR_SRV if server cannot complete the request,
- GG_CLI_ERR_UNK if server does not recognize record types used by the client,
- GG_CLI_ERR_OUT_MEM if client is out of memory,
- GG_CLI_ERR_ENV_TOO_LONG if the combined length of all environment variables is too long,
- GG_CLI_ERR_ENV_ODD if the number of supplied environment name/value pairs is incorrect,
- GG_CLI_ERR_BAD_TIMEOUT if the value for timeout is incorrect,
- GG_CLI_ERR_TIMEOUT if the request timed out based on "timeout" parameter or otherwise if the underlying Operating System libraries declared their own timeout.
You can obtain the error message (corresponding to the above return values) in "errm" member of "gg_cli" type.
The service reply is split in two. One part is the actual result of processing (called "stdout" or standard output), and that is "data". The other is the error messages (called "stderr" or standard error), and that's "error". All of service output goes to "data", except from report-error and print-format (with "to-error" clause) which goes to "error". Note that "data" and "error" streams can be co-mingled when output by the service, but they will be obtained separately. This allows for clean separation of output from any error messages.
You can obtain service reply when it's ready in its entirety (likely most often used), or as it comes alone bit by bit (see more about asynchronous hooks further here).
Status of request execution
Getting data reply (stdout)
gg_cli req = {0};
...
if (gg_cli_request (&req) == GG_OKAY) {
char *data = gg_cli_data (req);
int data_len = req->data_len;
}
Copied!
"data_len" member of "gg_cli" type will have the length of data response in bytes. The reply is always null-terminated as a courtesy, and "data_len" does not include the terminating null byte.
"gg_cli_data()" returns the actual response (i.e. data output) from service as passed to "data" stream. Any output from service will go there, except when "to-error" clause is used in print-format - use these constructs to output errors without stopping the service execution. Additionally, the output of report-error will also not go to data output.
Getting error reply (stderr)
gg_cli req = {0};
...
if (gg_cli_request (&req) == GG_OKAY) {
char *err = gg_cli_error (req);
int err_len = req->error_len;
}
Copied!
"gg_cli_error()" returns any error messages from a service response, i.e. data passed to "error" stream. It is comprised of any service output when "to-error" clause is used in print-format, as well as any output from report-error.
"error_len" member (of "gg_cli" type above) will have the length of error response in bytes. The response is always null-terminated as a courtesy, and "error_len" does not include the terminating null byte.
Freeing the result of a request
gg_cli req = {0};
...
gg_cli_request (&req);
gg_cli_delete (&req);
Copied!
If you do not free the result, your program may experience a memory leak. If your program exits right after issuing any request(s), you may skip freeing results as that is automatically done on exit by the Operating System.
You can use "gg_cli_delete()" regardless of whether "gg_cli_request()" returned GG_OKAY or not.
A function you wrote can be called when a request has completed. This is useful in multithreaded invocations, where you may want to receive complete request's results as they are available. To specify a completion hook, you must write a C function with the following signature and assign it to "done_hook" member of "gg_cli" typed variable:
typedef void (*gg_cli_done_hook)(char *recv, int recv_len, char *err, int err_len, gg_cli *req);
Copied!
"recv" is the request's data output, "recv_len" is its length in bytes, "err" is the request's error output, and "err_len" is its length in bytes. "req" is the request itself which you can use to obtain any other information about the request. In a single threaded environment, these are available as members of the request variable of "gg_cli" type used in the request, and there is not much use for a completion hook.
See an example with asynchronous hooks.
You can obtain the service's reply as it arrives by specifying read hooks. This is useful if the service supplies partial replies over a period of time, and your application can get those partial replies as they become available.
To specify a hook for data output (i.e. from stdout), you must write a C function with the following signature and assign it to "out_hook":
typedef void (*gg_cli_out_hook)(char *recv, int recv_len, gg_cli *req);
Copied!
"recv" is the data received and "recv_len" is its length.
To specify a hook for error output (i.e. from stderr), you must write a C function with the following signature and assign it to "err_hook":
typedef void (*gg_cli_err_hook)(char *err, int err_len, gg_cli *req);
Copied!
"err" is the error received and "err_len" is its length.
"req" (in both hooks) is the request itself which you can use to obtain any other information about the request.
To register these functions with "gg_cli_request()" function, assign their pointers to "out_hook" and "err_hook" members of request variable of type "gg_cli" respectively. Note that the output hook (i.e. hook function of type "gg_cli_out_hook") will receive empty string ("") in "recv" and "recv_len" will be 0 when the request has completed, meaning all service output (including error) has been received.
For example, functions "get_output()" and "get_err()" will capture data as it arrives and print it out, and get_complete() will print the final result:
void get_output(char *d, int l, gg_cli *req)
{
printf("Got output of [%.*s] of length [%d] in thread [%d]", l, d, l, req->thread_id);
}
void get_err(char *d, int l, gg_cli *req)
{
printf("Got error of [%.*s] of length [%d], status [%d]", l, d, l, req->req_status);
}
void get_complete(char *data, int data_len, char *err, int err_len, gg_cli *req)
{
printf("Got data [%.*s] of length [%d] and error of [%.*s] of length [%d], status [%d], thread [%d]\n", data_len, data, data_len, err_len, err, err_len, req->req_status, req->thread_id);
}
...
gg_cli req = {0};
...
req.out_hook = &get_output;
req.err_hook = &get_err;
req.done_hook = &get_complete;
Copied!
The Golf client is MT-safe, meaning you can use it both in single-threaded and multi-threaded programs. Note that each thread must have its own copy of "gg_cli" request variable, since it provides both input and output parameters to a request call and as such cannot be shared between the threads.
Do not use this API directly with Golf - use call-remote instead which is made specifically for use in .golf files. Otherwise, you can use this API with any client program.
The following example is a simple demonstration, with minimum of options used. Copy the C code to file "cli.c" in a directory of its own:
#include "gcli.h"
void main ()
{
gg_cli req = {0};
char dir[GG_MAX_OS_UDIR_LEN];
gg_dir (GG_DIR_SOCKFILE, dir, sizeof(dir), "helloworld", NULL);
req.server = dir;
req.req_method = "GET";
req.app_path = "/helloworld";
req.req = "/hello-simple";
int res = gg_cli_request (&req);
if (res != GG_OKAY) printf("Request failed [%d] [%s]\n", res, req.errm);
else printf("%s", gg_cli_data(&req));
gg_cli_delete(&req);
}
Copied!
To make this client application:
gcc -o cli cli.c $(gg -i)
Copied!
In this case, you're using a Unix socket to communicate with the Golf service. To test with a Golf service handler, copy the following code to "hello_simple.golf" file in a separate directory:
begin-handler /hello_simple public
silent-header
@Hi there!
end-handler
Copied!
Create and make the Golf application and run it via local Unix socket:
sudo mgrg -i -u $(whoami) helloworld
gg -q
mgrg -m quit helloworld
mgrg -w 1 helloworld
Copied!
Run the client:
./cli
Copied!
The output is, as expected:
Hi there!
Copied!
Example with more options
Copy this to file "cli1.c" in a directory of its own - note that in this example a server will run on localhost (127.0.0.1) and TCP port 2301:
#include "gcli.h"
void main ()
{
gg_cli req;
memset (&req, 0, sizeof(req));
char *env[] = { "REMOTE_USER", "John", "SOME_VAR", "SOME\nVALUE", "NEW_VAR", "1000", NULL };
req.env = env;
req.server = "127.0.0.1:2301";
req.req_method = "GET";
req.app_path = "/helloworld";
req.req = "/hello";
req.url_params = "par1=val1&par2=91";
req.content_type = "application/json";
req.req_body = "This is request body";
req.content_len = strlen (req.req_body);
req.timeout = 0;
int res = gg_cli_request (&req);
if (res != GG_OKAY) printf("Request failed [%d] [%s]\n", res, req.errm);
else {
printf("Server status %d\n", req.req_status);
printf("Len of data %d\n", req.data_len);
printf("Len of error %d\n", req.error_len);
printf("Data [%s]\n", gg_cli_data(&req));
printf("Error [%s]\n", gg_cli_error(&req));
}
gg_cli_delete(&req);
}
Copied!
Note that the URL parameters (i.e. "req.url_params") could have been written as a combination of a path segment and query string (see request):
req.url_params = "/par1/val1?par2=91";
Copied!
or just as a path segment:
req.url_params = "/par1=val1/par2=91";
Copied!
To make this client application:
gcc -o cli1 cli1.c $(gg -i)
Copied!
To test it, you can create a Golf application. Copy this to "hello.golf" file in a separate directory:
begin-handler /hello public
silent-header
request-body rb
get-param par1
get-param par2
get-sys environment "REMOTE_USER" to ruser
get-sys environment "SOME_VAR" to somev
get-sys environment "NEW_VAR" to newv
get-req process-id to pid
@Hello World! [<<print-out ruser>>] [<<print-out somev>>] [<<print-out newv>>] [<<print-out par1>>] [<<print-out par2>>] <<print-out pid>> <<print-out rb>>
start-loop repeat 8000 use i start-with 0
@Output line #<<print-out i>>
if-true i equal 1419
print-format "Line %ld has an error\n", i to-error
end-if
if-true i equal 4419
exit-status 82
report-error "%s", "Some error!"
end-if
end-loop
end-handler
Copied!
Create and make the Golf application and run it on local TCP port 2301 to match the client above:
sudo mgrg -i -u $(whoami) helloworld
gg -q
mgrg -m quit helloworld
mgrg -w 1 -p 2301 helloworld
Copied!
Run the client:
./cli1
Copied!
The output:
Server status 82
Len of data 78530
Len of error 35
Data [Hello World! [John] [SOME
VALUE] [1000] [val1] [91] 263002 This is request body
Output line #0
Output line #1
Output line #2
Output line #3
Output line #4
Output line #5
Output line #6
Output line #7
...
Output line #4413
Output line #4414
Output line #4415
Output line #4416
Output line #4417
Output line #4418
Output line #4419
]
Error [Line 1419 has an error
Some error!
]
Copied!
The output shows service exit code (82, see exit-status in the Golf code above), length of data output, and other information which includes environment variables passed to the service from the client, the PID of server process, the request body from the client, and then the error output. Note that the data output (stdout) and the error output (stderr) are separated, since the protocol does use separate streams over the same connection. This makes working with the output easy, while the data transfer is fast at the same time.
API
Client-API
Server-API
See all
documentation
Close file
Purpose: Close file.
close-file file-id <file id> \
[ status <status> ]
Copied!
close-file closes file <file id> previously opened with open-file, where <file id> is an open file identifier.
You can obtain the status of file closing via <status> number (in "status" clause). The <status> is GG_OKAY if file is closed, or GG_ERR_CLOSE if could not close file.
If you do not close a file opened with open-file, Golf will automatically close it when the request ends.
See open-file.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Code blocks
Use curly braces ("{" and "}") to open and close a code block. They create a separate scope for previously non-existing variables defined within them, which begins with "{" and ends with "}". Note that if a variable existed in an outer scope, it cannot be created in the inner scope.
Note that if-true, run-query, start-loop and read-line statements contain implicit code blocks, meaning the code between them and the accompanying end-statement is within implicit "{" and "}".
The following code will first print out "outside" and then "inside" twice, illustrating the fact that variable "s1" is defined only in the outer scope once. Variable "s2" exists only in inner scope:
begin-handler /scope public
@<<print-out s1>>
set-string s1="outside"
{
set-string s2="inner variable"
set-string s1="inside"
@<<print-out s1>>
}
@<<print-out s1>>
end-handler
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Command line
A Golf application can run as a web application or a command-line program, or both - such as when some requests can be either fulfilled through web interface or executed otherwise (such as on the command line). Note that Golf produces two separate executables: a service one and a command-line one - they are different because command-line program does not need the service library and thus is smaller.
The name of the command-line executable is the same as the application name, and its path is (assuming <app name> is the application name):
$HOME/.golf/bld/<app name>/<app name>
Copied!
A command-line program works the same way as a service executable, and the output is the same, except that it is directed to stdout (standard output) and stderr (standard error).
To specify the exit code of a command-line program, use exit-status. To exit the program, use exit-handler, or otherwise the program will exit when it reaches the end of a request.
Here is how to execute a request "add-stock" in application "stock" with parameters "name" having a value of "ABC" and "price" a value of "300":
gg -r --app="/stock" --req="/add-stock?name=ABC&price=300" --exec
Copied!
Note that you if specify parameters as part of the path, you could write the above the same way as in a URL:
gg -r --app="/stock" --req="/add-stock/name=ABC/price=300" --exec
Copied!
You can generate the shell code to execute the above without using gg by omitting "--exec" option, for instance:
gg -r --app="/stock" --req="/add-stock/name=ABC/price=300"
Copied!
You can include a request body when executing a singe-run program. It is always included as the standard input (stdin) to the program.
You must provide the length of this input and the type of input, as well as a request method (such as POST, PUT, PATCH, GET, DELETE or any other).
Here is an example of using a request body to make a POST request on the command line - the application name is "json" and request name is "process". File "prices.json" is sent as request body:
gg -r --app=/json --req='/process?act=get_total&period=YTD' --method=POST --content=prices.json --content-type=application/json --exec
Copied!
You can generate the shell code for the above by omitting "--exec" option of gg utility.
Note that you can also include any other headers as environment variables by using the "HTTP_" convention, where custom headers are capitalized with use of underscore for dashes and prefixed with "HTTP_", for example header "Golf-Header" would be set as:
export HTTP_GOLF_HEADER="some value"
Copied!
You would set the "HTTP_" variable(s) prior to executing the program.
Suppressing HTTP header output for the entire application
If you wish to suppress the output of HTTP headers for all requests, use "--silent-header" option in "gg -r":
gg -r --app="/stock" --req="/add-stock/name=ABC/price=300" --exec --silent-header
Copied!
This will suppress the output of HTTP headers (either the default or with out-header), or for any other case where headers are output. This has the same effect as silent-header, the only difference is that the environment variable applies to the entire application.
Any data in "--req" option (and consequently in PATH_INFO or QUERY_STRING environment vairables if calling directly from shell) must be formatted to be a valid URL; for example, data that contains special characters (like "&" or "?") must be URL-encoded, for instance:
gg -r --app="/stock" --req="/add-stock/name=ABC%3F/price=300"
Copied!
In this case, parameter "name" has value of "ABC?", where special character "?" is encoded as "%3F".
To make sure all your input parameters are properly URL-encoded, you can use Golf's v1 code processor:
$($(gg -l)/v1 -urlencode '<your data>')
Copied!
For instance, to encode "a?=b" as a parameter:
gg -r --app="/stock" --req="/add-stock/name=$($(gg -l)/v1 -urlencode 'AB?')/price=300"
Copied!
If your parameters do not contain characters that need URL encoding, then you can skip this.
You can also use a command-line program with CGI (Common Gateway Interface).
Running application
application-setup
CGI
command-line
service
See all
documentation
Commit transaction
Purpose: Commits a database transaction.
commit-transaction [ @<database> ] \
[ on-error-continue | on-error-exit ] \
[ error <error> ] [ error-text <error text> ] \
[ options <options> ]
Copied!
Database transaction started with begin-transaction is committed with commit-transaction.
<options> (in "options" clause) is any additional options to send to database you wish to supply for this functionality.
Once you start a transaction with begin-transaction, you must either commit it with commit-transaction or rollback with rollback-transaction. If you do neither, your transaction will be rolled back once the request has completed and your program will stop with an error message. This is because opening a transaction and leaving without committing or a rollback is a bug in your program.
You must use begin-transaction, commit-transaction and rollback-transaction instead of calling this functionality through run-query.
<database> is specified in "@" clause and is the name of the database-config-file. If omitted, your program must use exactly one database (see --db option in gg).
The error code is available in <error> variable in "error" clause - this code is always "0" if successful. The <error> code may or may not be a number but is always returned as a string value. In case of error, error text is available in "error-text" clause in <error text> string.
"on-error-continue" clause specifies that request processing will continue in case of an error, whereas "on-error-exit" clause specifies that it will exit. This setting overrides database-level db-error for this specific statement only. If you use "on-error-continue", be sure to check the error code.
Note that if database connection was lost, and could not be reestablished, the request will error out (see error-handling).
begin-transaction @mydb
run-query @mydb="insert into employee (name, dateOfHire) values ('Terry', now())"
run-query @mydb="insert into payroll (name, salary) values ('Terry', 100000)"
commit-transaction @mydb
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Connect apache tcp socket
This shows how to connect your application listening on TCP port <port number> (started with "-p" option in mgrg) to Apache web server.
- Step 1:
To setup Apache as a reverse proxy and connect your application to it, you need to enable FastCGI proxy support, which generally means "proxy" and "proxy_fcgi" modules - this is done only once:
- For Debian (like Ubuntu) and OpenSUSE systems you need to enable proxy and proxy_fcgi modules:
sudo a2enmod proxy
sudo a2enmod proxy_fcgi
Copied!
- For Fedora systems (or others like Archlinux) enable proxy and proxy_fcgi modules by adding (or uncommenting) LoadModule directives in the Apache configuration file - the default location of this file on Linux depends on the distribution. For Fedora (such as RedHat), Archlinux:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
For OpenSUSE:
sudo vi /etc/apache2/httpd.conf
Copied!
Add this to the end of the file:
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_fcgi_module modules/mod_proxy_fcgi.so
Copied!
- Step 2:
Edit the Apache configuration file:
- For Debian (such as Ubuntu):
sudo vi /etc/apache2/apache2.conf
Copied!
- for Fedora (such as RedHat), Archlinux:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
- and for OpenSUSE:
sudo vi /etc/apache2/httpd.conf
Copied!
Add this to the end of file ("/<app path>" is the application path, see request):
ProxyPass "/<app path>/" fcgi://127.0.0.1:<port number>/
Copied!
- Step 3:
Finally, restart Apache. On Debian systems (like Ubuntu) or OpenSUSE:
sudo systemctl restart apache2
Copied!
On Fedora systems (like RedHat) and Arch Linux:
sudo systemctl restart httpd
Copied!
Note: you must not have any other URL resource that starts with "/<app path>/" (such as for example "/<app path>/something") as the web server will attempt to pass them as a reverse proxy request, and they will likely not work. If you need to, you can change the application path to be different from "/<app path>", see request.
Web servers
connect-apache-tcp-socket
connect-apache-unix-socket
connect-haproxy-tcp-socket
connect-nginx-tcp-socket
connect-nginx-unix-socket
See all
documentation
Connect apache unix socket
This shows how to connect your application listening on a Unix socket (started with mgrg) to Apache web server.
- Step 1:
To setup Apache as a reverse proxy and connect your application to it, you need to enable FastCGI proxy support, which generally means "proxy" and "proxy_fcgi" modules - this is done only once:
- For Debian (like Ubuntu) and OpenSUSE systems you need to enable proxy and proxy_fcgi modules:
sudo a2enmod proxy
sudo a2enmod proxy_fcgi
Copied!
- For Fedora systems (or others like Archlinux) enable proxy and proxy_fcgi modules by adding (or uncommenting) LoadModule directives in the Apache configuration file - the default location of this file on Linux depends on the distribution. For Fedora (such as RedHat), Archlinux:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
For OpenSUSE:
sudo vi /etc/apache2/httpd.conf
Copied!
Add this to the end of the file:
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_fcgi_module modules/mod_proxy_fcgi.so
Copied!
- Step 2:
Edit the Apache configuration file:
- For Debian (such as Ubuntu):
sudo vi /etc/apache2/apache2.conf
Copied!
- for Fedora (such as RedHat), Archlinux:
sudo vi /etc/httpd/conf/httpd.conf
Copied!
- and for OpenSUSE:
sudo vi /etc/apache2/httpd.conf
Copied!
Add this to the end of file ("/<app path>" is the application path (see request) and "<app name>" is your application name, and <user home dir> is your user home directory):
ProxyPass "/<app path>/" unix://<user home dir>/.golf/apps/<app name>/sock/.sock|fcgi://localhost/<app path>
Copied!
- Step 3:
Finally, restart Apache. On Debian systems (like Ubuntu) or OpenSUSE:
sudo systemctl restart apache2
Copied!
On Fedora systems (like RedHat) and Arch Linux:
sudo systemctl restart httpd
Copied!
Note: you must not have any other URL resource that starts with "/<app path>/" (such as for example "/<app path>/something") as the web server will attempt to pass them as a reverse proxy request, and they will likely not work. If you need to, you can change the application path to be different from "/<app path>", see request.
Web servers
connect-apache-tcp-socket
connect-apache-unix-socket
connect-haproxy-tcp-socket
connect-nginx-tcp-socket
connect-nginx-unix-socket
See all
documentation
Connect haproxy tcp socket
This shows how to connect your application listening on TCP port <port number> (started with "-p" option in mgrg) to HAProxy load balancer.
One use of HAProxy is to balance the load between different web servers, which in turn are connected to your Golf applications; in this case HAProxy does not directly communicate with your Golf applications (which are behind other web servers).
However, when you want HAProxy to directly communicate with your Golf application servers, you may use configuration similar to this (shown is just a bare-bone setup needed to accomplish the goal, note sections "frontend", "fcgi-app" and "backend" that are relevant to Golf). The HAProxy configuration file is typically in "/etc/haproxy/haproxy.cfg":
global
user haproxy
group haproxy
daemon
defaults
mode http
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
frontend front_server
mode http
bind *:90
use_backend backend_servers if { path_reg -i ^.*\/<your golf app name>\/.*$ }
option forwardfor
fcgi-app golf-fcgi
log-stderr global
docroot <user home dir>/.golf/apps/<your golf app name>/app
path-info ^.+(/<your golf app name>)(/.+)$
backend backend_servers
mode http
filter fcgi-app golf-fcgi
use-fcgi-app golf-fcgi
server s1 127.0.0.1:3000 proto fcgi
Copied!
Restart HAProxy:
sudo systemctl restart haproxy
Copied!
Note that Golf application path is "/<your golf app name>" (and the application name may or may not be the same, see request). The TCP port of the application is "3000" (could be any port number you choose that's greater than 1000 and lower than 65535).
HAProxy itself is bound to port 90 in this example (see "frontend" section above), and "path_reg" specifies which URLs will be passed to your Golf application (i.e. they must have "/<your golf app name>/" in the URL). "path-info" specifies SCRIPT_NAME and PATH_INFO (as "()" regular sub-expressions), which are as such passed to your Golf application. "docroot" is set to the application home directory (see directories) in case you wish to serve HTML documents from it; however if you keep sensitive data there, specify another directory.
A Golf application (named "<your golf app name>") would have been started with (using the same application name "<your golf app name>" and TCP port "3000"):
mgrg -p 3000 <your golf app name>
Copied!
Now you should be able to connect and load-balance your Golf application servers directly from HAProxy (which in this example listens on port 90, so you'd refer to it with https://your-web-server:90/<your golf app name>/...).
Web servers
connect-apache-tcp-socket
connect-apache-unix-socket
connect-haproxy-tcp-socket
connect-nginx-tcp-socket
connect-nginx-unix-socket
See all
documentation
Connect nginx tcp socket
This shows how to connect your application listening on TCP port <port number> (started with "-p" option in mgrg) to Nginx web server.
- Step 1:
You will need to edit the Nginx configuration file. For Ubuntu and similar:
sudo vi /etc/nginx/sites-enabled/default
Copied!
while on Fedora and other systems it might be at:
sudo vi /etc/nginx/nginx.conf
Copied!
Add the following in the "server {}" section ("/<app path>" is the application path, see request):
location /<app path>/ { include /etc/nginx/fastcgi_params; fastcgi_pass 127.0.0.1:<port number>; }
Copied!
- Step 2:
Finally, restart Nginx:
sudo systemctl restart nginx
Copied!
Note: you must not have any other URL resource that starts with "/<app path>/" (such as for example "/<app path>/something") as the web server will attempt to pass them as a reverse proxy request, and they will likely not work. If you need to, you can change the application path to be different from "/<app path>", see request.
Web servers
connect-apache-tcp-socket
connect-apache-unix-socket
connect-haproxy-tcp-socket
connect-nginx-tcp-socket
connect-nginx-unix-socket
See all
documentation
Connect nginx unix socket
This shows how to connect your application listening on a Unix socket (started with mgrg) to Nginx web server.
- Step 1:
You will need to edit the Nginx configuration file. For Ubuntu and similar:
sudo vi /etc/nginx/sites-enabled/default
Copied!
while on Fedora and other systems it might be at:
sudo vi /etc/nginx/nginx.conf
Copied!
Add the following in the "server {}" section ("/<app path>" is the application path (see request), "<app name>" is your application name, and <user home dir> is your user home directory):
location /<app path>/ { include /etc/nginx/fastcgi_params; fastcgi_pass unix://<user home dir>/.golf/apps/<app name>/sock/.sock; }
Copied!
- Step 2:
Finally, restart Nginx:
sudo systemctl restart nginx
Copied!
Note: you must not have any other URL resource that starts with "/<app path>/" (such as for example "/<app path>/something") as the web server will attempt to pass them as a reverse proxy request, and they will likely not work. If you need to, you can change the application path to be different from "/<app path>", see request.
Web servers
connect-apache-tcp-socket
connect-apache-unix-socket
connect-haproxy-tcp-socket
connect-nginx-tcp-socket
connect-nginx-unix-socket
See all
documentation
Continue loop
Purpose: Continue to the top of a loop.
continue-loop
Copied!
continue-loop will continue execution at the top of the loop at start-loop, run-query, or read-line statements.
Skip the processing if it's the loop #300:
define-number cont_loop = 300
start-loop repeat 1000 use i start-with 1
if-true i equal cont_loop
continue-loop
end-if
@Completed <<print-out i>> loops so far
end-loop
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Copy file
Purpose: Copies one file to another.
copy-file <source file> to <target file> [ status <status> ]
Copied!
File <source file> is copied into <target file>, which is created if it does not exist.
Status can be obtained in <status> variable, which is GG_ERR_OPEN if cannot open source file, GG_ERR_CREATE if cannot create target file, GG_ERR_READ if cannot read source file, GG_ERR_WRITE if cannot write target file, or number of bytes copied (including 0) on success.
copy-file "/home/user/source_file" to "/home/user/target_file" status st
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Copy string
Purpose: Copies (sub)string to another string.
copy-string <source string> to <dest string> \
[ start-with <start with> ] \
[ length <length> ]
Copied!
Use copy-string to copy <source string> to <dest string>, in its entirety or just a part of it.
<start with> number (in "start-with" clause) is the position in <source string> to start copying from, with 0 being the first byte.
Without "length" clause, the whole of <source string> is copied. With "length" clause, exactly <length> bytes are copied into <dest string>.
You can copy a string to itself. In this case, the original string remains and the new string references a copy:
set-string str = "original string"
set-string orig = str
copy-string str to str
upper-string str
Copied!
Substrings within expressions
set-string str = "some string!"
set-string res = @(str, 5,3) + " yes!"
Copied!
The value of variable "res" would be "str yes!". The advantage of using @() notation in string expressions is that it is more efficient and of higher performance; a substring is added to other string(s) without being first copied into a separate string.
After copy-string below, "my_str" will be a copy of string "some value":
set-string other_string="some value"
copy-string other_string to my_str
Copied!
Copy certain number of bytes, the result in "my_str" will be "ome":
set-string other_string="some value"
copy-string other_string to my_str length 3 start-with 1
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Count substring
Purpose: Count substrings.
count-substring <substring> in <string> to <count> [ case-insensitive [ <case insensitive> ] ]
Copied!
count-substring counts the number of occurrences of <substring> in <string> and stores the result in <count> (specified in "to" clause). By default, search is case-sensitive. If you use "case-insensitive" clause without boolean variable <case insensitive>, or if <case insensitive> evaluates to true, then the search is case-insensitive.
If <substring> is empty (""), <count> is 0.
In the following example, 1 occurrence will be found after the first count-substring, and 2 after the second (since case insensitive search is used there):
set-string sub = "world"
set-string str = "Hello world and hello World!"
count-substring sub in str to num_occ
print-format "Found %ld occurrences!\n", num_occ
count-substring sub in str to num_occ case-insensitive
print-format "Found %ld occurrences!\n", num_occ
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Current row
Purpose: Get or print out the row number of a current row in the result-set of a query.
current-row [ to <current row> ]
Copied!
Without "to" clause, current-row will print out the current row number. First row is numbered 1. With "to" clause, the row number is stored into variable <current row>. current-row must be within a run-query loop, and it always refers to the most inner one.
Display row number before a line with first and last name for each employee:
run-query @mydb="select firstName, lastName from employee" output firstName, lastName
@Row #<<current-row>><br/>
print-out firstName
@,
print-out lastName
@<br/>
end-query
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Database config file
Golf application can use any number of databases, with each specified by a database configuration file. This file provides database name, login and connection settings and preferences.
When making a Golf application, you specify a database vendor and the database configuration file for each database your application uses (see gg), for instance:
gg ... --db="mariadb:db1 postgres:db2 sqlite:db3" ...
Copied!
in which case there are three database configuration files (db1, db2 and db3), with db1 being MariaDB, db2 being PostgreSQL and db3 being SQLite database.
You must create a database configuration file for each database your application uses, and this file must be placed with your source code. Such file will be copied to locations specified and used by Golf to connect to database(s) (see directories).
Each such file contains connection information and authentication to a database, which Golf uses to login. The names of these configuration files are used in queries. There is no limit on how many databases can be used in your application and those from different vendors can be used in the same application.
An example of database configuration file (in this case MariaDB):
[client]
user=mydbuser
password=somepwd
database=mydbname
protocol=TCP
host=127.0.0.1
port=3306
Copied!
Database statements that perform queries (such as run-query) must specify the database configuration file used, unless your application uses only a single database. Such configuration is given by "@<database config file>" (for instance in run-query or begin-transaction). For example, in:
run-query @mydb="select name from employees"
...
end-query
Copied!
the query is performed on a database specified by the configuration file "mydb", as in (assuming it's PostgreSQL database):
gg ... --db="postgres:mydb" ...
Copied!
You do not need to manually connect to the database; when your application uses it for the first time, a connection is automatically established, and lost connection is automatically re-established when needed.
If a database is the only one used by your application, you can omit it, as in:
run-query ="select name from employees"
...
end-query
Copied!
The contents of a configuration file depends on the database used:
Substituting environment variables
[client]
user=${DB_USER}
password=${DB_PWD}
database=${DB_NAME}
protocol=TCP
host=127.0.0.1
port=${DB_PORT}
Copied!
Here, environment variables DB_USER, DB_PWD, DB_NAME and DB_PORT are used. They must be defined in the shell environment prior to calling gg to make your application (if not defined the value will be empty):
export DB_USER="my_user"
export DB_PWD="my_password"
export DB_NAME="my_database"
export DB_PORT="3307"
gg -q --db=mariadb:mydb
Copied!
which results in file $HOME/.golf/apps/<app name>/app/db/mydb:
[client]
user=my_user
password=my_password
database=my_database
protocol=TCP
host=127.0.0.1
port=3307
Copied!
Besides making application deployment easier, this also adds to its security as the information such as above (including the database password) does not need to be a part of source code and reside in source code control system (such as git).
Your environment variables can have any names, except that they cannot start with an underscore ("_") or be prefixed by "GG_" or "GG_", because those variable names are reserved by Golf.
Note that if your data actually has a dollar sign and is a part of the configuration file, then you can create a variable for it:
export DOLLAR_SIGN='$'
Copied!
and in the configuration file:
..
database=my${DOLLAR_SIGN}database
..
Copied!
In this case the database name is "my$database".
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Db error
Purpose: Either exit request or continue processing when there is an error in a database statement.
db-error [ @<database> ] ( exit | continue )
Copied!
db-error sets the response to the failure of database statements. You can change this response at run-time with each execution of db-error.
When a database statement (like run-query) fails, Golf will either exit request processing if "exit" is used, or continue if "continue" is used. "Exiting" is equivalent to calling report-error with the message containing details about the error. "Continuing" means that your program will continue but you should examine error code (see for instance "error" clause in run-query).
The default action is "exit". You can switch back and forth between "exit" and "continue". Typically, "exit" is preferable because errors in database statemets generally mean application or setup issues, however "continue" may be used when application wants to attempt to recover from errors or perform other actions.
Note that you can override the effect of db-error for a specific database statement by using clauses like "on-error-continue" and "on-error-exit" in run-query.
<database> is specified in "@" clause and is the name of the database-config-file. If omitted, your program must use exactly one database (see --db option in gg).
The following will not exit when errors happen going forward, but rather continue execution (and you should check every error henceforth):
db-error @mydb continue
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
Error handling
db-error
error-code
error-handling
report-error
See all
documentation
Debugging
If there is an error in a Golf program (such as trying to access invalid memory, negative status that hasn't been checked etc.), or if there's an internal issue (such as a bug in Golf), a stack trace is created in trace directory (see directories). A single stack trace file is created for each such incident, containing the description of the issue and the file names, function names and line numbers in your source code that led to it. The file names are based on the process-ID of the affected process. There is a limit on how many stack frames Golf will show this way (from the bottom up) - currently it's 150.
To see errors reported by Golf (such as trying to access invalid memory, or crashes; but not those from report-error), use -e option of gg to check the stack trace files, which contain the stack along with file names, function names and line numbers. For example, to see the last 3 errors reported:
gg -e 3
Copied!
Note that function names are decorated; meaning if a request name has a hyphen ("-"), then it is substituted with an underscore ("_") in a function name; if it has a forward slash ("/"), then it is substituted with a double underscore ("__"). For instance, request "request/sub-request" will be internally represented as function "request__sub_request" and will show up like that in a stack trace.
Output from Golf service without a web server
gg -r --req="/my-service" --service --exec
Copied!
mgrg starts your service process(es). If you're having issues with mgrg, check out its log. Assuming your application name is "app-name", the log file is:
$HOME/.golf/app-name/mgrglog/log
Copied!
If you are using a web server as a reverse proxy, check its error log, which would store the error messages emitted. Typically, such files are in the following location:
/var/log/<web server>
Copied!
(for example /var/log/apache2), but the location may vary - consult your web server's documentation.
In order to use gdb debugger, you don't need to do anything special. Golf itself as well as applications created with Golf already come with debugging information.
Ultimately, you can attach a debugger to a running Golf process. If your application name is "app-name", first find the PID (process ID) of its process(es):
ps -ef|grep app-name.srvc
Copied!
Note that you can control the number of worker processes started, and thus have only a single worker process (or the minimum necessary), which will make attaching to the process that actually processes a request easier (see gg).
Use gdb to load your program:
sudo gdb $HOME/.golf/apps/app-name/.bld/app-name.srvc
Copied!
and then attach to the process (<PID> is the process ID you obtained above):
att <PID>
Copied!
Once attached, you can break in the request you're debugging:
br <request name>
Copied!
or in general Golf request dispatcher:
br gg_dispatch_request
Copied!
which would handle any request to your application. Request names are decorated to become function names (see above).
Note that by default, gdb will show Golf code and you can step through it as you've written it, which is easy to follow and understand.
However, if you wish to step through the underlying C libraries, use "--c-lines" option in gg when making your application.
Debugging
debugging
See all
documentation
Decode base64
Purpose: Base64 decode.
decode-base64 <data> to <output data> \
[ input-length <input length> ]
Copied!
decode-base64 will decode string <data> into <output data>, which can be binary string.
If "input-length" clause is used, then <input length> is the number of bytes decoded, otherwise the entirety of <data> is decoded.
The result is stored in <output data> (in "to" clause).
Note that the string to decode can have whitespaces before it (such as spaces or tabs), and whitespaces and new lines after it, which will all be ignored for the purpose of decoding.
See encode-base64.
Base64
decode-base64
encode-base64
See all
documentation
Decode hex
Purpose: Decode hexadecimal string into data.
decode-hex <data> to <output> \
[ input-length <input length> ]
Copied!
decode-hex will decode hexadecimal string <data> to string <output> given in "to" clause.
<data> must consist of an even number of digits 0-9 and letters A-F or a-f. The length of <data> may be given by <input length> number in "input-length" clause, otherwise it is assumed to be the string length of <data>.
Get the original binary data from a hexadecimal string "hexdata". The output string "binout" is created:
set-string hexdata = "0041000F414200"
decode-hex hexdata to binout
Copied!
The value of "binout" will be binary data equal to this C literal:
"\x00""A""\x00""\x0F""AB""\x00""\x04"
Copied!
Hex encoding
decode-hex
encode-hex
See all
documentation
Decode url
Purpose: Decode URL-encoded string.
decode-url <string> [ input-length <length> ] [ status <status> ]
Copied!
decode-url will decode <string> (created by encode-url or other URL-encoding software) and store the result back into <string>. If you need <string> unchanged, make a copy of it first with copy-string. <length> in "input-length" clause specifies the number of bytes to decode; if omitted or negative, it is the string length of <string>.
All encoded values (starting with %) are decoded, and "+" (plus sign) is converted to space.
<status> number (in "status" clause) is GG_OKAY if all bytes decoded successfully, or in case of an error it is the index of the byte that could not be decoded (first byte is indexed "0"). If there is an error (for example hexadecimal value following % is invalid), the decoding stops and whatever was decoded up to that point is the result.
Decode URL-encoded string "str", after which it will hold a decoded string.
decode-url str
Copied!
URL encoding
decode-url
encode-url
See all
documentation
Decode web
Purpose: Decode web(HTML)-encoded string.
decode-web <string> [ input-length <length> ]
Copied!
decode-web will decode <string> (created by encode-web or other web-encoding software) and store the result back into it. If you need <string> unchanged, make a copy of it first with copy-string. To decode only a number of leading bytes in <string>, use "input-length" clause and specify <length>.
See encode-web.
Decode web-encoded string "str", after which it will hold a decoded string.
decode-web str
Copied!
Web encoding
decode-web
encode-web
See all
documentation
Decrypt data
Purpose: Decrypt data.
decrypt-data <data> to <result> \
[ input-length <input length> ] \
[ binary [ <binary> ] ] \
( password <password> \
[ salt <salt> [ salt-length <salt length> ] ] \
[ iterations <iterations> ] \
[ cipher <cipher algorithm> ] \
[ digest <digest algorithm> ]
[ cache ]
[ clear-cache <clear cache> ) \
[ init-vector <init vector> ]
Copied!
decrypt-data will decrypt <data> which must have been encrypted with encrypt-data, or other software using the same algorithms and clauses as specified.
If "input-length" clause is not used, then the number of bytes decrypted is the length of <data> (see string-length); if "input-length" is specified, then exactly <input length> bytes are decrypted. Password used for decryption is string <password> (in "password" clause) and it must match the password used in encrypt-data. If "salt" clause is used, then string <salt> must match the salt used in encryption. If "init-vector" clause is used, then string <init vector> must match the IV (initialization vector) used in encryption. If "iterations" clause is used, then <iterations> must match the number used in encryption.
The result of decryption is in <result> (in "to" clause).
If data was encrypted in binary mode (see encrypt-data), you must decrypt it with the same, and if it wasn't, then you must not use it in decrypt-data either. The reason for this is obvious - binary mode of encryption is encrypted data in its shortest form, and character mode (without "binary" or if <binary> evaluates to false) is the same data converted to a hexadecimal string - thus decryption must first convert such data back to binary before decrypting.
The cipher and digest algorithms (if specified as <cipher algorithm> and <digest algorithm> in "cipher" and "digest" clauses respectively) must match what was used in encrypt-data.
"cache" clause is used to cache the result of key computation, so it is not computed each time decryption takes place, while "clear-cache" allows key to be re-computed every time <clear cache> evaluates to boolean true; re-computation of a key, if used, must match the usage during encryption. For more on "cache" and "clear-cache" clauses, as well as safety of encrypting/decrypting, see "Caching key" and "Safety" in encrypt-data.
See encrypt-data.
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
Delete cookie
Purpose: Deletes a cookie.
delete-cookie <cookie name> [ path <cookie path> ] [ status <status> ] [ secure <secure> ]
Copied!
delete-cookie marks a cookie named <cookie name> for deletion, so it is sent back in the reply telling the client (such as browser) to delete it.
Newer client implementations require a cookie deletion to use a secure context if the cookie is considered secure, and it is recommended to use "secure" clause to delete such a cookie. This is the case when either "secure" clause is used without boolean variable <secure>, or if <secure> evaluates to true.
<cookie name> is a cookie that was either received from the client as a part of the request, or was added with set-cookie.
A cookie can be deleted before or after header is sent out (see out-header). However a cookie must be deleted prior to outputting any actual response (such as with output-statement or print-out for example), or the request will error out (see error-handling).
<status> (in "status" clause) is a number that will be GG_ERR_EXIST if the cookie did not exist, or GG_OKAY if it did.
The same cookie name may be stored under different URL paths. You can use "path" clause to specify <cookie path> to ensure the desired cookie is deleted.
delete-cookie "my_cookie"
set-bool is_secure = true
delete-cookie "my_cookie" path "/path" secure is_secure
Copied!
Cookies
delete-cookie
get-cookie
set-cookie
See all
documentation
Delete dir
Purpose: Delete directory.
delete-dir <directory> [ status <status> ]
Copied!
delete-dir will delete <directory>, which is a string that may be an absolute or relative path.
If "status" clause is used, then number <status> is GG_OKAY if succeeded, GG_ERR_EXIST if directory is not empty, or GG_ERR_FAILED for other errors (in which case you can use "errno" clause in get-req to find the specific reason why).
delete-dir "/home/user/some_dir"
Copied!
Directories
change-dir
change-mode
delete-dir
directories
new-dir
See all
documentation
Delete fifo
Purpose: Delete FIFO list elements up to the last one read, including.
delete-fifo <list>
Copied!
delete-fifo will delete all leading elements from the FIFO <list> up to the last one read, including. <list> was created by new-fifo.
Right after rewind-fifo, no element was read yet, and delete-fifo will have no effect. After any read-fifo, delete-fifo wil delete all elements up to the element read, including that element.
new-fifo mylist
write-fifo mylist key "key1" value "value1"
write-fifo mylist key "some2" value "other2"
read-fifo mylist key k value v
delete-fifo mylist
Copied!
FIFO
delete-fifo
new-fifo
purge-fifo
read-fifo
rewind-fifo
write-fifo
See all
documentation
Delete file
Purpose: Deletes a file.
delete-file <file location> [ status <status var> ]
Copied!
File specified with <file location> is deleted. <file location> can be given with an absolute path or relative to the application home directory (see directories).
If "status" is specified, the status is stored into <status var>. The status is GG_OKAY on success or if the file did not exist, and GG_ERR_DELETE on failure.
delete-file "/home/user/some_file" status st
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Delete lifo
Purpose: Delete LIFO list elements.
delete-lifo <list>
Copied!
delete-lifo will delete the most recently added elements to the LIFO <list> up to the last one read, including. <list> was created by new-lifo.
Right after rewind-lifo, no element was read yet, and delete-lifo will have no effect. Note that write-lifo also performs an implicit rewind-lifo.
After any read-lifo, delete-lifo wil delete all elements up to the element read, including that element.
new-lifo mylist
write-lifo mylist key "key1" value "value1"
write-lifo mylist key "some2" value "other2"
read-lifo mylist key k value v
delete-lifo mylist
Copied!
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
Delete list
Purpose: Delete current linked list element.
delete-list <list> [ status <status> ]
Copied!
delete-list will delete current element in linked <list> created with new-list. A current list element is the one that will be subject to statements like read-list and write-list. See position-list for more details on the current element.
<status> (in "status" clause) is GG_OKAY if element is deleted, or GG_ERR_EXIST if could not delete element (this can happen if the list is empty, or if current list element is beyond the last element, such as for instance if "end" clause is used in position-list statement).
Once an element is deleted, the current element becomes either the next one (if the current element wasn't the last one), or the previous one (if the current element was the last one).
delete-list mylist status st
Copied!
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
Delete string
Purpose: Free string memory.
delete-string <string>
Copied!
delete-string frees <string> variable previously allocated by a Golf statement.
Note that freeing memory is in most cases unnecessary as Golf will automatically do so at the end of each request. You should have a good reason for using delete-string otherwise.
Golf keeps count of <string> references for process-scoped memory (see memory-handling), and such memory will be deleted at the end of the request once reference count reaches zero.
For non-process-scoped memory, if <string> is referenced by other variables, then <string> may not be deleted. Regardless of whether the memory referenced by <string> is actually deleted or not, <string> becomes an empty string ("") after delete-string.
Allocate and free random string:
random-string to ran_str
...
delete-string ran_str
Copied!
Free string allocated by write-string (consisting of 100 "Hello World"s):
write-string ws
start-loop repeat 100
@Hello World
end-loop
end-write-string
...
delete-string ws
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Delete tree
Purpose: Delete a node from a tree.
delete-tree <tree> key <key> \
[ status <status> ] \
[ value <value> ] \
Copied!
delete-tree will search <tree> for string <key> and if found, delete its node (including the key in it), set <value> (in "value" clause) to node's value, and set <status> number (in "status" clause) to GG_OKAY. If <key> is not found, <status> will be GG_ERR_EXIST. If <status> is not GG_OKAY, <value> is unchanged.
Delete node with key "123", and obtain its value:
set-string k = "123"
delete-tree mytree key k value val status st
if-true st not-equal GG_OKAY
@Could not find key <<print-out k>>
exit-handler
end-if
@Deleted key <<print-out k>> with value <<print-out val>>
delete-string val
Copied!
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Derive key
Purpose: Derive a key.
derive-key <key> from <source> length <length> \
[ binary [ <binary> ] ] \
[ from-length <source length> ] \
[ digest <digest algorithm> ] \
[ salt <salt> [ salt-length <salt length> ] ] \
[ iterations <iterations> ]
Copied!
derive-key derives <key> from string <source> in "from" clause. If <source length> in "from-length" clause is specified, exactly <source length> bytes of <source> are used. Otherwise, the length of <source> string is used as the number of bytes (see string-length).
The desired length of derived key is given by <length> in "length" clause. The method for key generation is PBKDF2. By default the digest used is "SHA256". You can use a different <digest algorithm> in "digest" clause (for example "SHA3-256"). To see a list of available digests:
openssl list -digest-algorithms
Copied!
The salt for key derivation can be given with <salt> in "salt" clause. If "salt-length" clause is not specified, then the entire length of salt is used (see string-length), otherwise <salt length> bytes are used as salt.
The number of iterations is given by <iterations> in "iterations" clause. The default is 1000 per RFC 8018, though depending on your needs and the quality of <source> you may choose a different value.
By default, the derived key is produced in a hexadecimal form, where each byte is encoded as two-character hexadecimal characters, so its length is 2*<length>. If "binary" clause is used without boolean variable <binary>, or if <binary> evaluates to true, then the output is a binary string of <length> bytes.
Key derivation is often used when storing password-derivatives in the database (with salt), and also for symmetrical key generation.
Derived key is in variable "mk":
random-string to rs9 length 16
derive-key mk from "clave secreta" digest "sha-256" salt rs9 salt-length 10 iterations 2000 length 16
Copied!
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
Devel versus release
By default, when you make your application, a "devel" (or development) version is built, for instance:
gg -q
Copied!
You can also explicitly specify this:
gg -q --devel
Copied!
The development version of your application will not use all the compiler optimizations and it will not use the Link Time Optimizations (LTO), sometimes also referred to as "whole program optimization". So this version will exhibit lower run-time performance. However, it is also much faster to build and it includes additional debugging symbols as well.
When you wish to produce a release executable, use "--release" option, for instance:
gg -q --release
Copied!
This will include all the compiler optimizations as well as LTO; it will also include the minimal necessary debugging information. Release executables can be significantly faster than development ones; use them for releases as well as when you wish to do performance testing. Note however that making release executables will take significantly longer, so you probably do not want to do it while developing your application.
Note that if your gcc (C compiler) version changes, such as after system updates, Golf may recompile itself. This is because LTO works the best when Golf itself is compiled with the gcc version currently installed. During such rare occassions, Golf will need sudo privilege to install the recompiled executables.
General
about-golf
devel-versus-release
directories
permissions
See all
documentation
Directories
Application directory structure
This is the directory structure:
- $HOME/.golf/apps/<app name>/.bld
Build directory is where your application executables are built, with name <app name>.srvc for a service and <app name> for a command-line program. This is a scratch-pad directory, thus do not alter files in it, or use for anything else. It is created with 700 privileges.
- $HOME/.golf/apps/<app name>
Application directory. All application data is kept here. It is created with 711 privileges.
- $HOME/.golf/apps/<app name>/app
Application home directory. This is the current working directory when your application runs. Copy/move here any files and directories your application needs. It is created with 700 privileges.
- $HOME/.golf/apps/<app name>/file
This is file-storage used for uploads and new document creation. Do not write there directly; Golf does that for you, such as with uniq-file for instance, or when uploading files. It is created with 700 privileges.
- $HOME/.golf/apps/<app name>/trace
This is a trace directory that contains files describing fatal issues with your program(s); information contained in them can help you diagnose the issues and fix them. See debugging. It is created with 700 privileges.
- $HOME/.golf/apps/<app name>/db
Database configuration directory contains the database-config-files used by Golf to connect to databases; this directory is maintained by Golf and you should not use it. It is created with 700 privileges.
While Golf directories are fixed, you can effectively change their location by creating a soft link. This way, your directories and files can be elsewhere, even on a different disk. For example, to house your file storage on a different disk:
ln -s /home/disk0/file $HOME/.golf/apps/<app name>/file
Copied!
Directories
change-dir
change-mode
delete-dir
directories
new-dir
General
about-golf
devel-versus-release
directories
permissions
See all
documentation
Documentation
Reference for Golf version 3.3.0
Browse by topic: API, Application information, Array, Base64, Booleans, C language, Cookies, Database, Debugging, Directories, Distributed computing, Documentation, Encryption, Error handling, Examples, FastCGI client, FIFO, Files, General, Golf compiler and utility, Hash, Hex encoding, Install golf, JSON parsing, Language, License, LIFO, Linked list, Memory, Messages, Numbers, Output, Program execution, Program flow, Quick start, Regex, Request data, Request information, Requests, Running application, SELinux, Service manager, Service processing, Strings, System information, Time, Tree, URL encoding, UTF, Web, Web encoding, Web servers, XML parsing
Golf documentation is available online, and also as man pages (i.e. manual pages). You can use 'man' to get help (if man program is available on your system), for instance:
man read-file
Copied!
Golf uses section 2gg of man, so you can also use (in case of conflicts):
man 2gg read-file
Copied!
If man program is not available on your system, you can also view topics with 'gg --man <topic>', for example:
gg --man run-query
Copied!
To show all topics, type:
gg --man all
Copied!
Do once
Purpose: Execute statements only once in a process.
do-once
<any statements>
...
end-do-once
Copied!
do-once will execute <any statements> only once in a single process regardless of how many requests that process serves. <any statements> end with end-do-once. The first time a process reaches do-once, <any statements> will execute; in all subsequent cases the program control will skip to immediately after end-do-once.
do-once cannot be nested, but otherwise can be used any number of times.
Typical use of do-once may be making any calls that need to be performed only once per process, or it may be a one-time setup of process-scoped variables, or anything else that needs to execute just once for all requests served by the same process.
<any statements> execute in the nested scope relative to the code surrounding do-once/end-do-once, except that any process-scoped variables are created in the same scope as the code surrounding do-once/end-do-once; this simplifies creation of process-scoped variables, if needed.
In this example, a process-scoped hash (that is available to multiple requests of a single process) is created in the very first request a process serves and data is written to it; the subsequent requests do not create a new hash but rather just write to it.
...
do-once
new-hash my_hash hash-size 1024 process-scope
end-do-once
write-hash my_hash key my_key value my_data
...
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Encode base64
Purpose: Base64 encode.
encode-base64 <data> to <output data> \
[ input-length <input length> ]
Copied!
encode-base64 will encode string <data> into base64 string <output data>.
If "input-length" clause is used, then <input length> is the number of bytes encoded, otherwise the entirety of <data> is encoded.
The result is stored in <output data> (in "to" clause).
Base64-encoded strings are often used where binary data needs to be in a format that complies with certain text-based protocols, such as in attaching documents in email, or embedding binary documents (such as "JPG" images for example) in web pages with "data:image/jpg;base64..." specified, etc.
An example that encodes a string, decodes, and finally checks if they match:
set-string dt =" oh well "
encode-base64 dt to out_dt
decode-base64 out_dt to new_dt
if-true dt equal new_dt
@Success!
else-if
@Failure!
end-if
Copied!
In the next example, "input-length" clause is used, and only a partial of the input string is encoded, then later compared to the original:
set-string dt =" oh well "
encode-base64 dt input-length 6 to out_dt
decode-base64 out_dt to new_dt
string-length new_dt to new_len
if-true new_len not-equal 6
@Failure!
else-if
@Success!
end-if
if-true dt equal new_dt length new_len
@Success!
else-if
@Failure! [<<print-out dt>>] [<<print-out new_dt>>]
end-if
Copied!
Base64
decode-base64
encode-base64
See all
documentation
Encode hex
Purpose: Encode data into hexadecimal string.
encode-hex <data> to <output> \
[ input-length <input length> ] \
[ prefix <prefix> ]
Copied!
encode-hex will encode string <data> to hexadecimal string <output> given in "to" clause which consists of digits "0"-"9" and letters "a"-"f".
The length of <data> to encode may be given with <input length> number in "input-length" clause; if not the whole string <data> is used. If you wish to prefix the output with a string <prefix>, you can specify it in "prefix" clause with <prefix>; otherwise no prefix is prepended.
Create hexadecimal string from binary data "mydata" of length 7, prefixed with string "\\\\x" (which is typically needed for PostgreSQL binary input to queries). The output string "hexout" is created:
set-string mydata = "\x00""A""\x00""\x0F""AB""\x00""\x04"
encode-hex mydata to hexout input-length 7 prefix "\\\\x"
Copied!
The value of "hexout" will be:
\\x0041000F414200
Copied!
Hex encoding
decode-hex
encode-hex
See all
documentation
Encode url
Purpose: URL-encode string.
encode-url <string> to <encoded string> \
[ input-length <length> ]
Copied!
encode-url URL-encodes <string> and stores the result in <encoded string>.
<length> in "input-length" clause lets you specify the number of bytes in <string> that will be encoded - if not specified or negative, it is the string length.
All bytes except alphanumeric and those from "-._~" (i.e. dash, dot, underscore and tilde) are encoded.
In this example, a string "str" is URL encoded and the result is in a "result" string variable:
set-string str=" x=y?z& "
encode-url str to result
Copied!
The "result" is "%20%20x%3Dy%3Fz%26%20%20".
URL encoding
decode-url
encode-url
See all
documentation
Encode web
Purpose: Web(HTML)-encode string.
encode-web <string> to <encoded string> \
[ input-length <length> ]
Copied!
encode-web encodes <string> so it can be used in a HTML-like markup text (such as a web page or an XML/XHTML document), and stores the result in <encoded string>.
You can encode only the first <length> bytes, given by "input-length" clause.
In this example, a string "str" will be web-encoded and the result is in "result" variable:
set-string str=" x<y>z&\"' "
encode-web str to result
Copied!
The "result" is " x<y>z&"' ".
Web encoding
decode-web
encode-web
See all
documentation
Encrypt data
Purpose: Encrypt data.
encrypt-data <data> to <result> \
[ input-length <input length> ] \
[ binary [ <binary> ] ] \
( password <password> \
[ salt <salt> [ salt-length <salt length> ] ] \
[ iterations <iterations> ] \
[ cipher <cipher algorithm> ] \
[ digest <digest algorithm> ]
[ cache ]
[ clear-cache <clear cache> ) \
[ init-vector <init vector> ]
Copied!
encrypt-data encrypts <data> and stores the ciphertext to <result> specified by "to" clause.
By default, AES-256-CBC encryption and SHA256 hashing is used. You can however specify different cipher and digest algorithms with <cipher algorithm> (in "cipher" clause) and <digest algorithm> (in "digest" clause) as long as OpenSSL supports them, or you have added them to OpenSSL. You can see the available ones by using:
openssl list -cipher-algorithms
openssl list -digest-algorithms
Copied!
Note that the default algorithms will typically suffice. If you use different algorithms, you should have a specific reason. If you use a specific cipher and digest for encoding, you must use the same for decoding. The key derivation method is PBKDF2.
If "input-length" clause is missing, then the number of bytes encrypted is the length of <data> (see string-length). If "input-length" clause is used, then <input length> bytes are encrypted.
String <password> (in "password" clause) is the password used to encrypt and it must be a null-terminated string.
String <salt> (in "salt" clause) is the salt used in Key Derivation Function (KDF) when an actual symmetric encryption key is created. If <salt length> (in "salt-length" clause) is not specified, then the salt is null-terminated, otherwise it is a binary value of length <salt length>. See random-string or random-crypto for generating a random salt. If you use the "salt" clause, then you must use the exact same <salt> when data is decrypted with decrypt-data - typically salt values are stored or transmitted unencrypted.
The number of iterations used in producing a key is specified in <iterations> in "iterations" clause. The default is 1000 per RFC 8018, though depending on your needs and the quality of password you may choose a different value.
Initialization vector (IV)
The encrypted data is stored in <result> (in "to" clause). The encrypted data can be a binary data (if "binary" clause is present without boolean variable <binary>, or if <binary> evaluates to true), which is binary-mode encryption; or if not, it will be a null-terminated string, which is character-mode encryption, consisting of hexadecimal characters (i.e. ranging from "0" to "9" and "a" to "f"). Character mode of encryption is convenient if the result of encryption should be a human readable string, or for the purposes of non-binary storage in the database.
A key used to actually encrypt/decrypt data is produced by using password, salt, cipher, digest and the number of iterations. Depending on these parameters (especially the number of iterations), computing the key can be a resource intensive and lengthy operation. You can cache the key value and compute it only once (or once in a while) by using "cache" clause. If you need to recompute the key once in a while, use "clear-cache" clause. <clear cache> is a "bool" variable; the key cache is cleared if it is true, and stays if it is false. For example with encrypt-data (the same applies to decrypt-data):
set-bool clear = true if-true q equal 0
encrypt-data dt init-vector non password pwd \
salt rs salt-length 10 iterations iter to \
dt_enc cache clear-cache clear
Copied!
In this case, when "q" is 0, cache will be cleared, with values of password, salt and iterations presumably changed, and the new key is computed and then cached. In all other cases, the last computed key stays the same. Normally, with IV usage (in "init-vector" clause), there is no need to change the key often, or at all.
Note that while "cache" clause is in effect, the values for "password", "salt", "cipher", "digest" and "iterations" clauses can change without any effect. Only when "clear-cache" evaluates to "true" are those values taken into account.
Unless you are encrypting/decrypting a single message, you should always use IV in "init-vector" clause. Its purpose is to randomize the data encrypted, so that same messages do not produce the same ciphertext.
If you use salt, a random IV is created with each different salt value. However, different salt values without "cache" clause will regenerate the key, which may be computationally intensive, so it may be better to use a different IV instead for each new encryption and keep the salt value the same with the high number of iterations. In practicality this means using "cache" so that key is computed once per process with the salt, and IV changes with each message. If you need to recompute the key occasionally, use "clear-cache".
Each cipher/digest combination carries separate recommendations about the usage of salt, IV and the number of iterations. Please consult their documentation for more details.
In the following example, the data is encrypted, and then decrypted, producing the very same data:
set-string orig_data="something to encrypt!"
encrypt-data orig_data password "mypass" to res
decrypt-data res password "mypass" to dec_data
if (!strcmp (orig_data, dec_data)) {
@Success!
} else {
@Failure!
}
Copied!
A more involved example below encrypts specific number of bytes (6 in this case). random-string is used to produce salt. The length of data to encrypt is given with "input-length" clause. The encrypted data is specified to be "binary" (meaning not as a human-readable string), so the "output-length" of such binary output is specified. The decryption thus uses "input-length" clause to specify the length of data to decrypt, and also "output-length" to get the length of decrypted data. Finally, the original data is compared with the decrypted data, and the length of such data must be the same as the original (meaning 6):
set-string orig_data="something to encrypt!"
random-string to newsalt length 8 binary
encrypt-data orig_data input-length 6 output-length encrypted_len password "mypass" salt newsalt to res binary
decrypt-data res output-length decrypted_len password "mypass" salt newsalt to dec_data input-length encrypted_len binary
if (!strncmp(orig_data,dec_data, 6) && decrypted_len == 6) {
@Success!
} else {
@Failure!
}
Copied!
An example of using different algorithms:
encrypt-data "some data!" password "mypwd" salt rs1 to encd1 cipher "camellia-256-cfb1" digest "sha3-256"
decrypt-data encd1 password "mypwd" salt rs1 to decd1 cipher "camellia-256-cfb1" digest "sha3-256"
Copied!
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
Error code
Many Golf statements return status with GG_ERR_... error codes, which are generally descriptive to a point. Such status may not as detailed as the operating system "errno" variable, however you can use "errno" clause in get-req statement to obtain the last known errno value from aforementioned statements. You should obtain this value as soon as possible after the statement because another statement may set it afterwards.
In the following example, a directory is attempted to be deleted via delete-file, which will fail with GG_ERR_DELETE - however you can get a more specific code via "errno" (which in this case is "21", or "EISDIR", which means that it cannot delete a directory with this statement):
delete-file "some_directory" status stc
if-true stc equal GG_ERR_DELETE
get-req errno to e
@Cannot delete file
print-format "Error %ld\n", e
end-if
Copied!
Note that with some GG_ERR_... codes, the "errno" clause in get-req may return 0. This means the error was detected by Golf and not reported by the operating system.
You can use standard Linux constants, as defined in C "errno.h" include file to compare the error code obtained with get-req. For instance, you can use constants like EACCES or EEXIST. To see what's the meaning of errno number or name, use standard Linux utility "errno".
Error handling
db-error
error-code
error-handling
report-error
See all
documentation
Error handling
When your program errors out
- Skip the rest of the request, and move on quickly to handle the next request without exiting. Most errors are like this, for example your program has attempted to access memory outside of what's allocated, or you have called report-error statement.
- Stop and exit, and it may be automatically restarted if it's a service. For instance, the process could be out of memory, or the database is permanently down and connection cannot be re-established, or there is an internal error.
.
Note that if your program is command-line, it will exit in any case since it handles a single request anyway.
When there is a problem in Golf
Regardless of the type of error and regardless of whether the process exits or not, the error is output to the standard error stream along with the error details: cause of error and full stack trace (including source file names and line numbers); note that for report-error error details are not output since you're providing your own details.
Output when error happens
Error handling
db-error
error-code
error-handling
report-error
See all
documentation
Golf examples
Updated on 2025-09-12. Always use the latest Golf version to run these examples.
- How to get the web page source code programmatically
Fetching a web resource (including web page source) is a one-liner in Golf. First, create a new application ("get-page" here): ...
- More than one table in a database transaction in PostgreSQL
Here you'll learn how to use a database transaction to insert/update into multiple tables; so that if any of those fail, the entire transaction is cancelled (rollbacked), and if they all succeed, the transaction is committed as a whole, atomically. ...
- Introduction to Golf
Golf is a new programming language and framework for developing web services and web applications. It is: ...
- Random numbers in Golf
Generating random numbers is important in a wide range of applications. For instance, session IDs often use random numbers; they are also used in generating passwords; another example is load balancing where (say instead of round-robin), the next available process to serve a request is chosen randomly; some applications (like gambling) depend on random qualities; any kind of simulation would heavily rely on random numbers; financial and polling applications use random samples to determine outcomes and policies. The list of possible uses is pretty long. ...
- More than one table in a database transaction in SQLite
Here you'll learn how to use a database transaction to insert/update into multiple tables; so that if any of those fail, the entire transaction is cancelled (rollbacked), and if they all succeed, the transaction is committed as a whole, atomically. ...
- Statements in Golf
Golf is a new programming language and framework for developing web services and web applications. The reason for Golf is to make software development easier and more reliable. ...
- How to write distributed applications
Distributed computing is two or more servers communicating for a common purpose. Typically, some tasks are divvied up between a number of computers, and they all work together to accomplish it. Note that "separate servers" may mean physically separate computers. It may also mean virtual servers such as Virtual Private Servers (VPS) or containers, that may share the same physical hardware, though they appear as separate computers on the network. ...
- What is web service
Web service is code that responds to a request and provides a reply over HTTP protocol. It doesn't need to work over the web, despite its name. You can run a web service locally on a server or on a local network. You can even run a web service from command line. In fact, that's an easy way to test them. ...
- Using Vim color schemes with Golf
Golf installation comes with a Vim module for highlighting Golf code. After installing Golf, run this to install the Vim module: ...
- Hello World in Golf
Create a directory for your Hello World application and then switch to it: ...
- Memory safety: what about performance?
Memory safety guards against software security risks and malfunctions by assuring data isn't written to or read from unintended areas of memory. Preventing leaks is a separate feature that's important for web services which are long-running processes - memory leaks usually lead to running out of memory and crashes. ...
- Web services with MariaDB
Create a directory for your project, it'll be where this example takes place. Also create Golf application "stock": ...
- Cache server in 30 lines
This is a cache server that can add, delete and query key/value pairs, with their number limited only by available memory. ...
- Using Regex in Golf
Regex (or "REGular EXpressions") is a powerful way to search strings, as well as to replace parts of strings. It makes it easier to reliably do so, since regular expressions are usually short; at the same time there's a learning curve in becoming proficient. However, given that regex is ubiquitous, it is worth learning at least some of it, as it can come handy. ...
- Functions and parameters in Golf
In Golf, there are no "functions" or "methods" as you may be used to in other languages. Any encapsulation is a request handler - you can think of it as a simple function that executes to handle a request - it can an external request (i.e. from an outside caller such as web browser, web API, or from a command-line), or internal requests from another handler in your application. ...
- Fast JSON parser with little coding
Golf's JSON parser produces an array of name/value pairs. A name is a path to value, for instance "country"."state"."name", and the value is simply the data associated with it, for instance "Idaho". You can control if the name contains array indexes or not, for instance if there are multiple States in the document, you might have names like "country"."state"[0]."name" with [..] designating an array element. ...
- How to build a Web Service API
This article will show a simple shopping web API with basic functions, such as adding customers, items and orders, as well as updating and deleting them. It's easy to write and easy to understand with Golf; that's the reason code doesn't have much in a way of comments - there's no need. ...
- Golf is a different kind of programming language
Over the past 50 years, general-purpose programming languages became more complex due to the constant influx of new features (some of which are great, while others are a "feature creep"). Just look at any major programming language in its early days, versus the latest incarnations. From a distance, it may look like you switched from riding a bicycle to flying a passenger jet with a few hundred knobs, buttons and readout consoles. Arguably, the language structure covers many more usage patterns, yields additional power and safety has improved, but the complexity and the learning curve has increased too. While in the beginning there was lots of pitfalls due to the lack of features and safety, which would usually result in too many ways of doing the same thing, in the end there's a minefield due to an overcrowded feature-scape that's paralyzing to deal with and often not quite understood by anyone on the team. ...
- Web file manager in less than 100 lines of code
Uploading and download files in web browser is a common task in virtually any web application or service. This article shows how to do this with very little coding - in less than 100 lines of code. The database used is PostgreSQL, and the web server is Nginx. ...
- How to debug Golf programs with gdb
Debugging information is always included regardless of how you make your application; what varies is the amount of debugging info included. You can compile your Golf application normally: ...
- Cookies in Golf applications, plus HAProxy
Cookies are used in web development to remember the state of your application on a client device. This way, your end-user on this client device doesn't have to provide the same (presumably fairly constant) information all the time. A "client device" can be just a plain web browser, or it can be anything else, such as any internet connected device. ...
- More than one table in a database transaction in MariaDB
Here you'll learn how to use a database transaction to insert/update into multiple tables; so that if any of those fail, the entire transaction is cancelled (rollbacked), and if they all succeed, the transaction is committed as a whole, atomically. ...
- How is memory organized in Golf
Golf is a memory-safe language. A string variable is the actual pointer to a string (whether it's a text or binary). This eliminates at least one extra memory read. Bytes before the string constitute the ID to a memory table entry as well as the length of a string, with additional info used by memory-safety mechanisms: ...
- Cache as a web service
This example shows Apache as the front-end (or "reverse proxy") for article-tree - it's assumed you've completed it first. Three steps to setting up Apache quickly: ...
- Multi-tenant SaaS (Notes web application) in 200 lines of code
This is a complete SaaS example (Software-as-a-Service) using PostgreSQL as a database, and Golf as a web service engine; it includes user signup/login/logout with an email and password, separate user accounts and data, and a notes application. All in about 200 lines of code! Here's a video that shows it - two users sign up and create their own notes. ...
- Web framework for C programming language
Golf has an "extended" mode, which allows for C code to be used directly. Normally, this is not allowed, but if you use extended-mode statement in your .golf file, then you can call C code from it. ...
- Encryption: ciphers, digests, salt, IV and a hands-on guide
Encryption is a method of turning data into an unusable form that can be made useful only by means of decryption. The purpose is to make data available solely to those who can decrypt it (i.e. make it usable). Typically, data needs to be encrypted to make sure it cannot be obtained in case of unauthorized access. It is the last line of defense after an attacker has managed to break through authorization systems and access control. ...
- What is an application server
Every Golf application is built as both an application server and a command-line program. You can use both, depending on what's the nature of your application. Some programs are meant to be used in scripts, or executed directly from command line. Others need to stay in memory and execute user requests as servers. The nice thing is that they both work the same, meaning you can run from command line anything that an application server does, and vice versa. This is also handy for testing; it makes writing tests for an application server much easier because you can run such tests in a plain bash script. ...
- Web service Hello World
To access a Golf service on the web, you need to have a web server or load balancer (think Apache, Nginx, HAProxy etc.). ...
- Use C language API to talk to Golf Server
Golf application server can be accessed via C API. Most programming languages allow for C linkage, so this makes it easy to talk to Golf server from anywhere. The Client-API is very simple with just a few functions and a single data type. It's also MT-safe (i.e. safe for multi-threaded applications). ...
- First In First Out (FIFO) example
Golf has built-in FIFO list type. You can create a FIFO variable and then store key/value string pairs in it, which you can then read back in the order you put them in. You can also rewind the FIFO list and obtain the same key/value pairs over and over again if needed. ...
- Example of auto status checking with Golf
When talking about safety in programming, it is memory safety that usually takes the spotlight. However, here we'll touch on another common safety issue that typically causes application logic errors, meaning your program won't function correctly. It's about checking the status of any kind of statement that provides it. Not checking the status could mean that the result of a statement isn't correct, yet your program is proceeding as if it were. Of course, this is bound to cause problems, and this is true for any programming language. ...
- 34000 requests per second on a modest laptop
Here's a video showing how to create and start an application server, and how to connect to it and make requests from a C client (or from any language that supports C API extension), you can watch a video here. ...
- How to create a Golf application
To create a Golf application, use "-k" option of gg utility: ...
- Hello World as a Service
Writing a service is the same as writing a command-line program in Golf. Both take the same input and produce the same output, so you can test with either one to begin with. ...
- How to send email with Golf
This example shows how to send email with Golf. The web service you'll create here is very simple and it will display an HTML form to collect info needed to send email, such as "From" and "To" (the sender and the recipient emails), the Subject and of course the Message itself. Once user clicks Submit, email is sent. ...
- Security of web services
The security of web services is a broad subject, but there are a few common topics that one should be well aware. They affect if your web application, or an API service, will be a success or not. ...
- SQLite with Golf
This example will create a service that inserts key and value into SQLite table. It's tested from command line. ...
- Call web service from web service: stacking them up
A web service doesn't necessarily need to be called from "the web", meaning from the web browser or via API across the web. It can be called from another web service that's on a local network. ...
Examples
examples
See all
documentation
Exec program
Purpose: Execute a program.
exec-program <program path> \
[ args <program arg> [ , ... ] ] \
[ status <exit status> ] \
[ ( input <input string> [ input-length <string length> ] ) \
| ( input-file <input file> ) ] \
[ ( output <output string> ) \
| ( output-file <output file> ) ] \
[ ( error <error string> ) | ( error-file <error file> ) ]
Copied!
exec-program executes a program specified in <program path>, which can be a program name without path that exists in the path specified by the PATH environment variable; or an absolute path; or a path relative to the application home directory (see directories).
A program can have input arguments (specified as strings with "args" clause), and if there are more than one, they must be separated by a comma. There is no limit on the number of input arguments, other than of the underlying Operating System.
You can specify a status variable <exit status> - this variable will have program's exit status. Note that if the program was terminated by a signal, <exit status> will have a value of 128+signal_number, so for example if the program was terminated with signal 9 (i.e. KILL signal), <exit status> will be 137 (i.e. 128+9). Any other kind of abnormal program termination (i.e. program termination where program did not set the exit code) will return 126 as <exit code>.
Specifying program input and output is optional. If program has output and you are not capturing it in any way, the output is redirected to a temporary file that is deleted after exec-program completes.
You can specify an <input string> to be passed to program's standard input (stdin) via "input" clause. If "input-length" is not used, the length of this input is the string length of <input string>, otherwise <string length> bytes is passed to the program. Alternatively, you can specify a file <input file> (via "input-file" clause) to be opened and directed into program's standard input (stdin).
You can redirect the program's output (which is "stdout") to a file <output file> using "output-file" clause. Alternatively, program's output can be captured in <output string> (via "output" clause).
To get the program's error output (which is "stderr") to file <error file>, use "error-file" clause. Alternatively, program's error output can be captured in <error string> (via "error" clause).
If <input file> cannot be opened, GG_ERR_READ is reported in <exit status>, and if either <output file> or <error file> cannot be opened, the status is GG_ERR_WRITE.
Note that in general a program is considered successfully executed if it returns GG_OKAY (i.e. zero). Most programs returning non-zero value mean failure.
To simply execute a program that is in the path, without any arguments, input or output:
exec-program "myprogram"
Copied!
Run "grep" program using a string as its standard input in order to remove a line that contains "bad line" in it, and outputting the result into "ovar" variable:
exec-program "grep" args "-v", "bad line" "config" input "line 1\nline 2\nbad line\nline 3" output ovar
print-out ovar
Copied!
Get the list of files in the application home directory into buffer "ovar" and then display it:
exec-program "ls" output ovar
Copied!
Similar to the above example of listing files, but output results to a file (which is then read and the result displayed), and provide options "-a -l -s" to "ls" program:
exec-program "ls" args "-a", "-l", "-s" output-file "lsout"
read-file "lsout" to final_res
print-out final_res
Copied!
Count the lines of file "config" (which is redirected to the standard output of "wc" program) and store the result in variable "ovar" (by means of redirecting the output of "wc" program to it), and then display:
exec-program "wc" args "-l" input-file "config" output ovar
print-out ovar
Copied!
Program execution
exec-program
exit-status
See all
documentation
Exit handler
Purpose: Exit current request processing.
exit-handler [ <request status> ]
Copied!
Exits current request by transferring control directly after the top-level request dispatcher. If there is an after-handler, it will still execute, unless exit-handler is called from before-handler.
<request status> number is a request status returned to the caller; if not specified, then it's the value specified in the last executed exit-status statement; if none executed in the request, then it's 0.
Returning status of 20:
begin-handler /req-handler public
...
exit-status 20
...
exit-handler
...
end-handler
Copied!
Returning status of 0:
begin-handler /req-handler public
...
exit-handler
...
end-handler
Copied!
Returning status of 10:
begin-handler /req-handler public
...
exit-handler 10
...
end-handler
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Exit status
Purpose: Set handler exit status.
exit-status <request status>
Copied!
exit-status specifies <request status>, which must be a number; this is the status that is passed out of the request to the external caller (see request and exit-handler).
<request status> can be obtained with "exit-status" clause in read-remote in the service caller; when the program runs as command-line, <request status> is program's exit code.
exit-status can be specified anywhere in the code, and does not mean exiting the request's processing; to do that, either use exit-handler or simply allow the handler to reach its end. If your program encounters difficulties and errors out, then the <request status> is always a fixed reserved value of 107, regardless of you setting it with exit-status.
When exit-status is not used, the default exit code is 0. When multiple exit-status statements run in a sequence, the request status is that of the last one that executes.
If you want to specify request status and exit request processing at the same time, use exit-handler.
When the program exits, its exit code will be 12:
exit-status 12
...
exit-handler
Copied!
Program execution
exec-program
exit-status
See all
documentation
Extended mode
Purpose: Use external libraries or C code with Golf.
extended-mode
Copied!
extended-mode, when specified as a very first statement in .golf source file, allows for use of call-extended statement.
extended-mode
begin-handler /my-handler public
...
call-extended factorial (10, &fact)
...
end-handler
Copied!
C language
call-extended
extended-mode
web-framework-for-C-programming-language
See all
documentation
File position
Purpose: Set a position or get a current position for an open file.
file-position file-id <file id> \
( set <position> ) | ( get <position> ) \
[ status <status> ]
Copied!
file-position will set or get position for a file opened with open-file, where <file id> is an open file identifier.
If "set" clause is used, file position is set to <position> (with 0 being the first byte).
If "get" clause is used, file position is obtained in <position> (with 0 being the first byte).
<status> number in "status" clause will be GG_OKAY if set/get succeeded, GG_ERR_OPEN if file not open, or GG_ERR_POSITION if not.
Note that setting position past the last byte of file is okay for writing - in this case the bytes between the end of file and the <position> are filled with null-bytes when the write operation occurs.
Open file "testwrite" and set file byte position to 100, then obtain it later:
open-file "testwrite" file-id nf
file-position file-id nf set 100
...
file-position file-id nf get pos
Copied!
See also open-file.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
File storage
Golf provides a file directory that you can use for any general purpose, including for storing temporary-files. This directory is also used for automatic upload of files from clients. It provides a two-tier directory system, with sub-directories automatically created to spread the files for faster access.
Files in Golf file directory are located in the sub-directories of:
$HOME/.golf/<app-name>/app/file
Copied!
If you wish to place this directory in another physical location, see gg.
You can create files here by means of uniq-file, where a new unique file is created - with the file name made available to you. This directory is also used for uploading of files from clients (such as web browsers or mobile device cameras) - the uploading is handled automatically by Golf (see get-param).
In general, a number of sub-directories is created within the file directory that contain files, which allows for billions of files to be kept. This scheme also allows for faster access to file nodes due to relatively low number of sub-directories and files randomly spread per each such sub-directory. The random spreading of files across subdirectories is done automatically.
Do not rename file names or sub-directory names stored under file directory.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
File uploading
Purpose: Upload a file to server.
See get-upload.
Files uploaded via any client (such as a browser, curl, call-web etc.) are obtained via get-upload.
Golf uploads files via HTML automatically, meaning you do not have to write any code for that specific purpose. An uploaded file will be stored in file-storage, with path and name of such a file generated by Golf to be unique. For example, a file uploaded might be named "$HOME/.golf/app_name/app/file/d0/f31881".
You can upload any number of files at the same time, i.e. in the same request. See "--maxupload" parameter in gg for the maximum file size allowed for file uploads.
For more details, see get-upload.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Finish output
Purpose: Finish the output.
finish-output
Copied!
finish-output will flush out and conclude all output (see output-statement). Any such output afterwards will silently fail to do so. As far as the client is concerned, all the output is complete.
This statement is useful when you need to continue work after the output is complete. For example, if the task performed is a long-running one, you can inform the client that the job has started, and then take any amount of time to actually complete the job, without worrying about client timeouts. The client can inquire about the job status via a different request, or be informed via email etc.
finish-output
Copied!
Output
finish-output
flush-output
output-statement
print-format
print-out
print-path
See all
documentation
Flush output
Purpose: Flush output.
flush-output
Copied!
Use flush-output statement to flush any pending output.
This can be useful if the complete output would take longer to produce and intermittent partial output would be needed.
In this case the complete output may take at least 20 seconds. With flush-output, the message "This is partial output" will be flushed out immediately.
@This is partial output
flush-output
sleep(20);
@This is final output
Copied!
Output
finish-output
flush-output
output-statement
print-format
print-out
print-path
See all
documentation
Get app
Purpose: Obtain data that describes the application.
get-app \
name | directory | file-directory |
( user-directory [ user <user> ] ) | \
( socket-file [ user <user> ] [ application <app> ] ) \
| db-vendor <database configuration> | upload-size \
| path | is-service | stack-depth \
to <variable>
Copied!
Application-related variables can be obtained with get-app statement. The following application variables can be obtained (they are all strings unless indicated otherwise):
- "name" returns the name of your application, as specified when created (see mgrg).
- "directory" is the directory where your application resides, i.e. the application home directory (see directories).
- "user-directory" is the user directory, i.e a directory that houses all applications that belong to the user (see directories). If "user" is not given, then user is the current Operating system user; otherwise user is <user>.
- "socket-file" is the socket-file used to communicate with an application (see new-remote, ggcli, Client-API). If neither "user" nor "application" subclauses are given, then user is current Operating system user and application is the currently running application. If "user" subclause is given, then user is <user>. If "application" subclause is specified, then application is <application>.
- "is-service" is a boolean variable that is true if your code is running as a service, or false if it is running as a command-line program.
- "file-directory" is the directory where Golf file storage system is, i.e. file-storage.
- "db-vendor" is the database vendor name of database given by <database configuration> (as used for example in run-query). You can use it to create database specific conditions. The database vendor name can be compared against predefined string constants GG_MARIADB (for MariaDB database), GG_POSTGRES (for Postgres database) and GG_SQLITE (for SQLite database).
- "path" is the leading path of the URL request that can be used to build web forms and links leading back to your application. It returns the same value as used in print-path before <request path> is appended.
- "stack-depth" is the maximum allowed stack depth for calling handlers, including recursion.
- "upload-size" is the maximum allowed size of an uploaded file - this is a number (see gg for setting this value).
Get the name of Golf application:
get-app name to appname
Copied!
Get the vendor of database db:
get-app db-vendor db to dbv
if-true dbv equal GG_POSTGRES
end-if
Copied!
Application information
get-app
set-app
See all
documentation
Get cookie
Purpose: Get cookie value.
get-cookie ( <cookie value> = <cookie name> ) ,...
Copied!
get-cookie obtains string <cookie value> of a cookie with the name given by string <cookie name>. A cookie would be obtained via incoming request from the client (such as web browser) or it would be set using set-cookie.
The value of cookie is stored in <cookie value>.
Cookies are often used to persist user data on the client, such as for maintaining session security or for convenience of identifying the user etc.
You can obtain multiple cookies separated by a comma:
get-cookie c = "mycookie", c1 = "mycookie1", c2="mycookie2"
Copied!
Get value of cookie named "my_cookie_name" - variable my_cookie_value will hold its value:
get-cookie my_cookie_value="my_cookie_name"
Copied!
Cookies
delete-cookie
get-cookie
set-cookie
See all
documentation
Get hash
Purpose: Get usage specifics for a hash.
get-hash <hash > [ length <length> ] [ hash-size <hash size> ] [ average-reads <reads> ]
Copied!
get-hash provides usage specifics of a <hash> (created by new-hash).
Use "length" clause to obtain its <length> (i.e. the number of elements stored in it), "hash-size" clause to obtain its <hash size> (i.e. the number of "buckets", or possible hash codes in the underlying hash table).
"average-reads" clause will obtain in <reads> the average number of reads (i.e. how many string comparisons are needed on average to find a key) multiplied by 100 (so if an average number of reads was 1.5, it will be 150).
This information may be useful in determining the performance of a hash, and whether resize-hash is indicated.
get-hash h length l hash-size s average-reads r
Copied!
Hash
get-hash
new-hash
purge-hash
read-hash
resize-hash
write-hash
See all
documentation
Get lifo
Purpose: Get information about linked list.
get-lifo <list> count <count>
Copied!
get-lifo will obtain information about LIFO <list> created with new-lifo.
<count> (in "count" clause) is the number of elements in the list.
Get the number of elements in list "mylist" in number "size":
get-list mylist count size
Copied!
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
Get list
Purpose: Get information about linked list.
get-list <list> count <count>
Copied!
get-list will obtain information about linked <list> created with new-list.
<count> (in "count" clause) is the number of elements in the list.
Get the number of elements in list "mylist" in number "size":
get-list mylist count size
Copied!
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
Get message
Purpose: Get string produced by writing a message.
get-message <message> to <string>
Copied!
get-message will create a <string> from <message> which must have been created with new-message. <string> can then be used elsewhere, for instance sent with a remote call (see run-remote), written to a file etc.
Once get-message is called, <message> is initialized as if it was just created with new-message without the "from" clause.
new-message msg
write-message msg key "key1" value "value1"
get-message msg to str
...
new-message new from str
read-message new key k value v
print-format "[%s] [%s]\n", k,v
Copied!
The result is:
[key1] [value1]
Copied!
Messages
get-message
new-message
read-message
SEMI
write-message
See all
documentation
Get param
Purpose: Get a parameter value.
get-param ( <name> [ type <type> ] [ default-value <value> ] ) , ...
Copied!
get-param stores a parameter value in variable <name>. A parameter is a name/value pair kept by Golf for each request. The parameter's name must match <name>. A parameter can be of any type. A parameter is set either:
If parameter is a string, it is trimmed for whitespaces (both on left and right). You can specify any number of parameters, separated by a comma.
By default, <name> is a string variable, unless <type> (in "type" clause) is specified. <type> can be "string" for a string variable (the default), "bool" for a boolean variable, "number" for a number variable, "string-array" for an array of strings, "number-array" for an array of numbers, "bool-array" for an array of booleans, "message" for a message variable, "split-string" for a split-string variable, "hash" for an hash variable, "tree" for an tree variable, "tree-cursor" for an tree cursor variable, "fifo" for a FIFO variable, "lifo" for a LIFO variable, "list" for a list variable, "file" for a file variable, and "service" for a service variable.
The value obtained with get-param is checked to be of the proper <type>, and if it isn't, your request will error out. The exception to this is that a string parameter can be converted into a number or a boolean, assuming the string value represents a valid number or is "true"/"false"; this exception is for request URL parameters only. Parameters of "number" and "bool" types are obtained by value, and others by reference. It means for instance, that you can pass a tree to call-handler and read and write nodes there, and such changes will be visible in the caller request.
If "default-value" clause is used, then <value> will be assigned to <name> variable if there is none provided. For example, if the caller does not specify the value for parameter <name>, then its value will be <value>; note that parameter must always have value so if none is provided and there is no default value specified, your program will error out. "default-value" can only be used with strings, numbers and booleans.
Input parameters from a caller
- File uploads
File uploads are handled as input parameters as well, see file-uploading.
- Web input parameters
As an example, for HTML form input parameters named "param1" with value "value1" and "param2" with value "value2":
<input type='hidden' name='param1' value='value1'>
<input type='hidden' name='param2' value='value2'>
Copied!
you can get these parameters and print out their values by using:
get-param param1, param2
Copied!
A request may be in the form of a web link URL, and getting the parameter values is the same:
http://<your web server>/<app name>/<request name>¶m1=value1¶m2=value2
Copied!
Setting parameters during request's execution
get-param par1
...
set-param par1="new value"
Copied!
In this case the value of an existing parameter "par1" is replaced with "new value". In the following code a new parameter is created, which can be retrieved later with get-param:
set-param par1="new value"
get-param par1
Copied!
See call-handler for more examples.
Duplicate input parameter names
http://<web address>/<app name>/<request name>?par=val1&par=val2
Copied!
the value of input parameter "par" is undefined. Do not specify multiple input parameters with the same name.
Request data
get-param
request-body
set-param
See all
documentation
Get req
Purpose: Obtain data that describes the input request.
get-req \
errno | error | cookie-count | cookie <cookie index> \
| arg-count | arg-value <arg index> \
| header <header> | referring-url | method \
| content-type | process-id | name \
| external-call | directory | source-file
to <variable>
Copied!
Information related to an input request can be obtained with get-req statement and the result stored into <variable> (in "to" clause). The following can be obtained (all are strings except where stated otherwise):
- "errno" obtains the integer value of operating system "errno" tied to a last Golf statement that can return a status code. The "errno" value is saved internally; and restored here. It means that if "errno" changed for whatever reason since such Golf statement (such as with call-extended), you will still obtain the correct value. See error-code for an example. Note that errno value is undefined if there is no error, and can be 0 if the error is reported by Golf and not by operating system.
- "error" returns the error message that correlates to "errno" value.
- "cookie-count" returns the number of cookies. This means any cookies received from the client plus any cookies added (with set-cookie) in the application minus any cookies deleted (with delete-cookie).
- "cookie" returns the cookie value specified by <cookie index> (a sequential number starting with 1 up to the number of cookies), for instance:
get-req cookie-count to cookie_c
start-loop repeat cookie_c use i
get-req cookie i to cookie_val
print-format "cookie %s\n", cookie_val web-encode
@<br/>
end-loop
Copied!
In this example, we get the number of cookies, and then print out each cookie value.
- "arg-count" is the number of input arguments to your application (passed from a program caller, see "-a" option in mgrg and "--arg" in gg).
- "arg-value" is the string value of a single element from the array of input arguments, specified by <arg_index>. This array is indexed from 1 to the value obtained by "arg-count". Here is an example of using arg-count and arg-value:
get-req arg-count to ac
print-format "Total args [%ld]", ac
start-loop repeat ac use i
get-req arg-value i to av
print-format "%s\n", av
end-loop
Copied!
This code will display the number of input arguments (as passed to main() function of your program, excluding the first argument which is the name of the program), and then all the arguments. If there are no arguments, then variable 'ac' would be 0.
- "header" is the value of HTTP request header <header> that is set by the client. For example, if the HTTP request contains header "My-Header:30", then hval would be "30":
get-req header "My-Header" to hval
Copied!
Note that not all HTTP request headers are set by the caller. For example, SERVER_NAME or QUERY_STRING are set by the web server, and to get such headers, use get-sys.
- "method" is the request method. This is a number with values of GG_GET, GG_POST, GG_PUT, GG_PATCH or GG_DELETE for GET, POST, PUT, PATCH or DELETE requests, respectively. If it is not any of those commonly used ones, then the value is GG_OTHER and you can use get-sys with "environment" clause to obtain "REQUEST_METHOD" variable.
- "content-type" is the request content type. It is a string and generally denotes the content type of a request-body, if included in the request. Common examples are "application/x-www-form-urlencoded", "multipart/form-data" or "application/json".
- "referring-url" is the referring URL (i.e. the page from which this request was called, for example by clicking a link).
- "directory" is the current working directory, which is by default the application home directory (see directories) and can be changed with change-dir. Note that maximum length of a directory path should not exceed 1024 bytes.
- "process-id" is the "PID" (process ID) number of the currently executing process, as a number.
- "external-call" is a boolean that is true if the call to the current request handler is from an external caller, or false if called from another handler.
- "source-file" is the name of the current source file (a string).
- "name" is the request name as specified in the request URL.
Get the process ID:
get-req process-id to pid
Copied!
Request information
get-req
See all
documentation
Get sys
Purpose: Obtain data that describes the system.
get-sys \
environment <var name> \
directory | os-name | os-version | os-user | os-dir \
to <variable>
Copied!
System-describing variables can be obtained with get-sys statement and the result stored into <variable>. The following system variables can be obtained:
- "environment" returns the name of a given environment variable <var name>. If this is a server program, then the environment passed from a remote caller (such as web proxy) is queried. If this is a command-line program, then the environment from the Operating System is queried. In the following example,the QUERY_STRING variable (i.e. the actual query string from URL) is obtained:
get-sys environment "QUERY_STRING" to qstr
Copied!
- "directory" is the execution directory of the command-line program, i.e. the current working directory when the program was executed. Note that Golf will change the current working directory immediately afterwards to the application home directory (see directories). You can use this clause to work with files in the directory where the program was started. If your program runs as a service, then "directory" clause always returns application home directory, regardless of which directory mgrg program manager started your application from.
- "os-user" is the name of Operating System user who is running your application.
- "os-dir" is the full path of home directory of Operating System user who is running your application.
- "os-name" is the name of Operating System.
- "os-version" is the version of Operating System.
Get the name of the Operating System
get-sys os-name to os_name
Copied!
System information
get-sys
See all
documentation
Get time
Purpose: Get time.
get-time to <time var> \
[ since-epoch ] \
|
(
[ timezone <tz> ] \
[ year <year> ] \
[ month <month> ] \
[ day <day> ] \
[ hour <hour> ] \
[ minute <minute> ] \
[ second <second> ] \
[ format <format> ] \
[ from-epoch <epoch time> ]
)
Copied!
get-time produces <time var> variable that contains string with current time by default (without "since-epoch" clause), or a number of seconds since the Epoch (1970-01-01 00:00:00 +0000 (UTC)) if "since-epoch" clause is used.
Without "since-epoch" clause
Use timezone to specify that time produced will be in timezone <tz>. For example if <tz> is "EST", that means Eastern Standard Time, while "MST" means Mountain Standard Time. The exact way to get a full list of timezones recognized on your system may vary, but on many systems you can use:
timedatectl list-timezones
Copied!
So for example to get the time in Phoenix, Arizona you could use "America/Phoenix" for <tz>. If timezone clause is omitted, then time is produced in "GMT" timezone by default. DST (Daylight Savings Time) is automatically adjusted.
Each variable specified with "year", "month", "day", "hour", "minute" or "second" is a time to be added or subtracted to/from current time (see above for what is "current" time). For example "year 2" means add 2 years to the current time, and "year -4" means subtract 4 years, whereas "hour -4" means subtract 4 hours, etc. So for example, a moment in time that is 2 years into the future minus 5 days minus 1 hour is:
get-time to time_var year 2 day -5 hour -1
Copied!
<format> allows you to get the time in any string format you like, using the specifiers available in C "strftime". For example, if <format> is "%A, %B %d %Y, %l:%M %p %Z", it will produce something like "Sunday, November 28 2021, 9:07 PM MST". The default format is "UTC/GMT" format, which for instance, is suitable for use with cookie timestamps, and looks something like "Mon, 16 Jul 2012 00:03:01 GMT".
With "since-epoch" clause
To get current time in "GMT" timezone, in a format that is suitable for use with set-cookie (for example to set expiration date):
get-time to mytime
Copied!
To get the time in the same format, only 1 year and 2 months in the future:
get-time to mytime year 1 month 2
Copied!
An example of a future date (1 year, 3 months, 4 days, 7 hours, 15 minutes and 22 seconds into the future), in a specific format (see "strftime"):
get-time to time_var timezone "MST" year 1 month 3 day 4 hour 7 minute 15 second 22 format "%A, %B %d %Y, %l:%M %p %Z"
Copied!
Get number of seconds sinc Jan 1, 1970:
get-time to mytime since-epoch
print-out mytime new-line
Copied!
Produce 2 days after Epoch time stamp of 489326400 (which is July 4th 1985 at noon), and then add 2 days to it:
get-time to mytime from-epoch 489326400 2 day
print-out mytime
Copied!
Time
get-time
pause-program
See all
documentation
Get tree
Purpose: Get information about a tree.
get-tree <tree> \
( count <count> ) | ( hops <hops> )
Copied!
get-tree provides information about <tree> (created by new-tree):
- <count> (in "count" clause) provides the number of keys (i.e. nodes) in the tree.
- <hops> (in "hops" clause) provides the number of nodes accessed to find a key in the last tree statement executed prior to get-tree. Note that <hops> is available only in debug Golf build (see installing from source); otherwise it is always zero.
Get the number of nodes (keys) in a tree:
new-tree mytree
...
get-tree mytree count c
Copied!
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Get upload
Purpose: Get information about file uploaded.
get-upload <param> local-file <local file> \
[ size <size> ] \
[ extension <extension> ] \
[ status <status> ] \
[ client-file <client file> ]
Copied!
When a file is uploaded by Golf via any client (such as a browser, curl, call-web etc.), you can obtain the full-path location in your local file system by using get-upload.
<param> is the name of the HTML parameter (in an HTML form used to upload the file, or otherwise specified in other clients such as curl or Golf's call-web).
<local file> (in "local-file" clause) is the full-path location of the local file (on your computer) where the file is uploaded (see file-storage).
<size> (in "size" clause) is the size (in bytes) of the file uploaded.
<extension> (in "extension" clause) is the extension of the file uploaded (such as ".jpg"), if any. Note that the extension is always lower case; also ".jpeg" is always abbreviated as ".jpg".
<status> (in "status" clause) is the status of upload; it is GG_OKAY if successful and GG_ERR_EXIST if not (most likely <param> parameter is not found, i.e. there was no file uploaded).
<client file> (in "client-file" clause) is the file name as given by the client.
For more details, see file-uploading.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Ggcli
Purpose: FastCGI client utility.
ggcli <address:port> | <Unix socket>
Copied!
ggcli will contact FastCGI server running on TCP/IP machine specified by <address:port>, where address can be an IP of the machine or its address, and port is the port number. For local sockets, use <Unix socket>, which is a file name of a socket used by the server; note you need to have proper permissions to access this socket file.
ggcli will send a request to the server, receive a reply and display it to standard output. Any errors are displayed to standard error stream.
Use standard environment variables in order to specify the details of the request. The environment variables recognized by ggcli are CONTENT_TYPE, CONTENT_LENGTH, REQUEST_METHOD, SCRIPT_NAME, PATH_INFO, QUERY_STRING (which are all standard HTTP CGI variables), as well as Golf's variable GG_SILENT_HEADER which is used to suppress header output (value of "yes" will do that).
The above variables are not explained here; you can find much about them in many other sources. Please note that if CONTENT_LENGTH is specified, then ggcli expect content data to be provided to its standard input.
You can see the examples of setting the above environment variables and the usage of ggcli if you use "-r" option of gg; if you skip "--exec" option, gg will display the settings and the usage of ggcli utility.
Note that you should be able to use ggcli when talking to any FastCGI server (such as PHP), not just Golf.
FastCGI client
ggcli
See all
documentation
Gg
Purpose: Golf general purpose utility: build, test, run, miscellaneous (pronounced "gigi").
gg <options>
Copied!
- -k <app name>
Create Golf application <app name> with default settings (see mgrg with "-i" option on creating applications with non-default settings). The default settings mean that your application is owned by the currently-logged on Operating System user (see "-u" option in mgrg), and that a Unix socket connecting to your application server isn't restricted by any group (see "-r" option in mgrg). You must have sudo privilege to create an application. This option does nothing if the application already exists. You can combine this option with "-q" to create and then build an application in the same step.
- -q Build Golf application from source code in the current directory. mgrg must run first in this directory with "-i" option to create the application. You must have at least one Golf source file (.golf file), with each such file implementing a single request handler. All application source files must be contained in a flat directory; however, each request handler can handle any hierarchical path, so your API can be fully hierarchical. On rare occassions when C compiler version changes, you'll need sudo privileges to recompile and install Golf's LTO objects.
The following options can be used when building an application:
- --db="<database vendor>:<db config file> ..."
Specify a list of databases used in your application. Each element of the list is <database vendor> (which is 'mariadb', 'postgres' or 'sqlite'), followed by a colon (:) and then <db config file>, where <db config file> is used to refer to a database in statements such as run-query.
Each <database vendor>:<db config file> is separated by a space. You can list any number of databases for use in your application. A file in current directory with name <db config file> must exist and contain the connection parameters for database access, and is copied to Golf's database configuration directory (see directories). See database-config-file for more details on the content of this file.
- --lflag=<linker flags>
If you wish to add any additional linker flags (such as any non-Golf libraries), specify them quoted under this option.
- --cflag=<C flags>
If you wish to add any additional C compiler (gcc) flags, specify them quoted under this option.
- --path=<application path>
This option lets you specify the application path for your request URLs. It is a leading path of a URL prior to request name and any parameters. If empty, the default is the application name preceded by a forward slash:
/<app name>
Copied!
- --maxupload=<max upload size>
Specify maximum upload size for a file (in bytes). The default is approximately 25MB.
- --client-timeout=<timeout>
Specify number of seconds that Golf server will wait for first data to arrive from a client after it connected. If the client doesn't send any data within <timeout> seconds after establishing the connection to Golf server, it will be disconnected.
- --max-errors=<max errors>
During building of C code precompiled from .golf source code, gcc will emit a maximum of <max errors> diagnostic messages per .golf source file. The default is 5. Note that Golf precompiler stops after the first error in most cases and this setting doesn't apply to it.
- --devel
"--devel" will not use all of the compile-time optimizations and will not use any link-time optimizations (LTO). This is the default when developing applications. Use "--release" option when you want to create release executables, which typically exhibit considerably higher performance (thus always use "--release" when testing performance or for release). Note that compiler debugging information is always included, though with this option more of it is present.
- --release
This will include all optimizations, including LTO. Use when you wish to build release executables, for performance testing etc. Applications made with "--release" typically exibit better performance, sometimes 2 times faster or more. Note that compiler debugging information is still included regardless, because it enables basic debugging even for release executables and does not affect run-time performance. Making an application with "--release" can be considerably slower; because of that, during the development you'd probably not use this option.
- --c-lines
Skip generating line information when compiling .golf files. By default line information is included, which allows errors to be reported with line numbers in .golf files. If you want only generated C code line numbers to be used, use this option. This is mostly useful if you think you found a bug in Golf in order to pinpoint the issue.
- --public
Change the default behavior of request handler safety so that request handlers without "public" or "private" clause are by default "public"; see begin-handler for more details.
- --single-file
A request handler is written in a source file whose path matches fully or partially that of the request, and such a file can contain any number of request handlers that match, see request. If, however "--single-file" is used, each request has to be in its own file whose path matches fully the request path, and no other request can be implemented in such file. For example, with "--single-file", request "/myreq" has to be in file "myreq.golf" in the source directory, while request "/other/newreq" has to be in file "other/newreq.golf" (meaning in file "newreq.golf" in subdirectory "other" in the source directory).
- --exclude-dir
By default, all ".golf" files (including in all subdirectories regardless of how many levels there may be), are picked up for compilation. If "--exclude-dir" is used, then you can specify any number of subdirectories, separated by commas, to be excluded.
- --ignore-warn
Do not display any warnings during compilation of a Golf application.
- --verbose
Display more detailed information about the making of your application.
- --parallel=<threads>
Use <threads> number of threads to compile application. By default, the number of threads is equal to the number of CPUs (including virtual), allowing each CPU to compile one source files at a time; this is usually the fastest way. You can serialize compilation with "--parallel=1"; or you can set <threads> to any number between 1 and three time the number of CPUs in order to reach your performance and CPU utilization goals.
- --posix-regex
Use ERE (Extended Regular Expression) POSIX regex library built into Linux instead of default PCRE2, see match-regex. While the two are largely compatible, you can use either one depending on your needs.
- -c,--clean
Clean all object and other intermediate files, so that consequent application build is a full recompilation. Use it alone and prior to rebuilding the application.
Note that when any gg compilation options change, the application is rebuilt (i.e. the change has the effect of "--clean").
- -i
Display both include and linking flags for an application that uses Client-API to connect to Golf service. The flags are for C compiler (gcc). If "--include" option is used in addition, then only include flags are displayed. If "--link" option is used in addition, then only linking flags are displayed. Use this to automate building of client applications with tools like Makefile.
- -v
Display Golf version as well as the Operating System version.
- -s
Trace the execution of gg utility and display all the steps in making your application.
- -e <number of stack traces>
Display the last <number of stack traces>, i.e. the most recent stack trace files, which receive stack traces when program errors out, such as for instance due to your program attempting to access memory outside of it (but not for report-error statement). See error-handling.
- -o
Show documentation directory - web page documentation is located here in the form of a golfdoc.html file.
- -g
Show Golf root directory (i.e. where Golf is installed, see directories).
- -l
Show library directory - Golf's libraries and v1 code processor are located there.
- -p <app name> --version <version> [ --force-user ]
Create application package file for application <app name>, which can be used to install the application on a different computer; such computer must have a compatible Operating System (the same Linux distribution and the same or higher minor version number) and the compatible version of Golf must be installed (the same major and the same or higher minor version number). <version> is your application's version number, which is assigned by you. If "--force-user" is used, then this application, when installed elsewhere, must be installed into Operating System user account with the same user name as the current user when package is created.
Note that packaging an application will transfer all that's necessary for your application to run elsewhere (executables, database configuration files, the information about which libraries are required etc.). It does not (and cannot) deal with your own infrastructure, such as for example your own actual databases; those external dependencies are your responsibility.
If you have client applications built (see Client-API), you can copy their built executables as-is to a target machine, provided above versioning rules are observed and no extra libraries were linked with it. This is because Golf client executables do not have any external dependencies, other than any that you introduce (by linking with additional external libraries).
Note that if your application uses databases, check database files (specified in "--db" option when your application is built), and blank out any database passwords you do not wish packaged. You should use passwordless database authentication or "dummy" passwords on the development and testing sites and never actual production passwords.
The result of packaging is a file <app name>.tar.gz which you can use elsewhere with "-a" option to install the application; you can rename this file as long as it remains with ".tar.gz" extension.
- -a <packaged .tar.gz file> [ --downgrade ] [ --all ]
Installs your application on a different computer from a file created with "-p" option (i.e. <packaged .tar.gz file>). If "-all" is used, then all required tool kit libraries are installed automatically; otherwise you'd need to install them yourself. If "--downgrade" is used, then the installer will allow you to install a lower version of your application; normally that's not allowed. Note that same version of Golf must be installed prior to installing any applications (see "-p" option).
If you do not plan to build any other Golf applications on this target computer, you can uninstall gcc and make after Golf is installed.
Note that if your application uses databases, check database files located in $HOME/.golf/apps/<app name>/db/ (where <app name> is your application name), and review/update them for the application deployment site.
- -r [ --req="/<request name>[<url parameters>]"
[ --app="application path" ]
[ --service [ --remote="server:port" ] [ --socket="socket path" ] ]
[ --method="<request method>" ]
[ --content="<input file>" --content-type="<content type>" ]
[ --silent-header ]
[ --arg="<arguments>" ]
[ --exec ]
Run a command-line program, or make a service request, or display bash code to do the same for use in scripts.
If you are not in application's source code directory, then you must specify "--app" option to supply the application path (typically "/<application name>", see request). You can use "--req" option to specify the request name and optional URL parameters (see request), for example it may be:
gg -r --req="/encrypt" --exec
Copied!
to execute request "encrypt", or
gg -r --req="/encrypt/data=somedata?method=aes256" --exec
Copied!
where "/encrypt" is the request name, and "/data=somedata?method=aes256" represents the URL parameters.
Use --method to specify the HTTP request method, for instance:
gg -r --req="/encrypt/data=somedata?method=aes256" --method=POST --exec
Copied!
If not specified, the default method is "GET".
If "--service" is not used, then command-line program will execute and you can specify program arguments with "--arg" option, in which case "<arguments>" is a string (double or single quoted) that contains any number of program arguments. To specify arguments for a service see "-a" option in mgrg.
If "--service" is used, then application server will be contacted to execute a service; in this case if "--remote" is not specified, a local Unix socket is used to contact the server; otherwise "server:port" specified in "--remote" is the IP/name and port of the server to call, separated by a colon (":"). In case of a local Unix socket, for the default location of the socket path see "socket-file" clause in get-app; otherwise the socket path is given by "--socket" option.
By default, the output in any case will have the HTTP headers. If you don't want those to appear, use "--silent-header" option.
If "--content" is used, then file <input file> is either piped to the standard input of a command-line program (if "--service" is not used), or sent as a content to the application server (if "--service" is used). You can also specify content type with "--content-type". For example:
gg -r -app="/my_app" --req="/some_request?par1=val1&par2=20&par3=4" --method=PATCH --content=something.json --content-type=application/json --exec
Copied!
Examples of using "-r" option to execute command-line program or to call a service:
gg -r --req="/json" --exec
gg -r --req="/json" --app="/app_name" --service --exec
gg -r --req="/json?act=perf" --app="/app_name" --service --socket="/sock_path/sock" --exec
gg -r --req="/json/act=perf" --app="/app_name" --service --remote="192.168.0.21:2301" --exec
Copied!
- Performance
"gg -r" can be used both for testing and in production, however for maximum performance, skip "--exec" option to display direct bash code that you can copy and paste to use in production. This direct code is about 300% faster than using "gg -r"; keep this in mind if performance of using "gg -r" is important. When "--exec" is not used, the output may look like this:
export CONTENT_TYPE=
export CONTENT_LENGTH=
unset GG_SILENT_HEADER
export GG_SILENT_HEADER
export REQUEST_METHOD=GET
export SCRIPT_NAME="/app_name"
export PATH_INFO="/json/act=perf"
export QUERY_STRING=""
/usr/lib/golf/ggcli "192.168.0.21:2301"
Copied!
If you copy the above and paste into bash shell, it will execute the command line program which handles the request specified (which gg would do when "--exec" is specified, but not as fast). Note that SCRIPT_NAME will be set to whatever application path you use (i.e. the default or if set with "--path" option when making the application; or with "--app" option here), see request.
- -u
Read stdin (standard input) and substitute any environment variables in the form of ${<var name>} with their values, and output to stdout (stdout). This is useful in processing configuration files that do not have parameter values hardcoded, but rather take them from the environment.
- -m
Add Golf syntax and keyword highlighting rules for files with .golf extension to Vim editor for the currently logged on user. Note that you must have Vim installed; vi alone will not work.
- --man <topic|all>
Display list of all man pages for Golf (if '--man all' is used), or display manual page for a particular topic (for instance '--man read-file'). If man program is available on your system, you can als use 'man <topic>' directly to get help.
- -h
Display help.
- Make application (-q), use three databases (--db) named mdb (MariaDB database), pdb (PostgreSQL) and sdb (SQLite):
gg -q --db="mariadb:mdb postgres:pdb sqlite:sdb"
Copied!
- make application, use MariaDB database db (--db), specify linker and C compilation flags, specify maximum upload size of about 18M:
gg -q --db="mariadb:db" --lflag "-Wl,-z,defs" --cflag "-DXYZ123" --maxupload 18000000
Copied!
- Make application that doesn't use any databases:
gg -q
Copied!
Golf compiler and utility
gg
See all
documentation
Golf license
Golf is Free Open Source software licensed under Apache License 2.
The following discussion is not legal advice.
Golf is copyright (c) 2019-2025 Gliim LLC. Golf uses the following Free Open Source libraries; their licenses are stated below and they are copyright by their respective owners.
Dynamically linked libraries
You would install these libraries yourself (they are not distributed with Golf) as dependencies for compiling the source code.
Golf incorporates the source code of the following libraries:
Golf uses FNV-1a hash function, which is released in the public domain (see wikipedia page) and is not patented (see Landon Noll's web page).
Copyright in Golf source code
License
golf-license
See all
documentation
Hash string
Purpose: Hash a string.
hash-string <string> to <result> \
[ binary [ <binary> ] \
[ digest <digest algorithm> ]
Copied!
hash-string produces by default a SHA256 hash of <string> (if "digest" clause is not used), and stores the result into <result>. You can use a different <digest algorithm> in "digest" clause (for example "SHA3-256"). To see a list of available digests:
openssl list -digest-algorithms
Copied!
If "binary" clause is used without boolean variable <binary>, or if <binary> evaluates to true, then the <result> is a binary string that may contain null-characters. With the default SHA256, it is 32 bytes in length, while for instance with SHA3-384 it is 48 bytes in length, etc.
Without "binary" clause, or if <binary> evaluates to false, each binary byte of hashed string is converted to two hexadecimal characters ("0"-"9" and "a"-"f"), hence <result> is twice as long as with "binary" clause.
String "result" will have a hashed value of the given string, an example of which might look like "e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855":
hash-string "hello world" to hash
Copied!
Using a different digest:
hash-string "hello world" to hash digest "sha3-384"
Copied!
Producing a binary value instead of a null-terminated hexadecimal string:
hash-string "hello world" to hash digest "sha3-384" binary
Copied!
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
Hmac string
Purpose: Create HMAC.
hmac-string <string> to <result> \
key <key> \
[ binary [ <binary> ] \
[ digest <digest algorithm> ]
Copied!
hmac-string produces by default a SHA256-based HMAC (Hash Message Authentication Code) of <string> (if "digest" clause is not used) using secret <key>, and stores the result into <result>. You can use a different <digest algorithm> in "digest" clause (for example "SHA3-256"). To see a list of available digests:
openssl list -digest-algorithms
Copied!
If "binary" clause is used without boolean variable <binary>, or if <binary> evaluates to true, then the <result> is a binary string that may contain null-characters. With the default SHA256, it is 32 bytes in length, while for instance with SHA3-384 it is 48 bytes in length, etc.
Without "binary" clause, or if <binary> evaluates to false, each binary byte of HMAC is converted to two hexadecimal characters ("0"-"9" and "a"-"f"), hence <result> is twice as long as with "binary" clause.
String "result" will have a HMAC value of a given string, an example of which might look like "2d948cc89148ef96fa4f1876e74af4ce984423d355beb12f7fdba5383143bee0"
hmac-string "some data" key "mykey" to result
Copied!
Using a different digest:
hmac-string "some data" key "mykey" to result digest "sha3-384"
Copied!
Producing a binary value instead of a null-terminated hexadecimal string, and then making a Base64 string out of it:
hmac-string "some data" key "mykey" digest "SHA256" to result binary
encode-base64 result to bresult
Copied!
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
If defined
Purpose: Conditional compilation.
if-defined <symbol>
<any code>
end-defined
if-defined <symbol> [ equal | not-equal | lesser-than | lesser-equal | greater-than | greater-equal ] <number>
<any code>
end-defined
if-not-defined <symbol>
<any code>
end-defined
Copied!
Without a comparison clause, if-defined will cause <any code> to be compiled if <symbol> is defined (see "--cflag" option in gg); if <symbol> is not defined, then <any code> is not compiled.
With a comparison clause, if-defined will cause <any code> to be compiled if <symbol> is equal/not equal/lesser than/lesser or equal/greater than/greater or equal than <number> constant, depending on the clause used (see "--cflag" option in gg). If <symbol> is not defined, then its value is assumed to be 0, and <any code> may still be compiled if the comparison clause and the <number> are such that the condition is true for <symbol> being 0.
if-not-defined will cause <any code> to be compiled if <symbol> is not defined (see "--cflag" option in gg); if <symbol> is defined, then <any code> is not compiled.
Note that <symbol> can start with an underscore, unlike Golf variable names; this is because defined symbols aren't variables and generally are set by the outside environment or during compilation (see "--cflag" option in gg).
The following code will have a different output depending on how is the application compiled:
if-defined DEF1
@Defined
end-defined
if-not-defined DEF1
@Not defined
end-defined
if-defined DEF2 equal 10
@DEF2 is 10
end-defined
if-defined DEF2 equal 0
@DEF2 is 0
end-defined
Copied!
If compiled with:
gg -q
Copied!
then the output is:
Not defined
DEF2 is 0
Copied!
If compiled with:
gg -q --cflag="-DDEF1 -DDEF2=10"
Copied!
then the output is:
Defined
DEF2 is 10
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
If true
Purpose: Comparison statement.
if-true <comparison>
<any code>
[
else-if <comparison>
<any code>
] ...
[
else-if
<any code>
]
end-if
Copied!
if-true statement will evaluate a <comparison> and if true, it will execute <any code> that immediately follows; if false, it will evaluate the optional following <comparison> in else-if statement, and if true it will execute <any code> that immediately follows it; and so on; if none of the comparisons are true, then an optional <any code> following else-if statement will execute; regardless of which <any code> executes (or if any does), the execution will continue after end-if.
There can be only one "else-if" statement without a condition, and it must be the last one.
<comparison> is
- For strings:
<string> \
( equal | not-equal | \
lesser-than | lesser-equal | \
greater-than | greater-equal | \
contain | not-contain ) \
<check string> \
[ case-insensitive ] [ length <length> ]
Copied!
If "equal", "not-equal", "lesser-than", "lesser-equal", "greater-than" or "greater-equal" clause is used, a comparison succeeds if <string> is equal, not equal, lesser, lesser or equal, greater or greater-or-equal than <check string>, respectively.
If "contain" or "not-contain" clause is used, a comparison succeeds if <string> is contained or not contained in <check string>, respectively.
If "case-insensitive" clause is used, a comparison is performed without case sensitivity; this option is meant for null-terminated strings, while for non-null terminated strings it produces an undefined result.
If "length" clause is used, only the first <length> bytes of the strings are compared; this clause is not available for "contain" and "not-contain".
- For numbers:
<number> \
( equal | not-equal | \
lesser-than | lesser-equal | \
greater-than | greater-equal | \
every | not-every ) \
<check number> ...
Copied!
If "equal", "not-equal", "lesser-than", "lesser-equal", "greater-than" or "greater-equal" clause is used, a comparison succeeds if <number> is equal, not equal, lesser, lesser or equal, greater or greater-or-equal than <check number>, respectively.
If "every" is used, then the comparison succeeds if the modulo of <number> and <check number> is 0 - this is useful in executing some code every N times but not the ones in between; with "not-every" the comparison success is this modulo is not 0 which is useful to execute code all the times except every Nth.
- For booleans:
<boolean> ( equal | not-equal ) <check boolean> ...
Copied!
If "equal" or "not-equal" clause is used, a comparison succeeds if <boolean> is equal or not equal than <check boolean>, respectively.
For convenience, multiple <comparisons> can be connected by either "and" or "or" clause, but not both in the same <condition> (in order to keep comparisons readable; see boolean-expressions for constructing more involved boolean expressions). "and" clause uses logical AND to connect <comparisons> and it succeeds if all <comparison>s succeed. "or" clause uses logical OR to connect <comparisons> and it succeeds if at least one <comparison>s succeeds (if such a <comparison> is found, the following ones are not checked).
if-true can be nested, which can be up to 30 levels deep.
%% /if-test public
get-param inp
if-true inp equal "1"
@Found "1" in input
else-if inp equal "2" or inp equal "3"
@Found "2" or "3" in input
get-param inp_num
string-number inp_num to num
if-true num equal 4
@Found 4 in more input
else-if num equal 5 and inp equal "4"
@Found 5 in more input and "4" in input
else-if
@Something else
end-if
else-if
@Found something else
end-if
%%
Copied!
<string>, <number> and <boolean> can be expressions, for instance:
set-string str1="one"
set-string str2="two"
if-true str1+" "+str2 not-equal "one two"
@It can't be true!
end-if
...
set-bool b1 = str1 not-equal "one"
set-bool b2 = str2 equal "two"
if-true b1 && b2 equal false
@It is true!
end-if
...
set-number n1 = 20
if-true n1+10 equal 30 and !b1 equal true and str1 equal "one"
@It is true!
end-if
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Inline code
Purpose: Inline Golf code in an output statement.
<<golf code>>
Copied!
You can write Golf statements within an output-statement by using them between << and >> delimiters.
The following statements can be inlined: print-out,print-format, current-row, number-string, string-length, call-handler.
print-out statement displays a string, and in the following code it's used to display a result within an output-statement (i.e. within "@" statement):
run-query ="select firstName, lastName from people" output firstName, lastName
@<tr>
@ <td>
@ First name is <<print-out firstName>>
@ </td>
@ <td>
@ Last name is <<print-out lastName>>
@ </td>
@</tr>
end-query
Copied!
In the code below, "some_req" is a request handler that outputs some text, and it's used inline to output "Hello world":
@Hello <<call-handler "/some-req">>
Copied!
call-handler "some-req" would simply output "world":
%% /some-req public
@world
%%
Copied!
A write-string is typically used with output statements; in this case we print the value of another string, resulting in "There is 42 minutes left!":
set-string mins="42"
(( my_string
@There is <<print-out mins>> minutes left!
))
Copied!
Language
inline-code
statements
syntax-highlighting
unused-var
variable-scope
See all
documentation
Install golf
There are three ways to install Golf, pick one that works for you:
- From a zipped file (.tar.gz):
- If you use git, from its official GitHub repo (depth is 1 for performance and to save space):
- If there's a Golf package installed on your system, from a package. First, install-package, then:
cp /usr/share/golf/golf.tar.gz .
tar xvfz golf.tar.gz
cd golf
./gginst.sh
. $HOME/.bashrc
Copied!
Note that $HOME/.bashrc is run at the end so you can use Golf in the current session without re-logging.
- Permissions and install script
Golf is installed in a home directory (either in a separate user account or in your own home directory). Minimum permissions (required and set by the installation) for home directory are 711 (allowing access to specific sockets but no read, write or directory listing permissions).
- sudo privilege
Golf itself does not require sudo as it installs in a local ".golf" folder. You may however need sudo privilege to install standard Open Source toolkit libraries (such as MariaDB, SQLite, PostgreSQL, XML, Regex, Curl, OpenSSL etc), base libraries (such as gcc, make etc.; and only if not installed already, which they usually are), or SELinux support (if you use it). They are system-wide by nature and require sudo.
- Installing toolkit libraries
The default installation (above) will ask you if you'd like to install the above toolkit packages, You can install them if and when you need them, or you can install them now; you will need sudo privilege to do that. If you'd like to install all base and toolkit packages automatically now, then use the following (instead of just ./gginst.sh above):
./gginst.sh all
Copied!
- SELinux
If you have SELinux enabled then you'll need to install SELinux support for Golf. This requires sudo privilege because it involves setting Operating System permissions for Golf. This will be done automatically during the installation.
If you don't want or need SELinux support, you can set permissive mode before installing Golf with:
sudo setenforce 0
Copied!
in which case you won't need to install SELinux support.
- Upgrading/downgrading Golf
To either upgrade or downgrade Golf, first uninstall and then install (see above). Look for release notes for any given version at Golf blog for more information about any changes that may affect your Golf application(s).
- Uninstall Golf
Here's how to uninstall.
Go to 123-hello-world for your Hello World.
Install golf
install-golf
install-package
uninstall
See all
documentation
Install package
You can install Golf source code from a Golf package, available for popular Linux distributions. These packages contain source code only. Once a package is installed, you still need to install Golf from the source code provided by the package.
Why use a package? For one, if you have multiple developers working on the same machine, they can use the same Golf source code provided by the Golf package, and the version control is easier. And secondly, a Golf package will install all the Golf's base and toolkit dependencies (such as database drivers, XML library, make sure gcc/make are installed etc).
Since the packages do not contain any binaries, they can be installed on a wide variety of versions (for any given distro), and even on distros not mentioned here (such as on derived ones). Note that only the latest versions are actually tested with each release, so whether a package would work with a particular distro and version you're using is a matter of trying it out. Here are the packages available (all available can be found here). Download the package and then install it:
- Debian and similar
- Ubuntu and similar
- Fedora and similar
- Redhat and similar
- OpenSUSE and similar
- Arch Linux and similar
If you are a packaging developer, the following can be used to build a Golf package. All of these use golf_3.3.0.orig.tar.gz source archive; the naming convention is obviously for Debian, but all other packages have been made to conform for simplicity.
- apt packaging
"debian" folder containing package build files (control, copyright, rules etc.) is here.
- rpm packaging
"golf.spec" file used to build an rpm package is here.
- pacman packaging
"PKGBUILD" file used to build a pacman package is here.
Install golf
install-golf
install-package
uninstall
See all
documentation
Json doc
Purpose: Parse JSON text.
json-doc <text> to <json> \
[ status <status> ] [ length <length> ] [ noencode ] [ no-enum ] \
[ error-text <error text> ] \
[ error-position <error position> ] \
[ error-line <line> ] \
[ error-char <char> ]
json-doc delete <json>
Copied!
json-doc will parse JSON <text> into <json> variable, which can be used with read-json to get the data.
The length of <text> may be specified with "length" clause in <length> variable, or if not, it will be the string length of <text>.
The "status" clause specifies the return <status> number, which is GG_OKAY if successful or GG_ERR_JSON if there is an error. The number <error position> in "error-position" clause is the byte position in <text> where error was found (starting with "0"), in which case <error text> in "error-text" clause is the error message. You can also obtain the error's line number (with number <line> in clause "error-line") and the character position within that line (with number <char> in clause "error-char").
"noencode" clause will not encode strings, i.e. convert from JSON Unicode strings to UTF, nor will it perform any validity checks on strings. This may be useful as a performance boost or to pass along strings unencoded, however in most cases it is not needed.
"no-enum" clause will not include indexing of arrays in normalized names (with "[..]"), see read-json. This is useful if you want to check the path of each data element, and not worry about counting them; this happens often when using JSON in a structured way to transfer arrays when data elements repeat in a predictable fashion. Parsing of JSON is also faster with "no-enum".
The maximum depth of nested structures in JSON document (i.e. objects and arrays) is 32, and the maximum length of normalized leaf node name is 1024 (see read-json for more on normalized names). There is no limit on document size.
To delete a JSON variable, use "delete" clause with the <json>. This will delete all memory associated with it, and the variable <json> itself.
Parse the following JSON document and display all keys and values from it. You can use them as they come along, or store them into new-hash or new-tree for instance for searching of large documents. This also demonstrates usage of UTF8 characters:
set-string jd unquoted = {"menu":\
{"id": "file",\
"value": 23091,\
"active": false,\
"popup":\
{"menuitem":\
[{"value": "New", "onclick": "CreateNewDoc with\uD834\uDD1Emusic"},\
{"value": "Open", "onclick": "OpenDoc() with \uD834\uDD1E\uD834\uDD1E"},\
{"value": "Close", "onclick": "\uD834\uDD1ECloseDoc()"}\
]\
}\
}\
}
json-doc jd status st error-text et error-position ep to nj
if-true st not-equal GG_OKAY
@Error [<<print-out et>>] at [<<print-out ep>>]
exit-handler -1
end-if
start-loop
read-json nj key k value v type t next
if-true t equal GG_JSON_TYPE_NONE
break-loop
end-if
@Key [<<print-out k>>]
@Value [<<print-out v>>]
@Type [<<print-out t>>]
@--------
end-loop
@
json-doc delete nj
Copied!
The output would be:
Key ["menu"."id"]
Value [file]
Type [0]
--------
Key ["menu"."value"]
Value [23091]
Type [1]
--------
Key ["menu"."active"]
Value [false]
Type [3]
--------
Key ["menu"."popup"."menuitem"[0]."value"]
Value [New]
Type [0]
--------
Key ["menu"."popup"."menuitem"[0]."onclick"]
Value [CreateNewDoc with𝄞music]
Type [0]
--------
Key ["menu"."popup"."menuitem"[1]."value"]
Value [Open]
Type [0]
--------
Key ["menu"."popup"."menuitem"[1]."onclick"]
Value [OpenDoc() with 𝄞𝄞]
Type [0]
--------
Key ["menu"."popup"."menuitem"[2]."value"]
Value [Close]
Type [0]
--------
Key ["menu"."popup"."menuitem"[2]."onclick"]
Value [𝄞CloseDoc()]
Type [0]
--------
Copied!
Note that if "no-enum" were used in json-doc, then all keys with arrays would not have "[..]", for instance the very last key above would be "menu"."popup"."menuitem"."onclick", i.e. there would be no indexing of arrays.
JSON parsing
json-doc
read-json
See all
documentation
Lock file
Purpose: Locks file exclusively.
lock-file <file path> id <lock id> [ status <status> ]
Copied!
lock-file attempts to create file with the full path of <file path> (deleting it if existed), and exclusively lock it. If successful, no other process can do the same unless current process ends or calls unlock-file. This statement is non-blocking, thus you can check in a sleepy loop for success (see pause-program).
<file path> should be either an existing or non-existing file with a valid file path. If existing, it will be deleted.
<lock id> (in "id" clause) is a file descriptor associated with locked file.
<status> (in "status" clause) represents the status of file locking: GG_OKAY if successfully locked, GG_ERR_FAILED if cannot lock (likely because another process holds a lock), GG_ERR_INVALID if the path of the file is invalid (i.e. if it is empty), GG_ERR_CREATE if lock file cannot be created.
Generally, this statement is used for process control. A process would use lock-file to start working on a job that only one process can do at a time; once done, by using unlock-file statement, another process will be able to issue a successful lock-file call. Typically, lock-file is issued in a sleepy loop (see pause-program), waiting for a resource to be released.
Note that file lock is not carried across children processes (i.e. if your process creates children, such as with exec-program, then such children must obtain their own lock). In addition, if a process serving a request terminates before the request could issue unlock-file, the lock will be automatically released.
You can use any file name (likely choose a name that signifies the purpose of a lock, as long as you have permissions to create it), and create any number of them. This way you can create as many "binary semaphore"-like objects as you like.
%% /locktest public
get-app directory to dir
write-string fname
@<<print-out dir>>/.lock
end-write-string
set-number lockid
start-loop
lock-file fname id lockid status lockst
if-true lockst equal GG_OKAY
@WORKING
pause-program 20000
@DONE
break-loop
else-if lockst equal GG_ERR_FAILED
pause-program 1000
@WAITING
continue-loop
else-if lockst equal GG_ERR_OPEN or lockst equal GG_ERR_INVALID
@BAD LOCK
exit-handler
end-if
end-loop
unlock-file id lockid
%%
Copied!
%%
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Lower string
Purpose: Lower-case a string.
lower-string <string>
Copied!
lower-string converts all <string>'s characters to lower case.
The resulting "str" is "good":
set-string str="GOOD"
lower-string str
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Mariadb database
MariaDB configuration file is written as a MariaDB client options file.
You can see the parameters available at https://mariadb.com/kb/en/configuring-mariadb-connectorc-with-option-files/#options.
Most of the time, though, you would likely use only a few of those options, as in (for local connection):
[client]
user=myuser
password=mypwd
database=mydb
socket=/run/mysqld/mysqld.sock
Copied!
The above file has fields "user" (MariaDB user), "password" (the password for MariaDB user), "database" (the MariaDB database name) and MariaDB communication "socket" location (assuming your database is local to your computer - if the database is across network you would not use sockets!).
If you use passwordless MariaDB login (such as when the MariaDB user name is the same as your Operating System user name and where unix socket plugin is used for authentication), the password would be empty.
To get the location of the socket, you might use:
sudo mysql -u root -e "show variables like 'socket'"
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Match regex
Purpose: Find, or find and replace patterns in strings using regex (regular expressions).
match-regex <pattern> in <target> \
[ \
( replace-with <replace pattern> \
result <result> \
[ status <status> ] ) \
| \
( status <status> \
[ case-insensitive [ <case-insensitive> ] ] \
[ single-match [ <single-match> ] ] \
[ utf [ <utf> ] ] ) \
] \
[ cache ] \
[ clear-cache <clear cache> )
Copied!
match-regex searches <target> string for regex <pattern>. If "replace-with" is specified, then instance(s) of <pattern> in <target> are replaced with <replace pattern> string, and the result is stored in <result> string.
The number of found or found/replaced patterns can be obtained in number <status> variable (in "status" clause).
If "replace-with" is not specified, then the number of matched <pattern>s within <target> is given in <status> number, which in this case must be specified.
If "case-insensitive" is used without boolean variable <case-insensitive>, or if <case-insensitive> evaluates to true, then searching for pattern is case insensitive. By default, it is case sensitive.
If "single-match" is specified without boolean variable <single-match>, or if <single-match> evaluates to true, then only the very first occurrence of <pattern> in <target> is processed. Otherwise, all occurrences are processed.
If "utf" is used, then the pattern itself and all data strings used for matching are treated as UTF-8 strings.
<result> and <status> variables can be created within the statement.
If the pattern is bad (i.e. <pattern> is not a correct regular expression), Golf will error out with a message.
By default, PCRE2 regex syntax (Perl-compatible Regular Expressions v2) is used. To use extended regex syntax (Posix ERE), specify "--posix-regex" when building your application with gg. See more below in Limitations about differences.
If "cache" clause is used, then regex compilation of <pattern> will be done only once and saved for future use. There is a significant performance benefit when match-regex executes repeatedly with "cache" (such as in case of web applications or in any kind of loop). If <pattern> changes and you need to recompile it once in a while, use "clear-cache" clause. <clear cache> is a "bool" variable; the regex cache is cleared if it is true, and stays if it is false. For example:
set-bool cl_c
if-true q equal 0
set-bool cl_c = true
end-if
match-regex ps in look_in replace-with "Yes it is \\1!" result res cache clear-cache cl_c
Copied!
In this case, when "q" is 0, cache will be cleared, and the pattern in variable "ps" will be recompiled. In all other cases, the last computed regex stays the same.
While every pattern is different, when using cache, even a relatively small pattern was seen in tests to speed up the match-regex by about 500%, or 5x faster. Use cache whenever possible as it brings parsing performance close to its theoretical limits.
Subexpressions and back-referencing
match-regex "(good).*(day)" \
in "Hello, good day!" \
replace-with "\\2 \\1" \
result res
Copied!
will produce string "Hello, day good!" as a result in "res" variable. Each subexpression is within () parenthesis, so for instance "day" in the above pattern is the 2nd subexpression, and is back-referenced as \\2 in replacement.
There can be a maximum of 23 subexpressions.
Note that backreferences to non-existing subexpressions are ignored - for example \\4 when there are only 3 subexpressions. Golf is "smart" about using two digits and differentiating between \\1 and \\10 for instance - it takes into account the actual number of subexpressions and their validity, and selects a proper subexpression even when two digits are used in a backreference.
Lookaheads and lookbehinds
match-regex "\\w*(?<=foo)bar" in "foobar" status st single-match
Copied!
and the following matches "foo" if followed by "bar":
match-regex "\\w*foo(?=bar)" in "foofoo" status st single-match
Copied!
If you are using older versions of PCRE2 (10.36 or earlier) such as by default in Debian 10 or Ubuntu 18, then instead of PCRE2, an Extended Regex Expressions (ERE) from the built-in Linux regex library is used, due to older PCRE2 versions having name conflicts with other libraries. In this case, "utf" clause will have no effect, and lookaheads/lookbehinds functionality will not work; possibly a few others as well, however for the most part the two are compatible. If your system uses an older PCRE2 library, you can upgrade to 10.37 or later to use PCRE2.
In any case, if you need to use Posix ERE instead of PCRE2 (for compatibility, to reduce memory footprint or some other reason), you can use "--posix-regex" option of gg; the same limitations as above apply. Note that PCRE2 (the default) is generally faster than ERE.
Use match-regex statement to find out if a string matches a pattern, for example:
match-regex "SOME (.*) IS (.*)" in "WOW SOME THING IS GOOD HERE" status st
Copied!
In this case, the first parameter ("SOME (.*) IS (.*)") is a pattern and you're matching it with string ("WOW SOME THING IS GOOD HERE"). Since there is a match, status variable (defined on the fly as integer) "st" will be "1" (meaning one match was found) - in general it will contain the number of patterns matched.
Search for patterns and replace them by using replace-with clause, for example:
match-regex "SOME (.*) IS ([^ ]+)" in "WOW SOME THING IS GOOD HERE FOR SURE" replace-with "THINGS ARE \\2 YES!" result res status st
Copied!
In this case, the result from replacement will be in a new string variable "res" specified with the result clause, and it will be
WOW THINGS ARE GOOD YES! HERE FOR SURE
Copied!
The above demonstrates a typical use of subexpressions in regex (meaning "()" statements) and their referencing with "\\1", "\\2" etc. in the order in which they appear. Consult regex documentation for more information. Status variable specified with status clause ("st" in this example) will contain the number of patterns matched and replaced.
Matching is by default case sensitive. Use "case-insensitive" clause to change it to case insensitive, for instance:
match-regex "SOME (.*) IS (.*)" in "WOW some THING IS GOOD HERE" status st case-insensitive
Copied!
In the above case, the pattern would not be found without "case-insensitive" clause because "SOME" and "some" would not match. This clause works the same in matching-only as well as replacing strings.
If you want to match only the first occurrence of a pattern, use "single-match" option:
match-regex "SOME ([^ ]+) IS ([^ ]+)" in "WOW SOME THING IS GOOD HERE AND SOME STUFF IS GOOD TOO" status st single-match
Copied!
In this case there would be two matches by default ("SOME THING IS GOOD" and "SOME STUFF IS GOOD") but only the first would be found. This clause works the same for replacing as well - only the first occurrence would be replaced.
Regex
match-regex
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Memory handling
Golf is a memory-safe language.
Your application cannot access memory outside of valid statement results. Trying to do so will result in your program erroring out.
Memory allocated by Golf statements is tracked and freed at the end of the request.
With Golf there is no need to free memory manually. Memory is automatically freed even if it is no longer accessible to the program, thus preventing memory leaks; this is important for stability of long-running processes.
Some statements (new-tree, new-hash, new-list, new-array and set-string) have the option of allocating memory that won't get freed at the end of the request and is available to any request served by the same process. This kind of memory is called "process-scoped". A process-scoped string can be manually freed.
Golf handles memory references and assignments automatically, preventing dangling memory.
String results of any Golf statements will always create new memory, unless stated otherwise.
Any files opened by open-file statement are automatically closed by Golf at the end of the request. This enhances stability of long-running server processes because Linux system by default offers only about 1000 open files to a process. A bug can quickly exhaust this pool and cause a malfunction or a crash - Golf prevents this by closing any such open files when the request ends.
Memory
memory-handling
See all
documentation
Mgrg
Purpose: Run and manage services.
mgrg <options> <app name>
Copied!
mgrg (pronounced "em-greg") is a service manager. A service is started as a number of concurrent processes serving application requests, typically from reverse-proxy servers such as Apache, Nginx, HAProxy or others. Use mgrg to create Golf applications, including both service and command-line.
A number of options are available to setup and manage the execution of a Golf program as an application server, which can be accessed either via TCP/IP or a Unix domain socket.
<app name> specifies the name of your application. Each application must have a unique name. <app name> may contain alphanumeric characters and an underscore, must start with a character and its maximum length is 30.
mgrg runs as a light-weight daemon (often requiring only 100-150K of resident RAM), with a separate instance for each application specified by the <app name>. When mgrg starts your service, its current directory is set to $HOME/.golf/apps/<app name>/app. The permissions context is inherited from the caller, so the effective user ID, group ID and any supplemental groups are that of the caller. You can use tools like runuser to specifically set the permissions context.
mgrg will re-start service processes that exited or died, keeping the number of processes as specified, unless -n option is used. The number of worker processes can be specified with a fixed (-w) option, or it can dynamically change based on the load (-d option), including none at all. Hence, it is possible to have no worker processes at all, and they will be started when incoming request(s) come in, and stay up as determined by the request load.
<options> are:
- -i
Initialize the directory and file structure for application <app name>. If you are building application from source code, this must be executed in the source code directory; mgrg will create file ".golfapp" which identifies the application so gg can run in the directory. The directory structure is setup in $HOME/.golf/apps/<app name> (see directories).
- -u <OS user>
The owner of your application. This is only used when initializing directory structure used by mgrg (see -i option). Do not use it otherwise. It cannot be root.
- -r <proxy group>
The group of proxy web server (such as Apache or Nginx). This is only used when initializing directory structure used by mgrg (see -i option). Do not use it otherwise. It restricts the ability to connect to your application only to the members of said group (in addition to the user who owns your server) when a Unix socket is used, otherwise anyone can connect. If you are not a member of this group, then you must invoke mgrg with sudo - this is the only time this is necessary (see below an example on how to run with sudo).
- -f
Run in the foreground. The process does not return to the command line prompt until it is stopped. Useful for debugging and where foreground processing is required.
- -p <port number>
TCP/IP port number your service program will listen on (and accept connections), if you are using TCP/IP. You typically need to specify ProxyPass, "location" or similar FastCGI directives in your proxy web server so it can connect to your application. If you are using Client-API or call-remote, you would use "<host name>:<port number>", for instance "127.0.0.1:2301" if the server is local and <port number> is 2301. You can either use TCP/IP or Unix domain sockets (-x option). Typically, you would use Unix domain sockets if proxy web server runs on the same computer as your application server. If you specify neither -x nor -p, -x (unix domain socket) is the default.
- -x
Use Unix domain socket to connect from proxy web server to your application server. This socket is automatically created by mgrg and its full path name is "$HOME/.golf/apps/<app name>/sock/sock" (you can connect to it via Client-API, call-remote etc.). When using a proxy web server (like Apache or Nginx), you typically need to specify ProxyPass, "location" or similar FastCGI directives so it can connect to your application. If you specify neither -x nor -p (TCP/IP socket), then -x (unix domain socket) is the default.
- -l <backlog size>
The size of socket listening backlog for incoming connections. It must be a number between 10 and SOMAXCONN-1, inclusive. The default is 400. Increase it if your system is very busy to improve performance.
- -d
Dynamically change the number of service processes ("worker" processes) to match the request load (adaptive mode). Use with "max-worker" and "min-worker" options. You cannot use -w with this option. The number of processes needed is determined based on any pending connections that are not answered by any running processes. If there are more incoming connections than processes, the number of processes will grow. If no such connections are detected (i.e. existing processes are capable of handling any incoming requests), the number of processes does not grow and will decrease to the point of minimum necessary number of workers. In that case, given release time (-t option), the number of processes will slowly decline until the incoming requests warrant otherwise. The number of running processes thus will fluctuate based on the actual load, these options, as well as --min-worker and --max-worker options. If neither -d nor -w is specified, -d is the default.
- --min-worker=<min workers>
Minimum number of service processes that run in adaptive mode (-d option). The default is 5. You can set this to 0 if needed to save memory. This option can be used only with -d option.
- --max-worker=<max workers>
Maximum number of service processes that run in adaptive mode (-d option). The default is 20. This option can be used only with -d option.
- -t <release time>
Timeout before the number of service processes is reduced to meet the reduced load. The default is 30 seconds, and it can be a value between 5 seconds and 86400 seconds (i.e. a day).
- -w <worker processes>
Number of parallel service processes ("worker" processes) that will be started. These processes do not exit; they serve incoming requests in parallel, one request per process. The number of processes should be guided by the concurrent user demand of your application. If neither -d nor -w is specified, -d is the default.
- -m <command>
Send a command to mgrg daemon serving an application. <command> can be "start" (to start service processes), "stop" (to stop them), "restart" (to restart them), "quit" (to stop mgrg daemon altogether) or "status" (to display status of mgrg).
- -n
Do not restart service processes if they exit or die. However, in adaptive mode (-d option), this option has no effect.
- -g
Do not restart service processes when their executable changes. By default, they will be automatically restarted, which is useful when in development, or upgrading the server executable.
- -a <args>
Specify any command-line arguments for your application (see "arg-count" and "arg-value" clauses in get-req). The <args> should be double-quoted as a whole, while use of single quotes to quote arguments that contain whitespaces is permitted.
- -z
Suppress HTTP headers in all service handlers in the application. This is equivalent to having silent-header implied at the beginning of each service handler. Use this option only if service is not used as a web service (i.e. the output will not have HTTP headers), or for testing or elsewhere where such headers may not be needed. Otherwise, you can use "--silent-header" option in gg or "GG_SILENT_HEADER" environment variable in Client-API to control from command-line or a client if headers are output or not.
- -s <sleep millisecs>
The basis time period (in milliseconds) that mgrg will sleep before checking for commands (specified by -m option), or check for dead service processes that need restarting. It can be between 100 and 5000 milliseconds. Smaller value will mean higher responsiveness but also higher CPU usage. The default value usually suffices, and should not be changed without due consideration.
- -e
Display verbose messages.
- -c <program>
Full absolute path to your service program. If omitted, the executable $HOME/.golf/bld/<app name>/<app name>.srvc is assumed, which is the standard Golf service executable. If present, but without any slashes in it to indicate path (including current directory as ./), then this executable is assumed to be $HOME/.golf/bld/<app name>/<program>.
- -v
Display mgrg version (which matches Golf version) as well as copyright and license.
- -h,--help
Display help.
mgrg writes log file at $HOME/.golf/apps/<app name>/mgrglog/log file. This file is overwritten when mgrg starts, so it contains the log of the current daemon instance only.
When starting, mgrg exits with 0 if successful and 1 if it is already running. If service executable cannot run, the exit code is -1. When creating application, mgrg exits with 0 if successful, and -1 if not.
When mgrg is told to stop the application (with "-m stop" arguments), it will send SIGTERM signal to all its children. All Golf processes will complete the current request before exiting, assuming they are currently processing a request; otherwise they will exit immediately.
If mgrg is terminated without "-m stop", (for example with SIGKILL signal), then all its chidlren will immediately terminate with SIGKILL as well, regardless of whether they are currently processing any requests or not.
- To begin using mgrg for a specific application, you must initialize it first. For example, if your application name is "myapp" and the user who will run application is the currently logged-on user:
sudo $(which mgrg) -i -u $(whoami) myapp
Copied!
Note that you need to use $(which mgrg) when using sudo, since root's user directory has no Golf installation and mgrg executable won't be found. Since shell $() construct is executed by bash prior to the command, this will produce the correct executable path for mgrg.
- The initialization needs to be done only once. Following the above, you can start your service application with 3 server processes:
mgrg -w 3 myapp
Copied!
- To stop your service processes:
mgrg -m stop -- myapp
Copied!
- To restart them:
mgrg -m restart -- myapp
Copied!
- To stop the server entirely (meaning to stop the resident mgrg daemon serving your particular application):
mgrg -m quit -- myapp
Copied!
- To view status of mgrg daemon for your application:
mgrg -m status -- myapp
Copied!
Running your application server on system startup
[Unit]
Description=Golf Service Program Manager for [<app name>] application.
After=network.target
[Service]
Type=forking
ExecStart=/usr/bin/mgrg <app name>
ExecStop=/usr/bin/mgrg -m quit <app name>
KillMode=process
Restart=on-failure
User=<app owner>
[Install]
WantedBy=multi-user.target
Copied!
The above should be saved in the directory given by the output of the following system command:
pkg-config systemd --variable=systemdsystemunitdir
Copied!
The file should be saved as <app name>.service (or similar). Once saved, you can use standard systemctl commands to start, stop and restart your service.
Service manager
mgrg
See all
documentation
New array
Purpose: Create array.
new-array <array> [ max-size <max-size> ] [ process-scope ] [ type string | number | bool ]
Copied!
new-array creates new <array>. An array is an indexed array, with a number as an index, and with a either a string, number or boolean as an element in the array. By default (without "type" clause), <array> is an array of strings. You can specify "string", "number" or "bool" in "type" clause, in which case <array> is an array of strings, numbers or booleans respectively.
An array is flexible, which means that it will grow as needed. By default, an array allocates room for 256 elements that can grow up to 1,000,000 elements, unless <max-size> number (in "max-size" clause) is specified in which case it can grow up to <max-size> elements. <max-size> must be at least 256.
Note that max-size specifies only the upper limit of allocation. The actual amount of memory allocated can vary.
You do not need to pre-size the array; rather when you write an element, it will resize automatically. For instance, you can set an array element arr[0] and then arr[1000] (with nothing in-between), the array will be automatically extended to accommodate. Note that it will not automatically contract when tailing elements are deleted. Use purge-array to delete all elements in the array and shrink its memory footprint when your processing is done.
Note that an array is accessible to the current request only, unless "process-scope" clause is used, in which case all requests served by a process can use it (see do-once for a typical way to do this).
If "process-scope" is used, then <array> will keep its data across all requests in a given process. See write-array for an example of a process-scoped array.
Create a new array:
new-array arr
Copied!
Array
new-array
purge-array
read-array
write-array
See all
documentation
New dir
Purpose: Create new directory.
new-dir <directory> [ mode <mode> ] [ status <status> ]
Copied!
new-dir creates new <directory>, which is a string that is an absolute or relative path. You can specify permission <mode> (in "mode" clause) as a number, based on standard Linux permissions (see permissions).
If "status" clauses is used, <status> is a number with value of GG_OKAY if successful, GG_ERR_EXIST if directory exists, or GG_ERR_FAILED for other errors (in which case you can use "errno" clause in get-req to find the specific reason why).
new-dir "new_dir"
Copied!
Directories
change-dir
change-mode
delete-dir
directories
new-dir
See all
documentation
New fifo
Purpose: Create FIFO list.
new-fifo <list>
Copied!
new-fifo initializes new FIFO <list> (First In First Out).
<list> contains data stored on a first-in, first out basis. Note that a list is accessible to the current process only.
Information is retrieved (possibly many times, see rewind-fifo) in the same order in which it was stored.
The internal positions for write-fifo and read-fifo actions are separate so you can keep writing data to the list, and read it independently of writes in any number of retrieval passes by using rewind-fifo.
new-fifo nf
Copied!
FIFO
delete-fifo
new-fifo
purge-fifo
read-fifo
rewind-fifo
write-fifo
See all
documentation
New hash
Purpose: Create hash.
new-hash <hash> \
[ process-scope ] \
[ hash-size <hash size> ]
Copied!
new-hash creates new <hash>. A hash is a collection of key/value pairs, called "elements". A value of an element is obtained based on its key value.
Note that a hash is accessible to the current request only, unless "process-scope" clause is used, in which case all requests served by a process can use it (see do-once for a typical way to create a hash with a process scope).
If "process-scope" is used, then <hash> will keep its data across all requests in a given process. See write-hash for an example of a process-scoped hash.
A hash can be of any size, as long as there is enough memory for it. The "hash-size" refers to the size of a hash table used to provide high-performance access to its elements based on a key.
<hash size> is the number of "buckets" used by the hash (it is 10 by default). All hash elements with the same hash code are stored in a linked list within the same bucket. Greater <hash size> generally means less elements per bucket and better performance. However, memory usage grows with a bigger hash table, so <hash size> should be balanced based on the program needs.
Golf uses high-performing FNV1_a hash algorithm. Each element in a bucket list is lightweight, containing pointers to a key, value and next element in the linked list.
<hash size> must be at least 256; if less, it will be set to 256.
Create a new hash with 5000 buckets:
new-hash h hash-size 5000
Copied!
See read-hash for more examples.
Hash
get-hash
new-hash
purge-hash
read-hash
resize-hash
write-hash
See all
documentation
New lifo
Purpose: Create LIFO list.
new-lifo <list>
Copied!
new-lifo initializes new LIFO <list> (Last In First Out).
<list> contains data stored on a last-in, first-out basis. Note that a list is accessible to the current process only.
Information is retrieved (possibly many times, see rewind-lifo) in the opposite order in which it was stored.
new-lifo mylifo
Copied!
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
New list
Purpose: Create linked list.
new-list <list> [ process-scope ]
Copied!
new-list initializes new linked <list>, where each element is connected to the previous and next ones.
In a linked <list> data that can be added anywhere in the list, and also accessed anywhere as well. Access to a list is sequential, meaning you can position to the first, last, next or previous element. Note that a list is accessible to the current process only.
Generally information is stored in a linked list, and retrieved (possibly many times) in any order later.
A list has a current position where an element can be read, updated, inserted or deleted (via read-list, write-list and delete-list), and this position can be explicitly changed with position-list.
A linked list is accessible to the current process only, unless "process-scope" clause is used, in which case all requests served by the process can use it (see do-once for a typical way to create an object with a process scope). If "process-scope" is used, then elements of the list will keep their value between requests in the same process.
See write-list for an example of a process-scoped list.
new-list mylist
Copied!
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
New message
Purpose: Create new message.
new-message <message> [ from <string> ]
Copied!
new-message will create a new <message> object.
If <string> is specified (in "from" clause), then it is used to create a <message> from it. The <string> must be in SEMI format, which may be in request's input, from get-message, from reading a file etc; in this case <message> can only be read from with read-message.
If new-message is used without "from" clause, data can be added to <message> with write-message.
begin-handler /msg public
new-message msg
write-message msg key "weather" value "nice"
write-message msg key "distance" value "near"
start-loop
read-message msg key k value v status s
if-true s not-equal GG_OKAY
break-loop
end-if
@Key is <<print-out k>> and value is <<print-out v>>
end-loop
end-handler
Copied!
Messages
get-message
new-message
read-message
SEMI
write-message
See all
documentation
New remote
Purpose: Create resources for a service call.
new-remote <service> \
( local <app name> ) | ( location <location> ) \
url-path <service URL> |
( \
app-path <app path> \
request-path <request path> \
[ url-params <url params> ] \
) \
[ request-body content <content> \
[ content-length <content length> ] \
[ content-type <content type> ] ] \
[ method <request method> ] \
[ environment <name>=<value> [ , ... ] ] \
[ timeout <timeout> ]
Copied!
new-remote will create resources needed for a service call (see call-remote); these resources are contained in variable <service>.
If "local" clause is used, then service is a Golf application running on the same computer, and the name of this application is string <app name>.
If "local" is not used, then you must use "location" clause. <location> (in "location" clause) is a string representing either a Unix socket or a TCP socket of a remote service, and is:
- for a Unix socket, a fully qualified name to a Unix socket file used to communicate with the service (for a Golf server, it's "$HOME/.golf/apps/<app name>/sock/sock", where <app name> is the application name), or
- for a TCP socket, a host name and a port number in the form of "<host name>:<port number>", specifying where the service is listening on (for instance "127.0.0.1:2301" if the service is local and runs on TCP port 2301).
url-path or its components
If "url-path" is not used, then you must use "app-path" and "request-path" clauses with optional "url-params" clause. <app path> string (in "app-path" clause) is the application path used to access a URL resource in service <location>, <request path> string (in "request-path" clause) is the request path used to access a URL resource in service <location>, while <url params> string (in "url-params" clause) is the URL parameters, see request.
<request method> string (in "method" clause) is a request method, such as "GET", "POST", "DELETE", "PUT" etc. The default is "GET".
Request body (i.e. body content) is specified via "request-body" clause. Within it, <content> (in "content" subclause) is the actual body content string. <content length> (in "content-length" subclause) specifies the number of bytes in <content>; by default it will be the string length of <content> (see string-length). Mandatory <content type> (in "content-type" subclause) is the body content type (for instance "application/json" or "image/jpg").
<url params> string (in "url-params" clause) is the URL parameters, see request.
<environment> (in "environment" clause) is the environment passed to a service call, in the form of "name"="value" string list where such environment elements are separated by a comma. This way you can send any environment variables to the request executed remotely. For a Golf server, you can access those variables in a remote request by using "environment" clause of get-sys statement. There is no limit on the number of environment variables you can use this way, other than the underlying communication library.
<timeout> (in "timeout" clause) is the number of seconds after which a service call will timeout; meaning the duration of a service call should not exceed this period of time. For no timeout, specify 0. Note that time needed for a DNS resolution of <location> is not counted in <timeout>. Maximum value is 86400 seconds. Even though it's optional, it is recommended to specify <timeout> in order to avoid a Golf process waiting for a very long time. Note that even if your service call times out, the actual request executing on the server may continue until it's done.
In this example, 3 service calls are created ("srv1", "srv2" and "srv3"), and they will each make a service request.
Each service request will add a key ("key1" with data "data_1", "key2" with data "data_2" and "key3" with data "data_3").
All three service calls connect via Unix socket.
A full URL path of a service request (for "srv1" for example), would be "/app/manage-keys/op=add/key=key_1/data=data_1" (note that "app" is the application name and "manage-keys" is the request handler that provides the service).
Copy this to "manage_keys.golf" source file:
%% /manage-keys public
do-once
new-hash h hash-size 1024 process-scope
end-do-once
get-param op
get-param key
get-param data
if-true op equal "add"
write-hash h key (key) value data status st
@Added [<<print-out key>>]
else-if op equal "delete"
read-hash h key (key) value val \
delete \
status st
if-true st equal GG_ERR_EXIST
@Not found [<<print-out key>>]
else-if
@Deleted [<<print-out val>>]
delete-string val
end-if
else-if op equal "query"
read-hash h key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found, queried [<<print-out key>>]
else-if
@Value [<<print-out val>>]
end-if
end-if
%%
Copied!
Then call-remote will make three service calls to the above request handler in parallel (i.e. as threads executing at the same time). You can examine if everything went okay, how many threads have started, and how many finished with a reply from the service (this means any kind of reply, even if an error). Finally, the output from each call is displayed (that's "data" clause in read-remote statement at the end).
Create file "srv.golf" and copy to it this code:
begin-handler /srv public
new-remote srv1 local "app" \
url-path "/app/manage-keys/op=add/key=key1/data=data1" \
environment "GG_SILENT_HEADER"="yes"
new-remote srv2 local "app" \
url-path "/app/manage-keys/op=add/key=key2/data=data2" \
environment "GG_SILENT_HEADER"="yes"
new-remote srv3 local "app" \
url-path "/app/manage-keys/op=add/key=key3/data=data3" \
environment "GG_SILENT_HEADER"="yes"
call-remote srv1, srv2, srv3 status st \
started start \
finished-okay fok
if-true st equal GG_OKAY
@No errors from call-remote
end-if
if-true start equal 3
@All three service calls started.
end-if
if-true fok equal 3
@All three service calls finished.
end-if
read-remote srv1 data rdata1
read-remote srv2 data rdata2
read-remote srv3 data rdata3
print-out rdata1
@
print-out rdata2
@
print-out rdata3
@
end-handler
Copied!
Create the application:
sudo mgrg -i -u $(whoami) app
Copied!
Make it:
gg -q
Copied!
Run it:
mgrg -w 1 app
Copied!
gg -r --req="/srv" --exec --silent-header
Copied!
And the result is (assuming you have started hash example above):
No errors from call-remote
All three service calls started.
All three service calls finished.
Added [key1]
Added [key2]
Added [key3]
Copied!
Distributed computing
call-remote
new-remote
read-remote
run-remote
See all
documentation
New string
Purpose: Create a new string.
new-string <variable> length <length>
Copied!
New empty string <variable> of length <length> is allocated. The <variable> is an empty string (i.e. ""), however <length> bytes are allocated.
new-string is useful when you need to create a block of memory of certain length, and then change its individual bytes (such as with set-string).
Note that if <length> is a numeric literal, then <variable> will be allocated statically if <length> is lesser than 1024 bytes; this makes such strings faster at run time, especially for server processes. In all other cases, <variable> is dynamically allocated from the heap.
Also note that <variable> (like all strings, text, binary and however allocated) has an implicit null byte placed after <length> bytes.
Create new string and alter it with new content and to be of length 2:
new-string my_string length 30
set-string my_string[0] = 'A'
set-string my_string[1] = 'B'
set-string my_string length 2
print-out my_string new-line
Copied!
The output of above code would be "AB".
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
New tree
Purpose: Create new tree structure for fast key searching.
new-tree <tree> \
[ key-as "positive integer" ] \
[ unsorted ]
[ process-scope ]
Copied!
new-tree initializes a new <tree>.
An tree is a hierarchical balanced binary tree structure that allows data access in O(log N) time, meaning that at most approximately "log N" comparisons are needed to find a key in it. For instance, that would mean to find a key among 1,000,000 keys it would take at most about 20 comparisons. By default (if "unsorted" is omitted), finding the next lesser or greater key is O(1), meaning iterating in a sorted order is nearly instantaneous. A tree is a hybrid tree structure (taking elements from both B and AVL varieties) optimized for in-memory access.
Information in a tree can be inserted, updated or deleted in any order, and accessed in any order as well.
Information in a tree is organized in nodes. Each node has a key and a value. A key is used to search for a node in a tree. By default (if "unsorted" is omitted), all nodes in a Golf tree are also connected in an ordered linked list, allowing for very fast range searches.
A node in a tree consists of two strings: key and value. There is no limit on the number of nodes in the tree, other than available memory. Each key in the tree must be unique. Keys should be as short as possible. Generally, longer keys take longer to search for, insert or delete.
In order for any data tree structure to function, a key comparison must be performed certain number of times in order to find a specific key. Keys are compared using C's strcmp() function, meaning using ASCII lexicographic order.
"key-as" clause allows one to treat a key as something other than a string when it comes to ordering. When "positive integer" value is used, it will treat a key as a string representation of a positive integer number. Such numbers must be zero or positive integers in the 64 bit range, and they must not contain leading zeros, spaces or other prefix (or suffix) characters. For example, key strings may be "0", "123" or "891347". With this clause, sorting these strings according to their converted numerical values is much faster than using schemes such as prefixing numbers with zeros or spaces.
Note that when using "positive integer", you can use numbers in any base (from 2 to 36). In fact, numbers expressed in a higher base are generally faster to search for, because they are shorter in length.
If "unsorted" clause is used, <tree> will not be sorted in a double-linked list, which means that finding the next smaller or next greater node in repetition (i.e. range search) will be done by using the tree structure and not a linked list. This is slower, as each such search is generally done in O(log N) time. Regardless, you can perform range searches in either case (see use-cursor).
As a rule of thumb, if you do not need range searches or your memory is scarce, use "unsorted" as it will save 2 pointers (i.e. 16 bytes) per key and insertion/deletion will be a bit faster, but be aware that range searches will be slower.
If you need faster range searches or the extra memory is not an issue (it would be for instance extra 16MB per 1,0000,0000 keys), then do not use "unsorted", as your range searches will be faster. Note that in this case, insertion and deletion are a bit slower because they need to maintain a double linked list, however in general the effect is minimized by faster range searches.
A tree is accessible to the current process only, unless "process-scope" clause is used, in which case all requests served by the process can use it (see do-once for a typical way to create an object with a process scope). If "process-scope" is used, then <tree> that will keep its nodes between all requests served by the same process; otherwise <tree> is purged at the end of request.
Create a new tree:
new-tree my_tree
Copied!
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Number expressions
A number expression uses operators plus (+), minus (-), multiply (*), divide (/), modulus (%), bitwise operators (& for and, | for or, ^ for xor and ~ for negation) as well as parenthesis (). For example:
set-number n1 = 10+(4*n2-5)%3
Copied!
You can use number expressions anywhere number is expected as an input to any statement.
Note that character constants (such as 'A', 'z' etc.) are considered numbers with the value equal to their single-byte ASCII equivalent (i.e. unsigned numbers 0-255), for example this will assign 65 to "num":
set-number num = 'A'
Copied!
Any subscripted string is also considered a number, for instance "num" would be 117 (since 's' is 115):
set-string str = 'some'
set-number num = str[0] + 2
Copied!
Other than decimals and character constants, you can also use hexadecimal numbers (such as 0xffaa), and octal numbers (such as 0710).
You can access each byte of a string as an unsigned 8-bit number:
set-string str = "GOAT"
set-string num = 10+str[2]
Copied!
Variable num will have a value of 75 (10+'A' or 10+65).
You can reference number arrays elements (see new-array) by using subscription operator ([]), for instance:
new-array narr type number
write-array narr key 0 value 10
write-array narr key 1 value narr[0]
set-number n = 1 + narr[1] * 2
Copied!
Numbers
abs-number
number-expressions
number-string
set-number
string-number
See all
documentation
Number string
Purpose: Convert number to string.
number-string <number> [ to <string> ] \
[ base <base> ] \
[ status <status> ]
Copied!
<number> is converted to <string> in "to" clause, using <base> in "base" clause, where <base> is by default 10. <base> can be between 2 and 36, inclusive. <number> can be positive or negative (i.e. signed) and can be of any integer type up to 64-bit (char, int, long, long long etc.). If "to" clause is omitted, then <number> is printed out.
Note that any letters in <string> (depending on the <base>) are always lower-case.
If there is an error, such as if <base> is incorrect, then <status> number (in "status" clause) is GG_ERR_FAILED, otherwise it's GG_OKAY.
If number-string prints out a number (i.e. "to" clause is omitted), and this is within write-string, then <number> is output into the buffer that builds a new string.
For convenience, you can use a shortcut for converting a string to a number, by prepending a "$" sign to the variable name, for example:
set-number n = -10
set-string s = "This is number " + $n
Copied!
The above is the same as:
set-number n = -10
number-string n to sval
set-string s = "This is number " + sval
Copied!
Effectively, $ in front of a number variable is the same as number-string that converts it to a string with the base of 10. If a string cannot be converted to a number, your program will error out. To check values with a status, or to use different bases, use number-string.
You can use $ for an expression, in which case the expression must be within parenthesis:
set-number n1 = -10
set-number n2 = 15
set-string s = "This is number " + $(n1+n2)
Copied!
In this case number "s" will have value of "This is number 5", because numbers -10 and 15 are added to produce 5, which is then converted to a string and finally added to the first string.
The following will allocate memory for string "x" to be "801":
set-number x = 801
number-string x to res
Copied!
The following will store "-238f" to string "res":
set-number x = -9103
number-string x to res base 16
Copied!
To print out a number -131:
set-number x = -131
number-string x
Copied!
Numbers
abs-number
number-expressions
number-string
set-number
string-number
See all
documentation
Open file
Purpose: Open file for reading and writing.
open-file <file name> file-id <file id> \
[ new-truncate ] \
[ status <status> ]
Copied!
Opens file given by <file name> for reading and writing and creates an open file variable identified by <file id>.
<file name> can be a full path name, or a path relative to the application home directory (see directories).
You can obtain the status of file opening via <status> number (in "status" clause). The <status> is GG_OKAY if file is opened, or GG_ERR_OPEN if could not open file.
If "new-truncate" clause is used, a new file is created if it doesn't exist, or it is truncated if it does.
Create a file (or truncate an existing one), write 25,000 rows and the read back those rows and display them, then close file:
%% /ofile public
open-file "testwrite" file-id nf new-truncate
start-loop repeat 25000 use i
(( line
@some text in line <<print-out i>>
)) notrim
string-length line to line_len
write-file file-id nf from line length line_len
end-loop
file-position set 0 file-id nf
read-file file-id nf to whole_file
print-out whole_file
close-file file-id nf
%%
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Out header
Purpose: Output HTTP header.
out-header default
|
out-header use \
[ content-type <content type> ] \
[ download [ <download> ] ] \
[ etag [ <etag> ] ] \
[ file-name <file name> ] \
[ ( cache-control <cache control> ) | no-cache ] \
[ status-id <status id> ] \
[ status-text <status text> ] \
[ custom <header name>=<header value> [ , ... ] ]
Copied!
out-header outputs HTTP header and also sends any cookies produced by set-cookie and delete-cookie. A web page must have an HTTP header output before any other response.
If out-header is not used, a default HTTP header is sent out just before the very first output (see output-statement, print-out etc.) at which point any cookie updates are sent as well; this default header is the same as using "out-header default".
If you use out-header multiple times, all but the very first one are ignored.
If you wish to output a file (such as an image or a PDF document), do not use out-header; rather use send-file instead which outputs its own header.
The HTTP header is sent back to a client who initiated a request. You can specify any custom headers with "use" clause.
Default header
If no out-header is used, or if "default" clause is in place, a default header is constructed, which uses a status of 200/OK and content type of
text/html;charset=utf-8
Copied!
and cache control of
Cache-Control:max-age=0, no-cache; Pragma: no-cache
Copied!
The default header is typical for dynamically generated web pages, and most of the time you would use the default header - meaning you don't need to specify out-header statement.
Headers
The following are subclauses that allow setting any custom header:
- <content type> is content type (such as "text/html" or "image/jpg" etc.) If you are sending a file to a client for download and you don't know its content type, you can use "application/octet-stream" for a generic binary file.
- If "download" is used without boolean variable <download>, or if <download> evaluates to true, then the file is sent to a client for downloading - otherwise the default is to display file in client.
- <file name> is the name of the file being sent to a client. This is not the local file name - it is the file name that client will use for its own purposes.
- <cache control> is the cache control HTTP header. "no-cache" instructs the client not to cache. Only one of "cache-control" and "no-cache" can be used. An example of <cache control>:
send-file "somepic.jpg" headers cache-control "max-age: 3600"
Copied!
- If "etag" is used without boolean variable <etag>, or if <etag> evaluates to true, then "ETAG" header will be generated (a timestamp) and included, otherwise it is not. The time stamp is of last modification date of the file (and typically used to cache a file on client if it hasn't changed on the server). "etag" is useful to let the client know to download the file only once if it hasn't changed, thus saving network and computing resources. ETAG header is used only for send-file.
- <status id> and <status text> are status settings for the response, as strings (such as "425" for "status-id" and "Too early" for "status-text").
- To set any type of generic HTTP header, use "custom" subclause, where <header name> and <header value> represent the name and value of a single header. Multiple headers are separated by a comma. There is no limit on the maximum number of such headers, other than of the underyling HTTP protocol. You must not use "custom" to set headers already set elsewhere (such as "etag" for instance), as that may cause unpredictable behavior. For instance this sets two custom headers:
out-header use custom "CustomOption3"="CustomValue3", "Status"="418 I'm a teapot"
Copied!
"custom" subclause lets you use any custom headers that exist today or may be added in the future, as well as any headers of your own design.
You can use silent-header before output-header in order to suppress its output.
Sometimes you may want to output the default header immediately, for instance if the first output produces may take some time:
out-header default
Copied!
To set a custom header for a web page that changes cache control and adds two new headers:
out-header use content-type "text/html" cache-control "max-age:3600" custom "some_HTTP_option"="value_for_some_HTTP_option", "some_HTTP_option_1"="value_for_some_HTTP_option_1"
Copied!
Web
call-web
out-header
send-file
silent-header
See all
documentation
Output statement
Purpose: Output text.
@<text>
!<verbatim text>
Copied!
Outputting free form text is done by starting the line with "@" or "!". The text is output unencoded with a new line appended.
With "@" statement, any inline-code executes and any output from those statements is output.
With "!" statement, all text is output verbatim, and any inline code is not executed. This is useful when the text printed out should not be checked for any inline-code.
All trailing whitespaces are trimmed from each source code line. If you need to write trailing whitespaces, with "@" statement you can use print-out as inline-code. Maximum line length is 8KB - this is the source code line length, the actual run-time output length is unlimited.
Note that all characters are output as they are written, including the escape character (\). If you wish to output characters requiring an escape character, such as new line and tab (as is done in C by using \n, \t etc.), use print-out as inline-code.
Outputting "Hello there":
@Hello there
Copied!
You can use other Golf statements inlined and mixed with the text you are outputting:
set-string weatherType="sunny"
@Today's weather is <<print-out weatherType>>
Copied!
which would output
Today's weather is sunny
Copied!
With "!" statement, the text is also output, and this example produces the same "Hello there" output as "@":
!Hello there
Copied!
In contrast to "@" statement, "!" statement outputs all texts verbatim and does not execute any inline code:
set-string weatherType="sunny"
!Today's weather is <<print-out weatherType>>
Copied!
which would output
Today's weather is <<print-out weatherType>>
Copied!
Output
finish-output
flush-output
output-statement
print-format
print-out
print-path
See all
documentation
Pause program
Purpose: Pause request execution.
pause-program <milli seconds>
Copied!
pause-program will delay request execution (i.e. sleep, meaning not utilize computing resources) for a number of <milli seconds>. For instance:
pause-program 1500
Copied!
will pause for 1.5 seconds.
Pause execution for 0.25 seconds:
pause-program 250
Copied!
Time
get-time
pause-program
See all
documentation
Permissions
File and directory permissions are given with standard Linux permissions. A permission "mode" is typically given as an octal number (such as 0750), where each digit is made of read (carrying value of 4), write (carrying value of 2) and execute/search permissions (carrying value of 1), so for example 7 means having read, write and execute/search permissions (since 7=4+2+1). The first digit refers to permissions given to user, second digit to those given to user's group, and third digit to those given to everyone.
Files in Golf directories are generally created with 700 privileges, meaning only the user who owns the application can access them and other users (even within the same group) cannot. The same goes for directories created by new-dir by default, unless "mode" specifies differently.
Files created by Golf (including open-file and write-file) are created with 600 permissions, meaning only the user who owns the application can access them and other users (even within the same group) cannot.
You can use stat-file to obtain permission mode for a file or directory, and change-mode to set it. Note that, most of the time, you won't need to do this at all. If you do, however, you should change permission modes carefully and keep in mind the implications for both your application's security and functionality.
General
about-golf
devel-versus-release
directories
permissions
See all
documentation
Position list
Purpose: Set current element in a linked list.
position-list <list> \
[ first | last | end | previous | next | \
[ status <status> ]
Copied!
position-list changes the current element of linked <list>. A current element is the one that is read with read-list. A newly added element is written with write-list by inserting it just before the current element, thus becoming a new current element. Reading from <list> does not change its current element; use position-list to explicitly change it.
To position to the first element, use "first" clause. Use "last" clause to make the last element the current one. Use "previous" and "next" to change the current element to just before or just after it.
A position just beyond the last element in <list> is considered the "end" of it; in this case write-list will append an element to <list> and this element becomes its last, which is equivalent to using write-list statement with "append" clause.
Use "end" clause to set current element to <list>'s end. Note that "end" clause is equivalent to using "next" clause on the last element in <list>.
If you attempt to position prior to the first element, after the end of <list>, or anywhere in an empty list, then <status> number (in "status" clause") is GG_ERR_EXIST, otherwise it is GG_OKAY. Note that if <status> is GG_ERR_EXIST, the current element will not change.
Position to the next element in list:
position-list mylist next status st
if-true st equal GG_ERR_EXIST
@Beyond the end of list
end-if
Copied!
Position to the first element in list:
position-list mylist first
Copied!
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
Postgresql database
Postgres database configuration file has a Postgres connection string.
You can see the parameters available at https://www.postgresql.org/docs/14/libpq-connect.html#LIBPQ-CONNSTRING.
Most of the time, though, you may be using only a few of those options, as in:
user=myuser password=mypwd dbname=mydb
Copied!
The above file has parameters "user" (Postgres user), "password" (the password for Postgres user), "dbname" (the Postgres database name). If you use peer-authenticated (i.e. passwordless) login, then omit "password" - this is when the Postgres user name is the same as your Operating System user name and where local unix domain socket is used for authentication.
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Print format
Purpose: Outputs formatted data.
print-format <format> , <variable> [ , <variable> ]... \
[ to-error ] \
[ to <string> ] [ url-encode | web-encode ]
Copied!
print-format will format a string according to the <format> string and a list of <variable>s and then outputs the result. By default, the output is not encoded (meaning a string is output exactly as it is, and the client may interpret such text in any way it sees fit). If "web-encode" clause is used, then the output is web-encoded (or HTML-encoded);this means such output is suited for use in web pages - meaning any HTML-markup will be properly encoded. If "url-encode" clause is used, then the output is URL-encoded; this means such output is suited for use in URL parameters.
<format> string must be a literal. Variables must follow <format> separated by commas in the same order as placeholders. If you use any placeholders other than specified below, or the type of variables you use do not match the type of a corresponding placeholder in <format>, your program will error out. You can use the following placeholders in <format>:
- %s for a string
- %c for a number displayed as a character,
- %<number>s for a string output with a width of at least <number> (any excess filled with spaces to the left),
- %ld for a 64-bit signed number. Use "lo" for displaying in octal notation and "lx" for hexadecimal notation.
- %<number>ld for a 64-bit signed number output with a width of at least <number> (any excess filled with spaces to the left). Use "lo" for displaying in octal notation and "lx" for hexadecimal notation.
- %hd for a 32-bit signed number. Use "hu" for displaying as unsigned number, "ho" for displaying in octal notation and "hx" for hexadecimal notation.
- %<number>hd for a 32-bit signed number output with a width of at least <number> (any excess filled with spaces to the left). Use "ho" for displaying as unsigned number, "ho" for displaying in octal notation and "hx" for hexadecimal notation.
- %hhd for a signed 8-bit number. Use "hhu" for displaying as unsigned number, "hho" for displaying in octal notation and "hhx" for hexadecimal notation.
- %<number>hhd for a number output with a width of at least <number> (any excess filled with spaces to the left). Use "hhu" for displaying as unsigned number, "hho" for displaying in octal notation and "hhx" for hexadecimal notation.
If "to-error" clause is used, the output is sent to "stderr", or standard output stream.
If "to" clause is used, then the output of print-format is stored into <string>.
To output data (the string output is "the number is 20"):
print-format "%s is %d", "the number", 20
Copied!
Create a query text string by means of write-string statement:
/ Construct the run-time text of dynamic SQL
write-string qry_txt
@select * from <<print-format "%s where id="%ld", table_name, id_num>>
end-write-string
Copied!
This example of web encoding displayes text containing HTML tags without them being rendered in the browser:
print-format "We use %s markup", "<hr/>" web-encode
Copied!
Here's an example of URL encoding. It creates a URL based on arbitrary strings used as URL parameters - for instance space would be encoded as "%20" in the final output:
@<a href='<<print-path "/update">>?val=<<print-format "Purchased %s for %ld dollars", piece_desc, price url-encode>>'>Log transaction</a>
Copied!
Output
finish-output
flush-output
output-statement
print-format
print-out
print-path
See all
documentation
Print out
Purpose: Print data out.
print-out ( ( <string> [ length <length> ] [ url-encode | web-encode ] [ new-line ] )
| <number> new-line
| source-file [ new-line ]
| source-line [ new-line ] ) , ...
Copied!
print-out outputs various kinds of data:
- A <string> is output:
print-out <string> [ <length> ] [ url-encode | web-encode ] [ new-line ]
Copied!
- By default, <string> is output without any encoding (meaning a string is output exactly as it appears). To output data verbatim to a client:
set-string mydata="Hello world"
print-out mydata
Copied!
Writing to client, outputting text followed by a horizontal rule - the text is output to a client (such as browser) as it is, and the browser will interpret tags "<br/>" and "<hr/>" as a line break and a horizonal line and display them as such:
print-out "This is a non-encoded output<br/>" new-line
print-out "<hr/>"
Copied!
Create a query text string by means of write-string statement:
write-string qry_txt
@select * from <<print-out table_name>>
end-write-string
Copied!
- If "url-encode" clause is used, then the output is URL-encoded. This means such output is suited for use in URL parameters. Create a URL based on arbitrary strings used as URL parameters - for instance a space would be encoded as "%20" in the final output:
@<a href='<<print-out "/update">>?item=<<print-out item_name url-encode>>'>Update</a>
Copied!
If "web-encode" clause is used, then the output is web-encoded (or HTML-encoded). This means such output is suited for use in web pages - the text will be displayed verbatim without HTML-markup being interpreted. Display "We use <hr/> markup" text, without "<hr/>" being displayed as a horizontal line:
print-out "We use <hr/> markup" web-encode
Copied!
If "length" clause is used, then only <length> leading bytes of <string> are output.
If "new-line" clause is used, then a new line ("\n") is output after <string>.
Note that all bytes of <string> are output, even if <string> contains null-bytes.
- Outputs a number, given by <number>:
print-out <number> [ new-line ]
Copied!
If "new-line" clause is used, then a new line ("\n") is output after <number>.
To output a number to a client:
set-number x = 100
print-out x
Copied!
- Outputs a boolean, given by <bool>:
print-out <bool> [ new-line ]
Copied!
If "new-line" clause is used, then a new line ("\n") is output after <bool>. The value of <bool> is output as 1 if true, and 0 if false.
To output a boolean to a client (outputs 1):
set-bool b = true
print-out b
Copied!
- Outputs the file name of the current source file.
print-out source-file [ new-line ]
Copied!
This outputs the file name (relative to the source code directory) of the source file where the statement is located; this is often used for debugging.
If "new-line" clause is used, then a new line ("\n") is output afterwards.
@This file is <<print-out source-file>>
Copied!
- Outputs current line number in the source file.
print-out source-line [ new-line ]
Copied!
This outputs the line number in the source file where the statement is located. It is often used for debugging purposes.
If "new-line" clause is used, then a new line ("\n") is output afterwards.
@This line is #<<print-out source-line>>
Copied!
You can specify a list of expressions separated by a comma to print them out in the order specified, with the end result the same as if they were separate print-outs, for instance:
print-out str new-line, num, " some string ", str1 web-encode new-line
Copied!
In this case, you'll be outputting string "str", number "num", a string constant " some string ", and a web-encoded string "str1". There are no whitespaces between each item output.
Output
finish-output
flush-output
output-statement
print-format
print-out
print-path
See all
documentation
Print path
Purpose: Print out URL that leads to a request handler.
print-path <request path> [ new-line ]
Copied!
print-path outputs URL application path of a URL that called this request handler, followed by string <request path>.
If no "--path" option in gg is used to specify URL application path, then it is the same as application name prepended with a forward slash, followed by "/<request path>":
/<app name>/<request path>
Copied!
print-path is used in construction of URLs or HTML forms (either for HTML or API) to refer back to the same application. Use it to create the absolute URL path to refer back to a service of yours so you can issue requests to it.
For example, this is a link that specifies request to service "/show-notes":
@<a href="<<print-path "/show-notes">>?date=yesterday">Show Notes</a>
Copied!
If you are building HTML forms, you can add a note with:
@<form action='<<print-path "/add-note">>' method="POST">
@<input type="text" name="note" value="">
@</form>
Copied!
See request for more on URL structure.
If "new-line" clause is used, then a new line ("\n") is output after the URL path.
Output
finish-output
flush-output
output-statement
print-format
print-out
print-path
See all
documentation
Purge array
Purpose: Purge an array.
purge-array <array>
Copied!
purge-array deletes all elements from <array> that was created with new-array.
After purge-array, you can use it without calling new-array again; the array is initialized as if it was just created that way.
Create an array, put some data in it and then delete the data:
new-array arr
write-array arr key 50 value "myvalue"
purge-array arr
Copied!
See read-array for more examples.
Array
new-array
purge-array
read-array
write-array
See all
documentation
Purge fifo
Purpose: Delete FIFO list data.
purge-fifo <list>
Copied!
purge-fifo will delete all elements from the FIFO <list>, created by new-fifo. The list is then empty and you can still put data into it, and get data from it afterwards, without having to call new-fifo again.
All keys or values stored in the list are also deleted.
See read-fifo.
FIFO
delete-fifo
new-fifo
purge-fifo
read-fifo
rewind-fifo
write-fifo
See all
documentation
Purge hash
Purpose: Purge a hash.
purge-hash <hash>
Copied!
purge-hash deletes all elements from <hash> that was created with new-hash.
After purge-hash, you can use it without calling new-hash again. Note however, that "average-reads" statistics (see get-hash) is not reset - it keeps being computed and remains for the life of the hash.
Create a hash, put some data in it and then delete the data:
new-hash h
write-hash h key "mykey" value "myvalue"
purge-hash h
Copied!
See read-hash for more examples.
Hash
get-hash
new-hash
purge-hash
read-hash
resize-hash
write-hash
See all
documentation
Purge lifo
Purpose: Delete LIFO list data.
purge-lifo <list>
Copied!
purge-lifo will delete all elements from the LIFO <list> created by new-lifo, including all keys and values. The list is then empty and you can still put data into it, and get data from it afterwards, without having to call new-lifo again.
See read-lifo.
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
Purge list
Purpose: Delete linked list data.
purge-list <list>
Copied!
purge-list will delete all elements (including their keys and values) from the linked <list>, created by new-list. The list is then empty and you can still put data into it, and get data from it afterwards, without having to call new-list again.
See read-list.
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
Purge tree
Purpose: Delete all tree nodes.
purge-tree <tree>
Copied!
purge-tree will delete all <tree> nodes; <tree> must have been created with new-tree. All of <tree>'s nodes, and their keys/values all deleted.
After purge-tree, the tree is empty and you can use it again (write into it, read from it etc.).
Delete all tree data:
new-tree mytree
...
purge-tree mytree
Copied!
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Quit process
Purpose: Quit the current process.
quit-process
Copied!
quit-process will properly terminate the current request and its running process (be it service or command-line). It does that by sending itself a SIGTERM signal and then executing the process wind-down.
quit-process may be used to stop the service processes (or restart them if setup) in rare cases where you wish to do so programmatically instead of using mgrg.
quit-process
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Random crypto
Purpose: Obtain a random string for cryptographic use.
random-crypto to <random string> \
[ length <string length> ]
Copied!
random-crypto obtains a random string of length <string length>. This statement uses a cryptographically secure pseudo random generator (CSPRNG) from OpenSSL library. If "length" clause is omitted, the length is 20 by default.
The value generated is always binary and may contain null-characters and is null-terminated.
Use this statement only when needed for specific cryptographic uses. In all other cases, use random-string which is considerably faster.
Get a 20-digit long random binary value:
random-crypto to str length 20
Copied!
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
Random string
Purpose: Obtain a random string.
random-string to <random string> \
[ length <string length> ] \
[ number | binary ]
Copied!
random-string obtains a random string of length <string length>. If "length" clause is omitted, the length is 20 by default.
If "number" clause is used, then the resulting string is composed of digits only ("0" through "9").
If "binary" clause is used, then the resulting string is binary, i.e. each byte can have an unsigned value of 0-255.
By default, if neither "number" or "binary" is used, the resulting string is alphanumeric, i.e. digits ("0" through "9") and alphabet letters ("a"-"z" and "A"-"Z") are used only.
Random generator is based on the Linux random() generator seeded by local process properties such as its PID and time. A single process is seeded once, and thus any number of requests served by the same process will use a subset of the process' random sequence. Due to joint entropy, each result given to any request is random, not just within a single request, but among any number of different requests.
Get a 100-digit long random value (as an alphanumeric string):
random-string to str length 100
print-format "%s\n", str
Copied!
Get a random number of length 10 in string representation:
random-string to str length 10 number
print-format "%s\n", str
Copied!
Get a random binary value that is 8 bytes in length - this value may contain null bytes (i.e. it will contain bytes with values ranging from 0 to 255):
random-string to str length 8 binary
Copied!
Encryption
decrypt-data
derive-key
encrypt-data
hash-string
hmac-string
random-crypto
random-string
See all
documentation
Read array
Purpose: Get data from an array.
read-array <array> \
key <key> \
value <value> \
[ delete [ <delete> ] ]
[ status [ <status> ] ]
Copied!
read-array will obtain an element from <array> (that was created with new-array); an element obtained is <value> (in "value" clause) based on a number <key> (in "key" clause). <key> is a number from 0 up to (excluding) the currently allocated array size. The type of <value> is determined when <array> is created (see "type" clause), and can be either a string, number or a boolean.
You can also delete an element from the array by using "delete" clause - the <value> is still obtained though it is no longer in the array. The array element is deleted if "delete" clause is used without boolean variable <delete>, or if <delete> evaluates to true. "Deleting" means that an element will no longer hold a valid value; when such an element is read, for a string array it would be an empty string, for a number array it would be 0, and for a boolean array it would be false. The only way to distinguish those from existing array elements with the same values is to obtain <status> number variable (in "status" clause), which is GG_OKAY if an array element is set and not deleted, or GG_ERR_EXIST if an array element was never set or was deleted.
Note that array may be allocated beyond the highest index of an element written to it; reading from such elements that have never been written to will produce an empty string, a number 0 or a boolean false value (depending on the type of array).
You can also get the value of an <array> element by using subscription operator ([]), for instance here you'd reference the 3rd element of array 'arr' in the comparison statement:
new-array arr type number
write-array arr key 3 value 20
if-true arr[3] equal 20
@Yes it's 20
end-if
Copied!
This works for any array type, so you can use the subscriptive form of <array>[<index>] in any expression, where <index> is a number.
In this example, a new array is created, a value is written to it, and then the value is obtained and the element deleted:
new-array arr type string
write-array arr key 500 value "some data"
read-array arr key 500 value res delete
@Deleted value is <<print-out res>>
Copied!
Array
new-array
purge-array
read-array
write-array
See all
documentation
Read fifo
Purpose: Reads key/value pair from a FIFO list.
read-fifo <list> \
key <key> \
value <value> \
[ status <status> ]
Copied!
read-fifo retrieves an element from the FIFO <list> into <key> string (in "key" clause) and <value> string (in "value" clause).
Once an element has been retrieved, the next use of read-fifo will obtain the following one, in the same order they were put in. read-fifo starts with the first element put in, and moves forward from there, unless rewind-fifo is called, which positions back to the first one.
If the element is successfully retrieved, <status> number (in "status" clause) is GG_OKAY, otherwise it is GG_ERR_EXIST, which means there are no more elements to retrieve.
In this example, a FIFO list is created, and two key/value pairs added. They are then retrieved in a loop and printed out (twice with rewind), and then the list is purged:
new-fifo mylist
write-fifo mylist key "key1" value "value1"
write-fifo mylist key "some2" value "other2"
start-loop
read-fifo mylist key k value v status st
if-true st not-equal GG_OKAY
break-loop
end-if
@Obtained key <<print-out k>> with value <<print-out v>>
end-loop
rewind-fifo mylist
start-loop
read-fifo mylist key k value v status st
if-true st not-equal GG_OKAY
break-loop
end-if
@Again obtained key <<print-out k>> with value <<print-out v>>
end-loop
purge-fifo mylist
Copied!
FIFO
delete-fifo
new-fifo
purge-fifo
read-fifo
rewind-fifo
write-fifo
See all
documentation
Read file
Purpose: Read file into a string variable.
read-file <file> | ( file-id <file id> ) \
to <content> \
[ position <position> ] \
[ length <length> ] \
[ status <status> ] \
[ end-of-file <eof> ]
Copied!
This is a simple method of reading a file. File named <file> is opened, data read, and file is closed.
<file> can be a full path name, or a path relative to the application home directory (see directories).
Data read is stored into string <content>. Note that file can be binary or text and <content> may have null-bytes.
If "position" and "length" clauses are not specified, read-file reads the entire <file> into <content>.
If "position" clause is used, then reading starts at byte <position>, otherwise it starts at the beginning of the file. Position of zero (0) represents the beginning of the file.
If "length" clause is used, then <length> number of bytes is read, otherwise the rest of the file is read. If <length> is 0, <content> is empty string and <status> is 0.
If "status" clause is used, then the number of bytes read is stored to <status>, unless error occurred, in which case <status> is negative and has the error code. The error code can be GG_ERR_POSITION (if <position> is negative, outside the file, or file does not support it), GG_ERR_READ (if <length> is negative or there is an error reading file) or GG_ERR_OPEN if file cannot be opened. If the number of bytes read isn't what's requested, you can use "end-of-file" clause to get boolean <eof>, which is true if the end of file happened, or false if there is an error (in which case you can use "errno" clause in get-req to obtain the actual reason for error).
This method uses a <file id> that was created with open-file. You can then read (and write) file using this <file id> and the file stays open until close-file is called, or the request ends (i.e. Golf will automatically close any such open files).
Data read is stored into string <content>. Note that file can be binary or text and <content> may have null-bytes.
If "position" clause is used, then data is read starting from byte <position> (with position of 0 being the first byte), otherwise reading starts from the current file position determined by the previous reads/writes or as set by using "set" clause in file-position. Note that after each read or write, the file position is advanced by the number of bytes read or written.
If "length" clause is used, then <length> number of bytes is read, otherwise the rest of the file is read. If <length> is 0, <content> is empty string and <status> is 0.
Note that when you reach the end of file and no more bytes can be read, <status> is 0.
If "status" clause is used, then the number of bytes read is stored to <status>, unless error occurred, in which case <status> has the error code. The error code can be GG_ERR_POSITION (if <position> is negative, outside the file, or file does not support it), GG_ERR_READ (if <length> is negative or there is an error reading file) or GG_ERR_OPEN if file is not open. If the number of bytes read isn't what's requested, you can use "end-of-file" clause to get boolean <eof>, which is true if the end of file happened, or false if there is an error (in which case you can use "errno" clause in get-req to obtain the actual reason for error).
To read the entire file and create both the variable that holds its content and the status variable:
read-file "/home/user/some_file" to file_content status st
if-true st greater-than 0
@Read:
@<hr/>
print-out file_content web-encode
@<hr/>
else-if
@Could not read (<<print-format "%ld", st>>)
end-if
Copied!
To read 10 bytes starting at position 20 (with position 0 being the first byte):
read-file "/home/user/some_file" to file_content position 20 length 10
Copied!
See open-file for an example with "file-id" clause.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Read hash
Purpose: Get data from hash.
read-hash <hash> \
key <key> \
value <value> \
[ delete [ <delete> ] ] \
[ status <status> ]
read-hash <hash> traverse begin
read-hash <hash> traverse \
key <key> \
value <value> \
[ delete [ <delete> ] ] \
[ status <status> ] \
Copied!
Without "traverse" clause
You can also delete an element from the hash by using "delete" clause - the <value> is still obtained though it is no longer in the hash. The hash element is deleted if "delete" clause is used without boolean variable <delete>, or if <delete> evaluates to true.
If no <key> was found in the hash, <status> number (in "status" clause) is GG_ERR_EXIST and <value> is unchanged, otherwise <status> is GG_OKAY.
- Subscription shortcut
You can also get the value of a <hash> element by using subscription operator ([]), for instance here you'd reference the element "one" of hash 'vals' in the comparison statement:
new-hash sub
write-hash sub key "three" value "some value"
...
if-true sub["three"] equal "some value"
@Found element
end-if
Copied!
You can use the subscriptive form of <hash>[<index>] in any expression, where <index> is a string value that matches the hash key. Note that if element <hash>[<index>] does not exist, the value returned is an empty string (""); use read-hash form to check status or delete an element.
read-hash with "traverse" clause obtains <key> and <value> of the current element, and then positions to the next one. You can also delete this element from the hash by using "delete" clause - the <key> and <value> are still obtained though the element is no longer in the hash. The hash element is deleted if "delete" clause is used without boolean variable <delete>, or if <delete> evaluates to true.
Use "begin" clause to position at the very first element. This is useful if you wish to get all the key/value pairs from a hash - note they are not extracted in any particular order. When there are no more elements, <key> and <value> are unchanged and <status> number (in "status" clause) is GG_ERR_EXIST, otherwise <status> is GG_OKAY.
You may search, add or delete elements while traversing a hash, and this will be reflected in all elements not yet traversed.
In this example, a new hash is created, a key/value pair is written to it, and then the value is obtained and the element deleted; return status is checked:
new-hash h
write-hash h key "X0029" value "some data"
read-hash h key "X0029" value res status f delete
if-true f equal GG_ERR_EXIST
@No data in the hash!
else-if
@Deleted value is <<print-out res>>
end-if
Copied!
The following will traverse the entire hash and display all the data:
read-hash h traverse begin
start-loop
read-hash h traverse key k value r status f
if-true f equal GG_ERR_EXIST
break;
end-if
print-format "Key [%s] data [%s]\n", k, r
end-loop
Copied!
Hash
get-hash
new-hash
purge-hash
read-hash
resize-hash
write-hash
See all
documentation
Read json
Purpose: Read data elements of JSON document.
read-json <json> \
[ key <key> ] \
[ value <value> ] \
[ type <type> ] \
[ next ]
Copied!
read-json reads data elements from <json> variable, which is created with json-doc. A data element is a string <key>/<value> pair of a leaf node, where key (in "key" clause) is a normalized key name, which is the value's name preceded with the names of all objects and array members leading up to it, separated by a dot (".").
The actual <value> is obtained with "value" clause, and the <type> of value can be obtained with "type" clause.
<type> is a number that can be GG_JSON_TYPE_STRING, GG_JSON_TYPE_NUMBER, GG_JSON_TYPE_REAL, GG_JSON_TYPE_BOOL and GG_JSON_TYPE_NULL for string, number, real (floating point), boolean and null values respectively. Note that <value> is always a string representation of these types.
Use "next" clause to move to the next sequential key/value pair in the document, from top down. Typically, you would get a key first, examine if it's of interest to you, and then obtain value. This is because Golf uses "lazy" approach where value is not copied until needed; with this approach JSON parsing is faster. You can use also use "key", "value" and "next" at the same time if you're going through all elements.
If there are no more data elements to read, <type> is GG_JSON_TYPE_NONE.
<key> in "key" clause is a normalized name of any given leaf node in JSON text. This means every non-leaf node is included (such as arrays and objects), separated by a dot ("."), and arrays are indexed with "[]". An example would be:
"menu"."popup"."menuitem"[1]."onclick"
Copied!
See json-doc.
JSON parsing
json-doc
read-json
See all
documentation
Read lifo
Purpose: Reads key/value pair from a LIFO list.
read-lifo <list> \
key <key> \
value <value> \
[ status <status> ]
Copied!
read-lifo retrieves an element from the LIFO <list> into <key> string (in "key" clause) and <value> string (in "value" clause).
Once an element has been retrieved, the next use of read-lifo will obtain the following one, in the reverse order they were put in. read-lifo starts with the last element put in, and moves backwards from there, unless rewind-lifo is called, which positions back to the last one. Note that write-lifo will cause the next read-lifo to start with the element just written, i.e. it implicitly calls rewind-lifo.
If the element is successfully retrieved, <status> number (in "status" clause) is GG_OKAY, otherwise it is GG_ERR_EXIST, which means there are no more elements to retrieve.
In this example, a LIFO list is created, and two key/value pairs added. They are then retrieved in a loop and printed out (twice with rewind), and then the list is purged:
%% /lifo public
new-lifo mylist
write-lifo mylist key "key1" value "value1"
write-lifo mylist key "some2" value "other2"
start-loop
read-lifo mylist key k value v status st
if-true st not-equal GG_OKAY
break-loop
end-if
@Obtained key <<print-out k>> with value <<print-out v>>
end-loop
rewind-lifo mylist
start-loop
read-lifo mylist key k value v status st
if-true st not-equal GG_OKAY
break-loop
end-if
@Again obtained key <<print-out k>> with value <<print-out v>>
end-loop
purge-lifo mylist
rewind-lifo mylist
read-lifo mylist key k value v status st
if-true st not-equal GG_OKAY
@LIFO is empty
end-if
%%
Copied!
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
Read line
Purpose: Read text file line by line in a loop.
read-line <file> to <line content> [ status <status> ] [ delimiter <delimiter> ]
<any code>
end-read-line
Copied!
read-line starts the loop in which a text <file> is read line by line into string <line content>, with end-read-line ending this loop. Once the end of <file> has been reached, or an error occurs, the loop exits.
<file> can be a full path name, or a path relative to the application home directory (see directories).
<status> number will be GG_ERR_READ if there is an error in reading file, or GG_ERR_OPEN if file cannot be opened, or GG_OKAY if end-of-file has been reached. Check for error after end-read-line statement. If a line was read successfully, then <status> is its length.
<line content> is allocated when a line is read and freed just before the next line is read or if there are no more lines to read. If you want to use <line content> outside of this scope, save it or stash it somewhere first.
String <delimiter> separates the lines in the file, and is by default new line, however it can be any character (note that it is a first character of string <delimiter>).
A new line (or a <delimiter>) remains in <line content> if it was present in the file (note that the very last line may not have it).
Use break-loop and continue-loop statements to exit and continue the loop.
To read a text file line by line, and display as a web page with line breaks:
read-line "/home/bear/tmp/ll/filexx" to one_line status st
string-length one_line to line_len
@Line length is <<print-out line_len>>, line is <<print-out one_line web-encode>> status <<print-out st>><br/>
end-read-line
if-true st lesser-than 0
get-req error to err
@Error in reading, error [<<print-out err>>]
end-if
Copied!
To read a text file delimited by "|" character:
read-line "/home/user/dir/file" to one_line status len delimiter '|'
...
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Read list
Purpose: Read/update key/value pair from a linked list.
read-list <list> \
key <key> \
value <value> \
[ update-value <update value> ] [ update-key <update key> ] \
[ status <status> ]
Copied!
read-list retrieves an element from the linked <list>, storing it into <key> string (in "key" clause) and <value> string (in "value" clause). After each read-list, the list's current element remains at the element read; use position-list to move it (for instance to the next one).
If an element could not be retrieved, <status> number (in "status" clause) will be GG_ERR_EXIST and <key> and <value> will be unchanged (this can happen if current list element is beyond the last element, such as for instance if "end" clause is used in position-list statement), otherwise <status> is GG_OKAY.
Initially when the list is created with new-list, read-list starts with the first element in the list. Use position-list to change the default list's current element.
You can update the element's value with "update-value" clause by specifying <update value> string. This update is performed after a <value> has been retrieved, allowing you to obtain the previous value in the same statement.
You can update the element's key with "update-key" clause by specifying <update key> string. This update is performed after a <key> has been retrieved, allowing you to obtain the previous key in the same statement.
In this example, a linked list is created, and three key/value pairs added. They are then retrieved from the last towards the first element, and then again in the opposite direction:
new-list mylist
write-list mylist key "key1" value "value1"
write-list mylist key "key2" value "value2"
write-list mylist key "key3" value "value3"
position-list mylist last
start-loop
read-list mylist key k value v
@Obtained key <<print-out k>> with value <<print-out v>>
position-list mylist previous status s
if-true s equal GG_ERR_EXIST
break-loop
end-if
end-loop
start-loop
read-list mylist key k value v status s
if-true s equal GG_ERR_EXIST
break-loop
end-if
@Again obtained key <<print-out k>> with value <<print-out v>>
position-list mylist next
end-loop
purge-list mylist
Copied!
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
Read message
Purpose: Read key/value from message.
read-message <message> \
key <key> \
value <value> \
[ status <status>
Copied!
read-message reads strings <key> (in "key" clause) and <value> (in "value" clause) from <message>, which must have been created with new-message.
The reading of key/value pairs starts from the beginning of message and proceeds sequentially forward. Once a key/value pair is read it cannot be read again.
<status> number (in "status" clause) will be GG_OKAY for a successful read, GG_ERR_FORMAT if message is not in SEMI format or GG_ERR_LENGTH if message isn't of proper length.
Once a message is read from, it cannot be written to (see write-message).
See new-message.
Messages
get-message
new-message
read-message
SEMI
write-message
See all
documentation
Read remote
Purpose: Get results of a service call.
read-remote <service> \
[ data <data> ] \
[ error <error> ] \
[ status <status> ] \
[ status-text <status text> ] \
[ exit-status <service status> ]
Copied!
Use read-remote to get the results of call-remote created in new-remote; the same <service> must be used in all.
- Getting the reply from server
The service reply is split in two. One part is the actual result of processing (called "stdout" or standard output), and that is "data". The other is the error messages (called "stderr" or standard error), and that's "error". The standard output goes to "data", except from report-error and print-format (with "to-error" clause) which goes to "error". Note that "data" and "error" streams can be co-mingled when output by the service, but they will be obtained separately. This allows for clean separation of output from any error messages.
<data> is the "data" reply of a service call (in "data" clause). <error> is the "error" reply (in "error" clause).
- Getting status of a service call
The status of a service call (as a number) can be obtained in <status> (in "status" clause). This is the protocol status, and it may be:
- GG_OKAY if request succeeded,
- GG_CLI_ERR_RESOLVE_ADDR if host name for TCP connection cannot be resolved,
- GG_CLI_ERR_PATH_TOO_LONG if path name of Unix socket is too long,
- GG_CLI_ERR_SOCKET if cannot create a socket (for instance they are exhausted for the process or system),
- GG_CLI_ERR_CONNECT if cannot connect to server (TCP or Unix alike),
- GG_CLI_ERR_SOCK_WRITE if cannot write data to server (for instance if server has encountered an error or is down, or if network connection is no longer available),
- GG_CLI_ERR_SOCK_READ if cannot read data from server (for instance if server has encountered an error or is down, or if network connection is no longer available),
- GG_CLI_ERR_PROT_ERR if there is a protocol error, which indicates a protocol issue on either or both sides,
- GG_CLI_ERR_BAD_VER if either side does not support protocol used by the other,
- GG_CLI_ERR_SRV if server cannot complete the request,
- GG_CLI_ERR_UNK if server does not recognize record types used by the client,
- GG_CLI_ERR_OUT_MEM if client is out of memory,
- GG_CLI_ERR_ENV_TOO_LONG if the combined length of all environment variables is too long,
- GG_CLI_ERR_ENV_ODD if the number of supplied environment name/value pairs is incorrect,
- GG_CLI_ERR_BAD_TIMEOUT if the value for timeout is incorrect,
- GG_CLI_ERR_TIMEOUT if the request timed out based on "timeout" parameter or otherwise if the underlying Operating System libraries declared their own timeout.
You can also obtain the status text in <status text> (in "status-text" clause); this is a human readable status message which is am empty string (i.e. "") if there is no error (meaning if <status> is GG_OKAY).
- Getting service status
<service status> (in "exit-status" clause) is the return status (as a number) of the code executing a remote service handler; it is conceptually similar to a return value from a function (as a number). The particular service handler you are calling may or may not return the status; if it does, its return status can be sent back via exit-status and/or exit-handler statement.
You must specify at least one value to obtain in read-remote, or any number of them.
See examples in new-remote and call-remote.
Distributed computing
call-remote
new-remote
read-remote
run-remote
See all
documentation
Read split
Purpose: Obtain split string pieces.
read-split <piece number> from <split string> to <piece> [ status <status> ]
Copied!
read-split will read split string pieces from <split string> which is produced by split-string. <piece number> is the number (starting with 1) of the piece to retrieve in string <piece>. <status> number (in "status" clause) is GG_OKAY if successful, or GG_ERR_OVERFLOW if <piece number> is not valid (meaning it's outside of the range of pieces parsed by split-string).
See split-string.
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Read tree
Purpose: Search/update a tree.
read-tree <tree> \
( equal <search key> | lesser <search key> | greater <search key> | \
lesser-equal <search key> | greater-equal <search key> | \
min-key | max-key ) \
[ value <value> ] \
[ update-value <update value> ] \
[ key <key> ] \
[ status <status> ] \
[ new-cursor <cursor> ]
Copied!
read-tree will search <tree> (created with new-tree) for a node with the string key that is:
- equal to <search key> ("equal" clause)
- lesser than <search key> ("lesser" clause)
- greater than <search key> ("greater" clause)
- lesser or equal than <search key> ("lesser-equal" clause)
- greater or equal than <search key> ("greater-equal" clause)
- a minimum key in the tree ("min-key" clause)
- a maximum key in the tree ("max-key" clause)
The <status> in "status" clause will be GG_OKAY if a key conforming to one of these criteria is found, and GG_ERR_EXIST if not.
If a key is found, the value associated with the key can be obtained with "value" clause in <value>; an existing key used to originally insert this value into the tree can be obtained with "key" clause in string <key>. If a key is not found, both <value> and <key> are unchanged.
You can update the value associated with a found key with "update-value" clause by specifying <update value> string. This update is performed after <value> has been retrieved, allowing you to obtain the previous value in the same statement.
If you'd like to iterate the ordered list of keys in a tree, create a <cursor> by using "new-cursor" clause, in which case <cursor> will be positioned on a found tree node. See use-cursor for more on using cursors. Cursors are useful in range searches; typically you'd find a key that is an upper or lower bound of a range and then keep iterating to a lesser or greater value until some criteria is met, such as when the opposite bound is found. Golf treees are by default constructed so that such iterations are O(1) in complexity, meaning each is a single tree node access (see new-tree).
In this example, a million key/value pairs are inserted into a tree, and then each of them is searched for and then displayed back (see write-tree for more on inserting into a tree). Both the key and the data are a numerical value of a key:
%% /tree-example public
new-tree mytree key-as "positive integer"
set-number i
start-loop use i start-with 0 repeat 1000000
number-string i to key
set-string data=key
write-tree mytree key (key) value data
end-loop
start-loop use i start-with 0 repeat 1000000
number-string i to key
read-tree mytree equal (key) status st value data
if-true st not-equal GG_OKAY
@Could not find key <<print-out key>>
else-if
@Found data <<print-out data>> associated with key <<print-out key>>
end-if
delete-string key
end-loop
%%
Copied!
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Read xml
Purpose: Read data elements from XML document.
read-xml <xml> \
[ key <key> ] \
[ value <value> ] \
[ status <status> ] \
[ next ]
Copied!
read-xml reads data elements from <xml> variable, which is created with xml-doc. A data element is a string <key>/<value> pair, where key (in "key" clause) is a normalized key name, which is the current name preceded with the names of all elements leading up to it, separated by a forward slash ("/"). Node that attribute elements end with "@".
The actual <value> is obtained with "value" clause, and the <status> can be obtained with "status" clause. <status> is GG_OKAY if key/value is obtained, and GG_ERR_EXIST if there are no more to get.
Use "next" clause to move to the next sequential key/value pair in the document, from top down as available. Typically, you would get a key first, examine if it's of interest to you, and then obtain value. You can use also use "key", "value" and "next" at the same time if you're going through all elements.
<key> in "key" clause is a normalized name of any given element in XML text. This means every non-leaf element is included, separated by a forward slash ("/"), and arguments end with "@". An example would be, if "onclick" is a element of "menuitem":
menu/popup/menuitem/onclick
Copied!
or if "onclick" is an attribute of "menuitem":
menu/popup/menuitem/onclick/@
Copied!
See xml-doc.
XML parsing
read-xml
xml-doc
See all
documentation
Rename file
Purpose: Renames a file.
rename-file <from file> to <to file> [ status <status> ]
Copied!
rename-file will rename <from file> to <to file>. <status> number is GG_OKAY on success and GG_ERR_RENAME on failure.
<from file> and <to file> must be specified with full paths unless they are in the current working directory (see directories), in which case a name alone will suffice. <from file> and <to file> can be in different directories.
Rename files:
rename-file "/home/u1/d1/f1" to "/home/u1/d2/f2" status st
if-true st equal GG_OKAY
@Rename successful. <br/>
end-if
Copied!
Rename files in the current working directory:
rename-file "f1" to "f2" status st
if-true st equal GG_OKAY
@Rename successful. <br/>
end-if
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Replace string
Purpose: Replaces part of string.
replace-string <string> \
( copy <replacement> ) | ( copy-end <replacement> ) \
[ start-with <start with> ] \
[ length <length> ]
Copied!
replace-string will replace part of <string> with <replacement> string. "copy" clause will make a replacement in the leading part of <string>, while "copy-end" will make a replacement in the trailing part of <string>.
If "length" clause is not used, then the entire <replacement> string is used, otherwise only the <length> leading bytes of it.
If "start-with" clause is used, then <replacement> will be copied starting with byte <start with> in <string> ("0" being the first byte) (with "copy" clause) or starting with <start with> bytes prior to the end of <string> (with "copy-end" clause).
If "start-with" clause is not used, then <replacement> will replace the leading part of <string> (with "copy" clause") or the very last part of <string> (with "copy-end" clause). In either case, the number of bytes copied is determined by whether "length" clause is used or not.
If either "start-with" or "length" is negative, it's the same as if not specified.
After replace-string below, string "a" will be "none string is here":
set-string b="none"
set-string a="some string is here"
replace-string a copy b
Copied!
After replace-string below, string "a" will be "some string is none":
set-string b="none"
set-string a="some string is here"
replace-string a copy-end b
Copied!
In this example, "a" will be "somnontring is here":
set-string b="none"
set-string a="some string is here"
replace-string a copy b start-with 3 length 3
Copied!
In the following example, "a" will be "some string inohere":
set-string b="none"
set-string a="some string is here"
replace-string a copy-end b start-with 6 length 2
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Report error
Purpose: Reports a fatal error.
report-error <format>, <variable> [ , ... ]
Copied!
report-error will report a fatal error. It will format an error message according to the <format> string and a list of <variable>s and then write it to the standard error output; no HTTP header is output specifically for report-error.
In general, before issuing report-error, you would provide an output for the client that is appropriate. report-error's purpose is only to output a message to the standard error output, stop the processing of the current request, and move on to the next one for the service or exit if this is a command-line program; it is your responsibility to provide any meaningful output to the client prior to that.
See error-handling when report-error is called.
<format> string must be present and there must be at least one <variable> (it means if you want to output a simple string literal you still have to use "%s" as format). The reason for this is to avoid formatting errors, and to use formatting in a consistent fashion.
<format> string must be a literal. Variables must follow <format> separated by commas in the same order as placeholders. If you use any placeholders other than specified below, or the type of variables you use do not match the type of a corresponding placeholder in <format>, your program will error out. You can use the following placeholders in <format>:
- %s for a string
- %c for a number displayed as a character,
- %<number>s for a string output with a width of at least <number> (any excess filled with spaces to the left),
- %ld for a 64-bit signed number. Use "lo" for displaying in octal notation and "lx" for hexadecimal notation.
- %<number>ld for a 64-bit signed number output with a width of at least <number> (any excess filled with spaces to the left). Use "lo" for displaying in octal notation and "lx" for hexadecimal notation.
- %hd for a 32-bit signed number. Use "hu" for displaying as unsigned number, "ho" for displaying in octal notation and "hx" for hexadecimal notation.
- %<number>hd for a 32-bit signed number output with a width of at least <number> (any excess filled with spaces to the left). Use "ho" for displaying as unsigned number, "ho" for displaying in octal notation and "hx" for hexadecimal notation.
- %hhd for a signed 8-bit number. Use "hhu" for displaying as unsigned number, "hho" for displaying in octal notation and "hhx" for hexadecimal notation.
- %<number>hhd for a number output with a width of at least <number> (any excess filled with spaces to the left). Use "hhu" for displaying as unsigned number, "hho" for displaying in octal notation and "hhx" for hexadecimal notation.
report-error "Too many input parameters for %s, encountered total of [%ld]", "customer", num_count
Copied!
Error handling
db-error
error-code
error-handling
report-error
See all
documentation
Request body
Purpose: Get the body of an HTTP request.
request-body <request body>
Copied!
request-body stores the request body of an HTTP request into string <request body>.
If the content type of the request is "multipart/form-data", the request body is empty because all the data (including any attached files) can be obtained by using get-param (see file-uploading for files). In all other cases, request body is available.
Typical use of request-body is when some text or binary information is attached to the request, such as JSON for example, though it can be anything else, for example an image, some text, or a PDF document. Usually request body is present for POST, PUT or PATCH requests, but you can also obtain it for GET or DELETE requests, if supplied (for instance identifying a resource may require more information than can fit in a query string), or for any custom request method.
String variable "reqb" will hold request body of a request:
request-body reqb
Copied!
Request data
get-param
request-body
set-param
See all
documentation
Request
Golf applications run by processing requests. A request always takes form of an HTTP request, meaning a URL, an optional HTTP request body, and any environment variables. This is regardless of whether it's a service or a command-line program.
A "request URL" is a URL that an outside caller (such as a web browser) uses to execute your Golf code. Aside from the scheme, domain and port, it's made up of:
- application path,
- request path, and
- URL parameters.
Here's a breakdown of URL structure:
<scheme>://<domain>[:<port>]<application path><request path><parameters>
Copied!
For example, in the following URL:
https://your.website.com/my-app/my-request/par1=val1/par2=val2
Copied!
"/my-app" is application path, "/my-request" is request path and "/par1=val1/par2=val2" are parameters "par1" and "par2" with values "val1" and "val2". Together, application path and request path are called URL path.
The leading part of URL's path is called "application path". By default, application path is the application name (see mgrg with "-i" option) preceded by forward slash ("/"); if it's "shopping", then the default application path is:
/shopping
Copied!
Application name can contain alphanumerical characters and hyphens.
- Customizing application path
You can change the application path by specifying it with "--path" parameter in gg when building; each application must have its own unique path. Note that whatever it may be, the application name must always be its last path segment. For example, if your application name is "shopping", then the application path may be:
/api/v2/shopping
Copied!
An example of specifying the custom application path:
gg -q --path="/api/v2/shopping"
Copied!
Request path follows the application path, for instance:
https://some.web.site/shopping/buy-item
Copied!
In this case the application path is "/shopping" and the request path is "/buy-item". It means that file "buy-item.golf" handles request "/buy-item" by implementing a begin-handler "/buy-item" in it. As another example, file "services/manage-home.golf" (meaning "manage-home.golf" file in subdirectory "services") handles request "/services/manage-home" etc.
The request path must match (fully or partially) the path of the file name that implements it, with source directory being the root ("/"). Here is an example of implementing a request "/buy-item" in file "buy-item.golf":
begin-handler /buy-item public
get-param some_param
@Bought item: <<print-out some_param>>
end-handler
Copied!
As an example of a path hierarchy, such as for example a hierarchy of resources, methods etc, begin-handler may be:
begin-handler /items/wine-collection/red-wine/buy-item public
...
end-handler
Copied!
then the URL to call it would be:
https://some.web.site/shopping/items/wine-collection/red-wine/buy-item
Copied!
and might be implemented in file "items/wine-collection/red-wine/buy-item.golf", meaning under subdirectory "items", then subdirectory "wine-collection", then subdirectory "red-wine", then file "buy-item.golf".
- File/path naming conventions
By default, a request handler would be implemented in a source file whose path matches the request path, either fully or partially.
The simplest example is that "/buy-item" request must be implemented in file "buy-item.golf".
As a more involved example, request handler for "/items/wine-collection/red-wine/buy-item" can be implemented in file "items.golf" or file "items/wine-collection.golf" or file "items/wine-collection/red-wine.golf" or file "items/wine-collection/red-wine/buy-item.golf".
Each of these source files can contain any number of matching requests. For instance, file "items.golf" can contain request handlers for both "/items/wine-collection/red-wine/buy-item" and "/items/beer-collection/ipa-beer/buy-item"; while file "items/wine-collection.golf" can contain request handlers for both "items/wine-collection/red-wine" and "items/wine-collection/white-wine".
By the same token, file "items/wine-collection/red-wine/buy-item.golf" can implement both "/items/wine-collection/red-wine/buy-item" and "/items/wine-collection/red-wine/buy-item/sale" requests, as both requests match the file path.
Note that if you use "--single-file" option in gg, then each source ".golf" file must contain only a single request, and its request path must match the file path fully. So in this case, request handler for "/items/wine-collection/red-wine/buy-item" must be in file "items/wine-collection/red-wine/buy-item.golf", and no other request can be implemented in it.
The actual input parameters follow after the request path, and can be specified in a number of ways. A parameter value is generally URL encoded in any case.
- Path segments
A common way is to specify name and value separated by an equal sign within a single path segment:
https://some.web.site/shopping/buy-item/sku=4811/price=600/
Copied!
This way, you have a readable representation of parameter names and values, while still maintaining the hierarchical form which conveys how are the parameters structured.
Here, the required request path is "/buy-item" and there are two input parameters ("sku" and "price") with values of "4811" and "600" respectively.
- Query string
Parameters can be specified after a question mark in a "name=value" form. For example, the full URL (with the same parameter values as above) may be:
https://some.web.site/shopping/buy-item?sku=4811&price=600
Copied!
- Mixed
You can specify a mix of the above ways to write parameters, for instance the above URL can be written as:
https://some.web.site/shopping/buy-item/sku=4811?price=600
Copied!
- Parameters
A parameter name can be comprised of alphanumeric characters, hyphens and underscores, and it must start with an alphabet character. Any hyphens are converted to underscores for the purpose of obtaining parameter value, see get-param. Do not use double underscore ("__") in parameter names.
Structuring your parameters, i.e. the order in a query path or path segments, and which ones (if any) are in a query string, is determined by you. Regardless of your choices, the code that handles a request is the same. In the example used here, you can obtain the parameters in request handler source file "buy-item.golf":
begin-handler /buy-item public
get-param sku
get-param price
run-query @mydb = "update wine_items set price='%s' where sku='%s'" : price, sku no-loop
@OKAY
end-handler
Copied!
For a hierarchical URL path, you would write the same:
begin-handler /items/wine-collection/red-wine/buy-item public
get-param sku
get-param price
run-query @mydb = "update wine_items set price='%s' where sku='%s'" : price, sku no-loop
end-handler
Copied!
Note that each parameter name must be unique; your program will error out if you have duplicate parameter names.
Maximum length of a request URL is 2500 bytes.
How Golf handles requests
An external request is handled by a first available process:
- For a command-line program, there is only a single process, and it handles a single requests before it exits.
- For a service application, there can be any number of processes running. A process is chosen to service a request if it is currently not serving other requests; this way there are no processes waiting idle unnecessarily. Each process is identical and can serve any request, i.e. it has all request handlers available to it. Thus, when a process is chosen to serve a request, then this process will simply execute its begin-handler.
- Processing a request
To handle a request, Golf dispatcher (which is automatically generated) is called first. It uses a request name to call the appropriate request handler, as explained above.
You can implement two hooks into request handling: one that executes before each request (before-handler) and one that executes afterwards (after-handler).
At the end of the request, all request memory and all file handles allocated by Golf will be freed, except for process-scoped memory (see memory-handling).
- Performance
Golf uses a hash table to match a request with a handler function, as well to match parameters. Typically, it takes only a single lookup to find the handler function/parameters, regardless of the number of possible request names/parameters a process may serve (be it 10 or 10,000 different names). Golf pre-generates a hash table at compile time, so no run-time cycles are spent on creating it. Also, the hash table is created as a continuous block of memory in the program's data segment, which loads as a part of the program (as a single memory copy) and is very fast because accessing the data needs no pointer translations. As a result, Golf dispatcher is extremely fast.
- Unrecognized requests
If no request has been recognized (i.e. request name does not match any request-handling ".golf" source file), then
Requests
request
See all
documentation
Resize hash
Purpose: Resize hash table.
resize-hash <hash> hash-size <new size>
Copied!
resize-hash will resize <hash> table (created by new-hash) to size <new size>, which refers to the number of "buckets", or possible hash codes derived from keys stored.
When a number of elements stored grows, the search performance may decline if hash size remains the same. Consequently, if the number of elements shrinks, the memory allocated by the hash may be wasted. Use get-hash to obtain its current hash-size, its length (the number of elements currently stored in it) and the statistics (such as average reads) to determine if you need to resize it.
Resizing is generally expensive, so it should not be done too often, and only when needed. The goal is to amortize this expense through future gain of lookup performance. For that reason it may be better to resize proportionally (i.e. by a percentage), unless you have a specific application reason to do otherwise, or to avoid exponential growth.
resize-hash h hash-size 100000
Copied!
Hash
get-hash
new-hash
purge-hash
read-hash
resize-hash
write-hash
See all
documentation
Return handler
Purpose: Return from current request handler back to its caller.
return-handler [ <return value> ]
Copied!
Returns from current request handler by transferring control back to its caller. If the current request handler is handling an external request (such as from a web browser, API, command line etc.), then return-handler is equivalent to exit-handler. If the current request handler was handling an internal request (i.e. called from another request handler with call-handler), then control transfers back to that handler immediately after call-handler.
For internal requests, the number <return value> will be passed back to the caller, who can obtain it via "return-value" clause in call-handler. If <return value> is omitted, or if no return-handler is used (and the request handler finished by reaching its end), then it is 0. If current request handler is handling an external request, then <return value> will also set the handler's exit status (see exit-status and exit-handler).
In this example, "req-handler" (the caller) will call "other-handler" (the callee), which will return to the caller (immediately after call-handler). Here's the caller:
begin-handler /req-handler public
...
call-handler "/other-handler" return-value rval
...
end-handler
Copied!
The callee handler:
begin-handler /other-handler public
...
return-handler 5
...
end-handler
The value of "rval" in the caller will be 5.
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Rewind fifo
Purpose: Rewind FIFO list to the beginning.
rewind-fifo <list>
Copied!
rewind-fifo will position at the very first data element put into <list> which was created with new-fifo. Each time read-fifo is used, the internal position moves to the next element in the order they were put in. rewind-fifo rewinds back to the very first one.
See read-fifo.
FIFO
delete-fifo
new-fifo
purge-fifo
read-fifo
rewind-fifo
write-fifo
See all
documentation
Rewind lifo
Purpose: Rewind LIFO list.
rewind-lifo <list>
Copied!
rewind-lifo will position at the very last data element put into <list> which was created with new-lifo. Each time read-lifo is used, the internal position moves to the previous element in the reverse order they were put in.
See read-lifo.
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
Rollback transaction
Purpose: Rollbacks a SQL transaction.
rollback-transaction [ @<database> ] \
[ on-error-continue | on-error-exit ] \
[ error <error> ] [ error-text <error text> ] \
[ options <options> ]
Copied!
rollback-transaction will roll back a transaction started with begin-transaction.
<options> (in "options" clause) is any additional options to send to database you wish to supply for this functionality.
Once you start a transaction with begin-transaction, you must either commit it with commit-transaction or rollback with rollback-transaction. If you do neither, your transaction will be rolled back once the request has completed and your program will stop with an error message. This is because opening a transaction and leaving without committing or a rollback is a bug in your program.
You must use begin-transaction, commit-transaction and rollback-transaction instead of calling this functionality through run-query.
<database> is specified in "@" clause and is the name of the database-config-file. If omitted, your program must use exactly one database (see --db option in gg).
The error code is available in <error> variable in "error" clause - this code is always "0" if successful. The <error> code may or may not be a number but is always returned as a string value. In case of error, error text is available in "error-text" clause in <error text> string.
"on-error-continue" clause specifies that request processing will continue in case of an error, whereas "on-error-exit" clause specifies that it will exit. This setting overrides database-level db-error for this specific statement only. If you use "on-error-continue", be sure to check the error code.
Note that if database connection was lost, and could not be reestablished, the request will error out (see error-handling).
begin-transaction @mydb
run-query @mydb="insert into employee (name, dateOfHire) values ('Terry', now())"
run-query @mydb="insert into payroll (name, salary) values ('Terry', 100000)"
rollback-transaction @mydb
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Run query
Purpose: Execute a query and loop through result set.
run-query \
[ @<database> ] \
= <query text> \
[ input <input parameter> [ , ... ] ] \
[ output ( <column name> [ noencode | urlencode | webencode ] ) [ , ... ] ] \
[ no-loop ] \
[ error <error> ] \
[ error-text <error text> ] \
[ affected-rows <affected rows> ] \
[ row-count <row count> ] \
[ on-error-continue | on-error-exit ]
<any code>
[ end-query ]
run-prepared-query \
... ( the same as run-query ) ...
Copied!
run-query executes a query specified with string <query text>.
<database> is specified in "@" clause and is the name of the database-config-file. If omitted, your program must use exactly one database (see --db option in gg).
- output clause
"output" clause is a comma-delimited list of the query's output columns. The column names do not need to match the actual query column names, rather you can name them anyway you want, as long as they positionally correspond. String variables with the same name are created for each column name and query's output assigned to them. For example:
run-query @db = "select firstName, lastName from employees" output first_name, last_name
@First name <<print-out first_name>>
@Last name <<print-out last_name>>
end-loop
Copied!
Note that the output is by default web-encoded. You can set the encoding of column output by using either "noencode" (for no encoding), "urlencode" (for URL-encoding) or "webencode" (for web-encoding) clause right after column name (see encode-web, encode-url for description of encodings). For example, here the first output column will not be encoded, and the second will be URL-encoded:
run-query @db = "select firstName, lastName from employees" output first_name noencode, last_name urlencode
@First name <<print-out first_name>>
@Last name <<print-out last_name>>
end-loop
Copied!
The query's input parameters (if any) are specified with '%s' in the <query text> (note that single quotes must be included). The actual input parameters are provided after "input" clause (you can instead use semicolon, i.e. ":"), in a comma-separated list. Each input variable is a string regardless of the actual column type, as the database engine will interpret the data according to its usage. Each input variable is trimmed (left and right) before used in a query.
"end-query" statement ends the loop in which query results are available through "output" clause. "no-loop" clause includes implicit "end-query", and in that case no "end-query" statement can be used. This is useful if you don't want to access any output columns (or there aren't any), but rather only affected rows (in INSERT or UPDATE for example), row count (in SELECT) or error code. "end-query" is also unnecessary for DDL statements like "CREATE INDEX" for instance.
"affected-rows" clause provides the number of <affected rows> (such as number of rows inserted by INSERT). The number of rows affected is typically used for DML operations such as INSERT, UPDATE or DELETE. For SELECT, it may or may not be the same as "row-count" which returns the number of rows from a query. See your database documentation for more.
The number of rows returned by a query can be obtained in <row count> in "row-count" clause.
The error code is available in <error> variable in "error" clause - this code is always "0" if successful. The <error> code may or may not be a number but is always returned as a string value. In case of error, error text is available in "error-text" clause in <error text> string.
"on-error-continue" clause specifies that request processing will continue in case of an error, whereas "on-error-exit" clause specifies that it will exit. This setting overrides database-level db-error for this specific statement only. If you use "on-error-continue", be sure to check the error code.
Note that if database connection was lost, and could not be reestablished, the request will error out (see error-handling).
"=" and "@" clauses may or may not have a space before the data that follows. So for example, these are both valid:
run-query @db ="select firstName, lastName from employee where employeeId='%s'" output firstName, lastName input empid
run-query @ db = "select firstName, lastName from employee where employeeId='%s'" output firstName, lastName input empid
Copied!
run-prepared-query is the same as run-query except that a <query> is prepared. That means it is pre-compiled and its execution plan is created once, instead of each time a query executes. The statement is cached going forward for the life of the process (with the rare exception of re-establishing a lost database connection). It means effectively an unlimited number of requests will be reusing the query statement, which generally implies higher performance. Note that databases do not allow prepared queries for DDL (Data Definition Language), as there is not much benefit in general, hence only DML queries (such as INSERT, DELETE etc.) and SELECT can be prepared.
In order for database to cache a query statement, Golf will save query text that actually executes the very first time it runs. Then, regardless of what query text you supply in the following executions, it will not mutate anymore. It means from that moment onward, the query will always execute that very same query text, just with different input parameters. In practicallity it means that <query> should be a string constant if you are using a prepared query (which is usually the case).
In some cases, you might not want to use prepared statements. Some reasons may be:
- your statements are often changing and dynamically constructed to the point where managing a great many equivalent prepared statements may be impractical - for example there may be a part of your query text that comes from outside your code,
- your dynamic statements do not execute as many times, which makes prepared statements slower, since they require two trips to the database server to begin with,
- your query cannot be written as a prepared statement due to database restrictions,
- in some cases prepared statements are slower because the execution plan depends on the actual data used, in which case non-prepared statement may be a better choice,
- in some cases the database support for prepared statements may still have issues compared to non-prepared,
- typically prepared statements do not use database query cache, so repeating identical queries with identical input data may be faster without them.
Note that in Postgres, with prepared statements you may get an error like "could not determine data type of parameter $N". This is an issue with Postgres server. In this case you can use "::<type>" qualifier, such as for instance to tell Postgres the input parameter is text:
select col1 from test where someId>='%s' and col1 like concat( '%s'::text ,'%')
Copied!
Note that SQL statements in SQLite are always prepared regardless of whether you use "run-query" or "run-prepared-query" due to how SQLite native interface works.
Select first and last name (output is firstName and lastName) based on employee ID (specified by input parameter empid):
get-param empid
run-query @db = "select firstName, lastName from employee where employeeId='%s'" output firstName, lastName input empid
@Employee is <<print-out firstName>> <<print-out lastName>>
end-query
Copied!
Prepared query without a loop and obtain error code and affected rows:
run-prepared-query @db = qry no-loop \
error ecode affected-rows arows input stock_name, stock_price, stock_price
Copied!
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Run remote
Purpose: Call a remote service in a single statement.
run-remote <service> \
( local <app name> ) | ( location <location> ) \
url-path <service URL> |
( \
app-path <app path> \
request-path <request path> \
[ url-params <url params> ] \
) \
[ request-body content <content> \
[ content-length <content length> ] \
[ content-type <content type> ] ] \
[ method <request method> ] \
[ environment <name>=<value> [ , ... ] ] \
[ timeout <timeout> ]\
[ status <status> ] \
[ started <started> ] \
[ finished-okay <finished okay> ]\
[ data <data> ] \
[ error <error> ] \
[ status <status> ] \
[ status-text <status text> ] \
[ exit-status <service status> ]
Copied!
run-remote is a combination of new-remote, call-remote and read-remote in one. Clauses for each of those can be specified in any order. Only a single <service> can be used. If a call to <service> succeeds, its results are read. Use either:
- <status> (in "status" clause) to check if there are results to be read: if it is GG_OKAY, then you can use the results.
- <finished okay> (in "finished-okay" clause) to check if service call executed: if it's 1, then it has.
See details for each clause in new-remote (for "local" through "timeout" clauses), call-remote (for "status" through "finished-okay" clauses) and read-remote (for "data" through "exit-status" clauses).
begin-handler /serv public
run-remote nf local "hash-server-yey" \
url-path "/hash-server-yey/server/op=add/key=sb_XYZ/data=sdb_123" \
finished-okay sfok \
data rdata error edata \
status st exit-status rstatus
if-true sfok not-equal 1 or st not-equal GG_OKAY
@Call did not succeed
else-if
@Result is <<print-out rdata> and (any) error is <<print-out edata>>
end-if
end-handler
Copied!
Distributed computing
call-remote
new-remote
read-remote
run-remote
See all
documentation
Scan string
Purpose: Scans string for another string or a character.
scan-string <string> [ start-with <start with> ] [ length <length> ] \
for <for string> \
status <status>
Copied!
scan-string will search <string> for <for string> (which can be a string or character such as 'A' for instance) specified in "for" clause.
If "start-with" clause is used, then the first byte to start the scan from is <start with>; with the very first byte being specified as 0.
If "length" clause is used, then only the <length> bytes are scanned, starting either from the beginning of <string> or from byte <start with> if "start-with" clause is specified.
<status> in "status" clause will be the byte position from the beginning of <string> where <for string> is found, or GG_ERR_POSITION if <for string> is not found.
Getting the byte position of a string:
set-string s = "wow this is a string!"
scan-string s start-with 3 length 13 for "this" status pos
if-true pos equal 4
@Found string where it should be!
end-if
Copied!
Getting the byte position of a character:
set-string s = "wow this is a string!"
scan-string s for 'g' status pos
if-true pos equal 19
@Found character where it should be!
end-if
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
SELinux
If you do not use SELinux, you can ignore this.
SELinux is MAC (Mandatory Access Control) system, which means anything that isn't allowed is prohibited. This is as opposed to DAC, Discretionary Access Control, where everything is allowed except what's prohibited. MAC generally works on top of DAC, and they are expected to work in a complementary fashion. Golf deploys both methods for enhanced security.
Golf comes with a SELinux policy out-of-the-box, which covers its general functioning. However, you can write any code with Golf, and if you are using SELinux, you may run afoul of its other policies, which may not be conducive to your code. In that case, use temporarily a permissive mode (via setenforce), and then audit2allow to get a clue on what is the issue and then take action to allow what's requested.
Note that OpenSUSE package does not come with SELinux policy as of this release, because OpenSUSE at this time does not come with a default base policy and SELinux installation.
Golf policy files (including .te files) can be found here:
ls $(gg -l)/selinux/
Copied!
As a part of installing Golf, the following SELinux types will be installed:
- ggfile_t: all files within Golf directory ($HOME/.golf) are labeled with this type.
- gg_t: domain type (process type) of all Golf executables that communicate with other processes (be it Unix or TCP sockets). Only files labeled ggfile_t can run as this process type.
- ggport_t: port type that any Golf process is allowed to bind to, accept and listen. No other process types are allowed to do so.
Golf policy:
- allows Golf processes unconfined access. This is expected as Golf is a general purpose framework. It means you do not have to do anything to connect to database, use files, connect to other servers etc.
- allows web servers (httpd_t domain type) to connect to sockets labeled with ggfile_t, but does not allow any other access. This allows communication between reverse-proxy web servers and Golf applications.
- allows web servers to connect to any Golf process that is listening on a TCP port (see gg), but does not allow any other access (i.e. to any other ports).
Golf policy allows normal functioning of Golf features only, but does not introduce any unnecessary privileges to the rest of the system.
Note: Golf installation does not distribute .pp (compile) policy files, because it is not currently part of distro repos. Due to changes in SELinux and difference in versions installed across derived distros, Golf will compile source .te files during the installation, ensuring the best possibility of successful SELinux policy setup.
Using Unix domain sockets for Golf processes to communicate with a web server (see gg) is the default method and no further action is needed.
Using TCP sockets for Golf processes to communicate with a web server (see gg) requires you to label such ports as ggport_t, for example if you plan to use port 2109:
sudo semanage port -a -t ggport_t -p tcp 2109
Copied!
When you no longer need a port, for example if you are switching to another port (for instance 2209), remove the old one and add the new one:
sudo semanage port -d -t ggport_t -p tcp 2109
sudo semanage port -a -t ggport_t -p tcp 2209
Copied!
Changing or adding directories
sudo semanage fcontext -a -t ggfile_t "/your/new/dir(/.*)?"
sudo restorecon -R /your/new/dir
Copied!
To remove context from such directories (if you are not using them anymore), use:
sudo semanage fcontext -d -t ggfile_t "/your/new/dir(/.*)?"
sudo restorecon -R /your/new/dir
Copied!
SELinux
SELinux
See all
documentation
SEMI
SEMI (SimplE Message Interface) is a binary format used to write (pack) and read (unpack) messages consisting of key/value pairs in the form of:
<key>=<8 bytes reserved><8 byte length of value><value>
Copied!
<key> can be comprised of any characters other than equal sign("=") or an exclamation point ("!"), and any surrounding whitespaces are trimmed.
Value is always preceded by a 8-byte length of value (as a binary number in big-endian 64bit format), followed by the value itself, followed by the new line ("\n") at the end which is not counted in length. A special <key> is "comment", which is always ignored, and serves the purpose of general commenting.
SEMI implicitly supports binary data without the need for any kind of encoding, and the number of bytes is specified ahead of a value, making parsing efficient.
Messages
get-message
new-message
read-message
SEMI
write-message
See all
documentation
Send file
Purpose: Send file to client.
send-file <file> [ headers \
[ content-type <content type> ] \
[ download [ <download> ] ] \
[ etag [ <etag> ] ] \
[ file-name <file name> ] \
[ ( cache-control <cache control> ) | no-cache ] \
[ status-id <status id> ] \
[ status-text <status text> ] \
[ custom <header name>=<header value> [ , ... ] ]
]
Copied!
When a client requests download of a file, you can use send-file to provide <file>, which is its location on the server, and is either a full path or relative to the application home directory (see directories). Note however that you can never use dot-dot (i.e. "..") in <file> - this is a security measure to avoid path-traversal attacks. Thus the file name should never have ".." in it, and if it does, the program will error out.
Headers
The following are subclauses that allow setting any custom header:
- <content type> is content type (such as "text/html" or "image/jpg" etc.) If you are sending a file to a client for download and you don't know its content type, you can use "application/octet-stream" for a generic binary file.
- If "download" is used without boolean variable <download>, or if <download> evaluates to true, then the file is sent to a client for downloading - otherwise the default is to display file in client.
- <file name> is the name of the file being sent to a client. This is not the local file name - it is the file name that client will use for its own purposes.
- <cache control> is the cache control HTTP header. "no-cache" instructs the client not to cache. Only one of "cache-control" and "no-cache" can be used. An example of <cache control>:
send-file "somepic.jpg" headers cache-control "max-age: 3600"
Copied!
- If "etag" is used without boolean variable <etag>, or if <etag> evaluates to true, then "ETAG" header will be generated (a timestamp) and included, otherwise it is not. The time stamp is of last modification date of the file (and typically used to cache a file on client if it hasn't changed on the server). "etag" is useful to let the client know to download the file only once if it hasn't changed, thus saving network and computing resources. ETAG header is used only for send-file.
- <status id> and <status text> are status settings for the response, as strings (such as "425" for "status-id" and "Too early" for "status-text").
- To set any type of generic HTTP header, use "custom" subclause, where <header name> and <header value> represent the name and value of a single header. Multiple headers are separated by a comma. There is no limit on the maximum number of such headers, other than of the underyling HTTP protocol. You must not use "custom" to set headers already set elsewhere (such as "etag" for instance), as that may cause unpredictable behavior. For instance this sets two custom headers:
out-header use custom "CustomOption3"="CustomValue3", "Status"="418 I'm a teapot"
Copied!
"custom" subclause lets you use any custom headers that exist today or may be added in the future, as well as any headers of your own design.
Any cookies set prior to send-file (see set-cookie and delete-cookie) will be sent along with the file to the web client.
To send a document back to the browser and show it (i.e. display):
send-file "/home/golf/files/myfile.jpg" headers content-type "image/jpg"
Copied!
An example to display a PDF document:
set-string pdf_doc="/home/mydir/myfile.pdf"
send-file pdf_doc headers content-type "application/pdf"
Copied!
If you want to send a file for download (with the dialog), use "download" clause. This way the document is not displayed but the "Save As" (or similar) window shows up, for example to download a "PDF" document:
send-file "/home/user/file.pdf" headers download content-type "application/pdf"
Copied!
Web
call-web
out-header
send-file
silent-header
See all
documentation
Server API
Golf can be used in extended-mode, where non-Golf code or libraries can be linked with your application.
Such code can be from a library (see --llflag and --cflag options in gg), or can be written directly as C code, i.e. files with .c and .h extension together with your Golf application. To do this, use call-extended statement.
Any function with C linkage can be used provided:
- its parameters are (by value or reference) only of type: "int64_t" (number type in Golf), "bool" (bool type in Golf) or "char *" (string type in Golf).
- it must not return any value (i.e. it must have a "void" return type).
When allocating strings in extended code, you must use Golf memory management functions. These functions are based on standard C library (such as malloc or free), but are not compatible with them because Golf manages such memory on top of the standard C library.
The functions you can use are:
- char *gg_strdup (char *s) which creates a copy of a null-terminated string "s". A pointer to memory data is returned.
- char *gg_strdupl (char *s, gg_num from, gg_num l) which creates a copy of memory data pointed to by "s", starting from byte "from" of length "l". Note that "from" is indexed from 0. A pointer to memory data is returned.
- void *gg_malloc(size_t size) which allocates memory of size "s" and returns a pointer to it.
- void *gg_calloc(size_t nmemb, size_t size) allocates "nmemb" blocks of memory (each of size "size") and returns a pointer to it. Memory is initialized to all zero bytes.
- num gg_mem_get_id (void *ptr) returns Golf memory handle for memory "ptr".
- void *gg_realloc(gg_num r, size_t size) reallocates memory identified with Golf memory handle "r" (see gg_mem_get_id()) to a new size of "size" and returns a pointer to it. Note that you can only reallocate the memory you created with gg_malloc() and gg_calloc() - do not attempt to reallocate Golf memory passed to your function. Golf in general never reallocates any existing memory in any statement.
- void gg_mem_set_len (gg_num r, gg_num len) sets the length of memory identified with Golf memory handle "r" to "len" bytes. Note that all Golf memory must have a null-byte at the end for consistency, regardless of whether such memory holds pure binary data or an actual null-delimited string. So for example, a string "abc" would have "len" set to 4 to include a null byte, and binary data "\xFF\x00\x01" (which consists of 3 bytes, the middle of which is a null byte) would have "len" also set to 4 and you would place an extra zero byte at the end of it even if it's not part of the actual useful data. Note that whatever memory length you set, it must be lesser or equal to the length of memory you have actually allocated.
- num gg_mem_get_len (gg_num r) returns the length of memory identified with Golf memory handle "r". The length returned is 1 bytes less than the memory set by gg_mem_set_len(), so for example for string "abc" the return value would be 3, as it would be for "\xFF\x00\x01".
You can use gg_malloc(), gg_calloc() and gg_realloc() to create new Golf-compatible memory - and assuming you have set the last byte of any such memory to a null byte, the resulting memory will be properly sized for Golf usage.
If you have memory that's already provided from elsewhere, you can use gg_strdup() or gg_strdupl() to create a copy of it that's compatible with Golf.
If Golf memory you created with these functions has extra unused bytes, you can use either gg_realloc() to reduce its footprint, or you can use gg_mem_set_len() to set its length.
Note that if you use C code included with a Golf project, you must include "golf.h" file in each of them. You do not need to manually include any other ".h" files (header files), as they will be automatically picked up.
Place the following files in a separate directory for demonstration purposes.
In this example, "example.golf" will use C functions from "example.c", and "example.h" will have declarations of those functions. File "example.c" implements a factorial function, as well as a function that will store the factorial result in an output message that's allocated and passed back to your Golf code:
#include "golf.h"
void get_factorial(gg_num f, gg_num *res)
{
*res = 1;
gg_num i;
for (i = 2; i <= f; i++) {
*res *= i;
}
}
#define MEMSIZE 200
void fact_msg (gg_num i, char **res)
{
char *r = gg_malloc (MEMSIZE);
gg_num f;
get_factorial (i, &f);
gg_num bw = snprintf(r, MEMSIZE, "Factorial value (message from C function) is %ld", f) + 1;
*res = gg_realloc (gg_mem_get_id(r), bw);
}
Copied!
File "example.h" declares the above functions:
void get_factorial(gg_num f, gg_num *res);
void fact_msg (gg_num i, char **res);
Copied!
File "example.golf" will call the above functions and display the results:
extended-mode
begin-handler /example public
set-number fact
call-extended get_factorial (10, &fact)
@Factorial is <<print-out fact>>
set-string res
call-extended fact_msg (10, &res)
print-out res
@
end-handler
Copied!
Create application "example":
sudo mgrg -i -u $(whoami) example
Copied!
Make the application:
gg -q
Copied!
Run it:
gg -r --req="/example" --exec --silent-header
Copied!
The output is, as expected:
Factorial is 3628800
Factorial value (message from C function) is 362880
Copied!
API
Client-API
Server-API
See all
documentation
Service
You can run a Golf application as a service by using mgrg program manager. Your application can then use commonly used web servers or load balancers (such as Apache, Nginx or HAProxy) so it becomes available on the web.
You can access your server application by means of:
- A web server (which is probably the most common way). You need to setup a reverse proxy, i.e. a web server that will forward requests and send replies back to clients; see below.
- The command line, in which case you can use gg (see -r option).
- Client-API, which allows any application in any programming language to access your server, as long as it has C linkage (by far most do). This method allows for MT (multithreaded) access to your application, where many client requests can be made in parallel.
Golf server runs as a number of (zero or more) background processes in parallel, processing requests simultaneously.
Setting up reverse proxy (web server)
If you use Apache, you need to connect it to your application, see connect-apache-tcp-socket (for using TCP sockets) and connect-apache-unix-socket (for using Unix sockets). If you use Nginx, you need to connect it to your application, see connect-nginx-tcp-socket (for using TCP sockets) and connect-nginx-unix-socket (for using Unix sockets). For HAProxy, see connect-haproxy-tcp-socket. Virtually all web servers/proxies support FastCGI protocol used by Golf; please see your server's documentation.
Starting Golf server processes
mgrg <app name>
Copied!
which in general will (based on the request load) start zero or more background resident process(es) (daemons) that process requests in parallel, or for instance:
mgrg -w 20 <app name>
Copied!
which will start 20 processes.
In a heavy-load environment, a client's connection may be rejected by the server. This may happen if the client runs very slowly due to swapping perhaps. Once a client establishes a connection, it has up to 5 seconds by default to send data; if it doesn't, the server will close the connection. Typically, clients send data right away, but due to a heavy load, this time may be longer. To set the connection timeout in seconds, use "--client-timeout" option in gg when making the application:
gg -q --client-timeout=8
Copied!
In this case, the timeout is set to 8 seconds.
Running application
application-setup
CGI
command-line
service
See all
documentation
Set app
Purpose: Set data used by the application.
set-app stack-depth <stack depth>
Copied!
Set maximum <stack depth> for calling handlers (see call-handler), including recursion. The default is 300 and cannot be lower than 100. The <stack depth> value must be a number constant.
Be careful when setting <stack depth> too high, as it may cause application and system stability issues that are unrelated to Golf.
Once set, this setting applies to the current process and all future requests it handles. Typically you'd set the stack depth in do-once statement, so it's set only once.
Application information
get-app
set-app
See all
documentation
Set bool
Purpose: Set value of a boolean variable.
set-bool <variable> [ = <boolean expression> | <comparison> ] [ process-scope ]
Copied!
If equal sign (=) is not used, the boolean variable <variable> is assign "false".
If <boolean expression> is specified (see boolean-expressions), then <variable> is assigned its computed value.
If <comparison> is specified (see "comparison" definition in if-true), then <variable> is assigned true if <comparison> evaluates to "true" and false if it evaluates to "false".
If "process-scope" clause is used, then boolean is of process scope, meaning its value will persist from one request to another for the life of the process; in the statement where <variable> is created, the assignment will take place only once. This clause can only be used if <variable> did not already exist.
Assign "true" value to boolean variable "my_bool":
set-bool my_bool = true
Copied!
Assign boolean value based on comparison:
...
set-bool my_bool = num1 equal num2 or str1 not-equal str2
Copied!
Booleans
boolean-expressions
set-bool
See all
documentation
Set cookie
Purpose: Set cookie.
set-cookie ( <cookie name>=<cookie value> \
[ expires <expiration> ] \
[ path <path> ] \
[ same-site "Lax"|"Strict"|"None" ] \
[ no-http-only [ <no-http-only> ] ] \
[ secure [ <secure> ] ] ) ,...
Copied!
To set a cookie named by string <cookie name> to string value <cookie value>, use set-cookie statement. A cookie must be set prior to outputting any actual response (such as with output-statement or print-out for example), or the program will error out and stop.
Cookie's <expiration> date (as a string, see get-time) is given with "expires" clause. The default is session cookie meaning the cookie expires when client session closes.
Cookie's <path> is specified with "path" clause. The default is the URL path of the request URL.
Whether a cookie applies to the same site is given with "same-site" clause along with possible values of "Lax", "Strict" or "None".
By default a cookie is not accessible to client scripting (i.e. "HttpOnly") -you can change this with "no-http-only" clause. That will be the case if "no-http-only" clause is used without bool expression <no-http-only>, or if <no-http-only> evaluates to true.
Use "secure" if a secure connection (https) is used, in order to specify this cookie is available only with a secure connection. That will be the case if "secure" is used without bool expression <secure>, or if <secure> evaluates to true.
Cookies are commonly used for session maintenance, tracking and other purposes. Use get-cookie and delete-cookie together with set-cookie to manage cookies.
You can set multiple cookies separated by a comma:
get-time to tm year 1
set-cookie "mycookie1"="4900" expires tm path "/", "mycookie2"="900" expires tm path "/my-app" same-site "Strict"
Copied!
To set a cookie named "my_cookie_name" to value "XYZ", that will go with the reply and expire in 1 year and 2 months from now, use:
get-time to mytime year 1 month 2
set-string my_cookie_value="XYZ"
set-cookie "my_cookie_name"=my_cookie_value expires mytime path "/" same-site "Lax"
Copied!
A cookie that can be used by JavaScript (meaning we use no-http-only clause):
set-cookie "my_cookie_name"=my_cookie_value no-http-only
Copied!
Cookies
delete-cookie
get-cookie
set-cookie
See all
documentation
Set number
Purpose: Set value of a number variable.
set-number <variable> [ = <number> ] [ process-scope ]
Copied!
Number variable <variable> is either assigned value <number> with "=" clause, or it is assigned 0 if equal clause ("=") is omitted. A number is a signed 64-bit integer betwen LLONG_MIN+1 and LLONG_MAX-1 inclusive (i.e. between -9,223,372,036,854,775,807 and 9,223,372,036,854,775,806)
If "process-scope" clause is used, then number is of process scope, meaning its value will persist from one request to another for the life of the proces; in the statement where <variable> is created, the assignment will take place only once. This clause can only be used if <variable> did not already exist.
Note that <number> can also be a string character produced by using "[" and "]" to specify the index within a string (with 0 being the first character), as in:
set-string my_str = "Some string"
set-number my_num = my_str[2]
Copied!
In the above example, "my_num" will be 109, which is the integer representation of character 'm'.
Initialize number "my_num" to 0 and the value of this variable, however it changes, will persist through any number of requests in the same process:
set-number my_num process-scope
Copied!
Initialize number "my_num" to 10:
set-number my_num = 10
Copied!
Subtract 5:
set-number my_num = my_num-5
Copied!
Assign an expression:
set-number my_num = (some_num*3+1)%5
Copied!
Numbers
abs-number
number-expressions
number-string
set-number
string-number
See all
documentation
Set param
Purpose: Set or create a parameter.
set-param ( <name> [ = <value> ] ) , ...
Copied!
set-param sets or creates parameter <name> (see get-param).
If parameter <name> does not exist, it's created with <value>. If it does exist, its value is replaced with <value>. Note that <value> can be of any type.
If equal sign ("=") and <value> are omitted, then <value> is the same as <name>, so:
set-param something
Copied!
is the same as:
set-param something = something
Copied!
where the first "something" is the parameter set/created, and the second "something" is an actual variable in your code. In this example, the two just happen to have the same name; this generally happens often, so this form is a shortcut for that.
You can specify any number of parameters separated by a comma, for instance in this case par1 is a boolean, par2 is a number and par3 is a string:
set-number par2 = 10
set-param par1=true, par, par3="hi"
Copied!
Set the value of parameter "quantity" to "10", which is also the output:
set-param quantity = "10"
...
get-param quantity
print-out quantity
Copied!
Request data
get-param
request-body
set-param
See all
documentation
Set string
Purpose: Set value of a string variable.
set-string <variable> [ unquoted ] [ = <string> ] [ process-scope ]
set-string <variable> [ <index> ] = <number>
set-string <variable> length <length>
Copied!
String variable <variable> will be assigned a value of <string> if clause "=" is present; otherwise <variable> is assigned an empty string. If "process-scope" clause is used, then <string> is assigned only the first time set-string executes.
With process-scope clause
If "length" clause is used, then the length of string <variable> is set to <length>. Just like with all other string statements, you can only set the new length of the string between zero and the current string length. This is useful mostly when manipulating string's individual bytes, and generally not in other cases (see new-string).
If "unquoted" clause is used, then <string> literal is unquoted, and everything from equal clause ("=") to the rest of the line is a <string>; in this case there is no need to escape double quotes or backslashes. Note that in this case, "unquoted" and any other clause must appear prior to equal clause ("=") and after variable, because they wouldn't otherwise be recognized. For instance:
set-string my_string unquoted = this is "some" string where escape characters like \n do "not work"
Copied!
This is the same as:
set-string my_string = "this is \"some\" string where escape characters like \n do \"not work\""
Copied!
"unquoted" clause is useful when writing string literals that would otherwise need lots of escaping. You can use double backslash at the end of the line to split the line with new line in between:
set-string unq1 unquoted =This is one line\
second line and\
third!
Copied!
The above will create a string:
This is one line
second line and
third!
Copied!
Concatenating string literals
set-string a="something is " \
" very good " \
" with spaces!! "
Copied!
You can also use set-string to set a byte in it; in this case <index> byte in <variable> string is set to <number>. <index> starts with 0 for the first byte. For instance, the resulting "str" will be "Aome string" since 65 is a number representation of 'A':
set-string str = "some string"
set-string str[0] = 65
set-string str[0] = 'A'
Copied!
Initialize "my_string" variable to "":
set-string my_string
Copied!
Initialize "my_string" variable to "abc":
set-string my_string = "abc"
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Silent header
Purpose: Do not output HTTP headers.
silent-header
Copied!
silent-header will suppress the output of HTTP headers, such as with out-header, or in any other case where headers are output. The effect applies to current request only; if you use it conditionally, then you can have it on or off dynamically.
If you want to suppress the headers for all service handlers (as if silent-header were implied at the beginning of each), then for a command-line program, use "--silent-header" option in "gg -r" when running it; to suppress the headers in services, use "-z" option in mgrg.
silent-header must be used prior to outputting headers, meaning either prior to any output (if out-header is not used) or prior to first out-header.
There are many uses for silent-header, among them:
- A command-line program (such as a command line program) may use it to produce generic output, without any headers,
- the output from a program may be redirected to a web file (such as html), in case of dynamic content that rarely changes,
- a web program may output a completely different (non-HTTP) set of headers, etc.
silent-header
Copied!
Web
call-web
out-header
send-file
silent-header
See all
documentation
Split string
Purpose: Split a string into pieces based on a delimiter.
split-string <string> with <delimiter> to <result> [ count <count> ]
split-string delete <result>
Copied!
split-string will find all instances of string <delimiter> in <string> and then split it into pieces delimited by string <delimiter>. The <result> can be used with read-split to obtain the pieces and with split-string to delete it (use "delete" clause with <result> to delete it).
If "count" clause is used, then the number of pieces is in <count>.
All pieces produced will be trimmed both on left and right. If a piece is double quoted, then double quotes are removed. For instance save this code in "ps.golf" in a separate directory:
%% /parse public
set-string clist = "a , b, \"c , d\" , e"
split-string clist with "," to res count tot
start-loop repeat tot use i
read-split i from res to item status st
if-true st not-equal GG_OKAY
break-loop
end-if
print-format " [%s]", item
end-loop
%%
Copied!
Create the application, build and run it:
sudo mgrg -i -u $(whoami) ps
gg -q
gg -r --req="/parse" --exec --silent-header
Copied!
The output would be:
[a] [b] [c , d] [e]
Copied!
split-string is useful for parsing CSV (Comma Separated Values) or any other kind of separated values, where separator can be any string of any length, for example if you're parsing an encoded URL-string, then "&" may be a separator, as in the example below.
The following will parse a string containing name/value pairs (such as "name=value") separated by string "&":
%% /parse-url public
set-string url ="x=23&y=good&z=hello_world"
split-string url with "&" to url_var count tot
start-loop repeat tot use i
read-split i from url_var to item
split-string item with "=" to item_var
read-split 1 from item_var to name
read-split 2 from item_var to val
print-format "Variable %s has value %s\n", name, val
end-loop
%%
Copied!
The result is:
Variable x has value 23
Variable y has value good
Variable z has value hello_world
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Sqlite database
SQLite database configuration file should contain a single line of text, and it must be the full path to the SQLite database file used, for example (if you keep it in Golf's application directory):
/home/myuser/.golf/apps/<app name>/app/<db name>.db
Copied!
Note that you can use tilde (~) as the first character of the path to signify user's home directory, so in the above example it could be "~/.golf/apps/<app name>/app/<db name>.db".
Database
begin-transaction
commit-transaction
current-row
database-config-file
db-error
mariadb-database
postgresql-database
rollback-transaction
run-query
sqlite-database
See all
documentation
Start loop
Purpose: Loop execution based on a condition.
start-loop [ repeat <repeat> ] \
[ use <loop counter> \
[ start-with <start with> ] [ add <add> ] ]
<any code>
end-loop
Copied!
start-loop will execute code between start-loop and "end-loop" clauses certain number of times based on a condition specified and the usage of continue-loop and break-loop, which can be used in-between the two.
<repeat> number (in "repeat" clause) specifies how many times to execute the loop (barring use of continue-loop and break-loop).
<loop counter> (in "use" clause) is a number that by default starts with value of 1, and is incremented by 1 each time execution loops back to start-loop, unless "start-with" and/or "add" clauses are used. The end value of <loop counter> (just outside "end-loop") is the first value past the last loop.
If <start with> (in "start-with" clause) is used, that's the initial value for <loop counter> (instead of the default 1), and if <add> is specified (in "add" clause), then <loop counter> is incremented by <add> each time execution loops back to start-loop (instead of the default 1). <add> can be positive or negative.
If either of "start-with" or "add" clauses is used, then "use" must be specified.
Print numbers 0 through 19:
start-loop repeat 20 use p start-with 0
print-out p
@
end-loop
Copied!
A loop that is controlled via continue-loop and break-loop statements, displaying numbers from 1 through 30 but omitting those divisible with 3:
set-number n
set-number max = 30
start-loop
set-number n add 1
if-true n every 3
continue-loop
end-if
if-true n greater-than max
break-loop
end-if
print-out n
end-loop
Copied!
Program flow
break-loop
call-handler
code-blocks
continue-loop
do-once
exit-handler
if-defined
if-true
quit-process
return-handler
start-loop
See all
documentation
Statements
Golf statements generally have three components separated by space(s):
- a name,
- an object,
- clauses.
A statement starts with a name, which designates its main purpose.
An object denotes what is referenced by a statement.
Each clause that follows consist of a clause name followed either with no arguments, or with one or more arguments. A clause may have subclauses immediately afterwards, which follow the same structure. Most clauses are separated by space(s), however some (like "=" or "@") may not need space(s) before any data; the statement's documentation would clearly specify this.
An object must immediately follow the statement's name, while clauses may be specified in any order.
For example, in the following Golf code:
encrypt-data orig_data input-length 6 password "mypass" salt newsalt to res binary
Copied!
encrypt-data is the statement's name, and "orig_data" is its object. The clauses are:
- input-length 6
- password "mypass"
- salt newsalt
- to res
- binary
The clauses can be in any order, so the above can be restated as:
encrypt-data orig_data to res password "mypass" salt newsalt binary input-length 6
Copied!
Golf documentation provides a concise BNF-like notation of how each statement works, which in case of encrypt-data is (backslash simply allows continuing to multiple lines):
encrypt-data <data> to <result> \
[ input-length <input length> ] \
[ binary [ <binary> ] ] \
( password <password> \
[ salt <salt> [ salt-length <salt length> ] ] \
[ iterations <iterations> ] \
[ cipher <cipher algorithm> ] \
[ digest <digest algorithm> ]
[ cache ]
[ clear-cache <clear cache> ) \
[ init-vector <init vector> ]
Copied!
Note the color scheme: clauses with input data are in blue, and with output data in green.
Optional clauses are enclosed with angle brackets (i.e between "[" and "]").
Arguments (in general variables and constants) are stated between "<" and ">".
If only one of a number of clauses may appear, such clauses are separated by "|".
A group of clauses that cannot be separated, or to remove ambiguity, are enclosed with "(" and ")".
Keywords (other than statement names such as encrypt-data above) are generally specific to each statement. So, keyword "salt", for example, has meaning only within encrypt-data and a few other related statements. In order to have the freedom to choose your variable names, you can simply surround them in parenthesis (i.e. "(" and ")") and use any names you want, even keywords, for example:
set-string password = "some password"
set-string salt = "0123456789012345"
encrypt-data "some data" password (password) salt (salt) to enc_data
print-out enc_data
Copied!
In this example, keywords "password" and "salt" are used as variable names as well.
Note that while you can use tab characters at the beginning of the line (such as for indentation), as well as in string literals, do not use tabs in Golf statements otherwise as they are not supported for lack of readability - use plain spaces.
Splitting statement into multiple lines, space trimming
encrypt-data orig_data input-length 6 \
password "my\
pass" salt \
newsalt to res binary
Copied!
Note that all statements are always left-trimmed for whitespace. Thus the resulting string literal in the above example is "mypass", and not "my pass", as the whitespaces prior to line starting with "pass" are trimmed first. Also, all statements are right-trimmed for white space, except if backslash is used at the end, in which case any spaces prior to backslash are conserved. For that reason, in the above example there is a space prior to a backslash where clauses need to be separated.
Note that begin-handler statement cannot be split with backsplash, i.e. it must always be on a single line for readability.
Comments
You can use both C style (i.e. /* ... */) and C++ style (i.e. //) comments with Golf statements, including within statements (with the exception of /*..*/ before statement name for readability), for example:
run-query @db = \
"select firstName, lastName from employee where yearOfHire>='%s'" \
output firstName, lastName : "2015"
Copied!
A statement that fails for reasons that are generally irrecoverable will error out, for example out of memory or disk space, bad input parameters etc.
Golf philosophy is to minimize the need to check for such conditions by preventing the program from continuing. This is preferable, as forgetting to check usually results in unforeseen bugs and safety issues, and the program should have stopped anyway.
Errors that are correctable programmatically are reported and you can check them, for example when opening a file that may or may not exist.
Overall, the goal is to stop execution when necessary and to offer the ability to handle an issue when warranted, in order to increase run-time safety and provide instant clues about conditions that must be corrected.
Language
inline-code
statements
syntax-highlighting
unused-var
variable-scope
See all
documentation
Stat file
Purpose: Get information about a file.
stat-file <file> \
[ size <size> ] [ type <type> ] \
[ path <path> ] [ name <name> ] \
[ mode <mode> ]
Copied!
stat-file obtains information about <file>, which is a string that is an absolute or relative path.
Clause "size" will store file's size in bytes to number <size>, or it will be GG_ERR_FAILED (if operation failed, likely because file does not exist or you have no permissions to access it).
Clause "type" will store file's type to number <type>, and it can be either GG_FILE (if it's a file) or GG_DIR (if it's a directory) or GG_ERR_FAILED (if operation failed, likely because file does not exist or you have no permissions to access it).
Clause "path" (in string <path>) obtains the fully resolved path of the <file> (including symbolic links), and "name" will provide its <name> (meaning a basename, without the path). If path cannot be resolved, then <path> is an empty string.
Clause "mode" will store file's permission mode to number <mode>, see permissions.
To get file size in variable "sz", which is created here:
stat-file "/home/user/file" size sz
Copied!
To determine if the object is a file or a directory:
stat-file "/home/user/some_name" type what
if-true what equal GG_FILE
@It's a file!
else-if what equal GG_DIR
@It's a directory!
else-if
@Doesn't exist!
end-if
Copied!
Get the fully resolved path of a file to string variable "fp" and the name of the file:
stat-file "../file" path fp name fn
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
String expressions
Purpose: Add strings using a plus ("+") sign.
<string> + <string> [ + ... ]
Copied!
String variables and literals can produce a new string by concatenation, using plus ("+") clause.
Concatenation in this manner can be used in any statement where a string is expected.
Note that you can concatenate binary strings too, i.e. strings that do not end with a null character, with each binary string used in its true length. The result will in general be a binary string.
You can reference string arrays and hash elements (see new-array and new-hash) by using subscription operator ([]), for instance:
new-array sarr type string
new-hash h
write-array sarr key 0 value "some string"
write-hash h key "one" value "uno"
set-string str = sarr[0] + " another string" + h["one"]
Copied!
Number to string shortcut
Substrings within expressions
For instance, here we'll concatenate two string constants and a variable "var":
set-string var = "day"
set-string newstr = "nice " + var + " it is!"
print-out newstr new-line
Copied!
The result will be "nice day it is!".
In the following case, directory (variable "dir") is concatenated with a forward slash ("/") and then file name (variable "file") to produce full path of a file to read:
read-file dir+"/"+file to content
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
String length
Purpose: Get string length.
string-length <string> to <length>
Copied!
string-length will place the number of bytes in <string> into number <length>.
Note that <string> does not need to be null-terminated, meaning it can be a binary or text string. <length> is the number of bytes comprising any such string.
Variable "len" will be 6:
set-string str = "string"
string-length str to len
Copied!
Variable "len2" will be 18 - the string has a null character in the middle of it:
set-string str2 = "string" "\x00 after null"
string-length str2 to len2
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
String number
Purpose: Convert string to number.
string-number <string> [ to <number> ] \
[ base <base> ] \
[ status <status> ]
Copied!
<string> is converted to <number> in "to" clause, using <base> in "base" clause, where <base> is by default either 10, or 16 (if number is prefixed with "0x" or "0X", excluding any leading minus or plus sign) or 8 (if number is prefixed with "0", excluding any leading minus or plus sign).
<base> can be between 2 and 36, inclusive. <number> can be positive or negative (i.e. signed) and can be up to 64-bit in length. If <base> is 0, it is the same as if it is not specified, i.e. default behavior applies.
<status> number (in "status" clause) is GG_OKAY if conversion was successful. If it wasn't successful, <number> is 0 and <status> is GG_ERR_OVERFLOW if <string> represents a number that requires over 64 bits of storage, GG_ERR_INVALID if <base> is incorrect, GG_ERR_EXIST if <string> is empty or no digits specified.
If there are trailing invalid characters (for instance "182xy" for base 10), <number> is the result of conversion up to the first invalid character and <status> is GG_ERR_TOO_MANY. In this example, <number> would be 182.
For convenience, you can use a shortcut for converting a string to a number, by prepending a "#" sign to the variable name, for example:
set-string s = "-10"
set-number n = #s + 10
Copied!
The above is the same as:
set-string s = "-10"
string-number s to val
set-number n = val + 10
Copied!
Effectively, # in front of a string variable is the same as string-number that converts it to a number with the base being the default (see above). If a string cannot be converted to a number, your program will error out. To check values with a status, use string-number.
You can use # for an expression, in which case the expression must be within parenthesis:
set-string s1 = "-10"
set-string s2 = "2"
set-number n = #(s1+s2) + 10
Copied!
In this case number "n" will have value of -92, because strings "s1" and "s2" concatenate to produce "-102", which is then converted to a number and finally 10 added to it, producing -92.
In this example, number "n" would be 49 and status "st" would be GG_OKAY:
string-number "49" to n base 10 status st
Copied!
Numbers
abs-number
number-expressions
number-string
set-number
string-number
See all
documentation
Syntax highlighting
For syntax highlighting of Golf programs in Vim, do this once:
gg -m
Copied!
The above will create a syntax file in your local Vim syntax directory:
$HOME/.vim/syntax/golf.vim
Copied!
and also update your local $HOME/.vimrc file to use this syntax for files with .golf extension. All files updated are local, i.e. they affect only the current user. Each user who wants this feature must issue the above command.
You can then change the color scheme to anything you like by using ":colorscheme" directly in editor, or by specifying "colorscheme" in your ".vimrc" file for a persistent change.
The Golf highlighting syntax is tested with Vim 8.1.
Language
inline-code
statements
syntax-highlighting
unused-var
variable-scope
See all
documentation
Temporary file
To create a temporary file, use uniq-file with a "temporary" clause. Temporary files are the same as any other files in the file-storage (and are organized in the same fashion), except that they are all under the subdirectory named "t":
$HOME/.golf/<app_name>/app/file/t
Copied!
A temporary file is not automatically deleted - you can remove it with delete-file statement when not needed (or use a periodic shell script to remove old temporary files). The reason for this is that the nature of temporary files varies, and they may not necessarily span a given time frame (such as a lifetime of a request, or a lifetime of a process that serves any number of such requests), and they may be used across number of requests for a specific purpose. Thus, it is your responsibility to remove a temporary file when it's appropriate for your application to do so.
The reason for storing temporary files in a separate directory is to gain a separation of temporary files (which likely at some point can be freely deleted) from other files.
See uniq-file for an example of creating a temporary file.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Text utf
Purpose: Convert text to UTF (UTF8 or UTF16) string.
text-utf <text> \
[ status <status> ] \
[ error-text <error text> ]
Copied!
text-utf will convert string value <text> to UTF. <text> itself will hold the resulting UTF string. If you don't wish <text> to be modified, make a copy of it first (see copy-string). See utf-text for the reverse conversion and data standards information.
You can obtain <status> in "status" clause. <status> number is GG_OKAY if successful, or GG_ERR_UTF if there was an error, in which case <error text> string in "error-text" clause will contain the error message.
set-string txt = "\u0459\\\"Doc\\\"\\n\\t\\b\\f\\r\\t\\u21d7\\u21d8\\t\\u25b7\\u25ee\\uD834\\uDD1E\\u13eb\\u2ca0\\u0448\\n\\/\\\"()\\t"
text-utf txt status txt_status error-text txt_error
set-string utf = "љ\"Doc\"\n\t\b\f\r\t⇗⇘\t▷◮𝄞ᏫⲠш\n/\"()\t"
if-true utf not-equal txt or txt_status not-equal GG_OKAY or txt_error not-equal ""
@Error in converting string to UTF
end-if
Copied!
UTF
text-utf
utf-text
See all
documentation
Trim string
Purpose: Trim a string.
trim-string <string>
Copied!
trim-string trims <string>, both on left and right.
The variable "str" will be "some string" after trim-string:
set-string str = " some string ";
trim-string str
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Uninstall
Uninstall Golf if installed from source
make uninstall
Copied!
Note that $HOME/.golf/<app name> directory will not be removed for any application, since it may contain application files; you may delete it if there's no data there you care about, or you backed it up.
Install golf
install-golf
install-package
uninstall
See all
documentation
Uniq file
Purpose: Create a new empty file with a unique name.
uniq-file <file name> [ temporary ]
Copied!
One of the common tasks in many applications is creating a unique file (of any kind, including temporary). uniq-file statement does that - it creates a new unique file of zero size, with <file name> being its fully qualified name, which is always within the file-storage.
The file itself is created empty. If "temporary" clause is used, then the file created is a temporary-file.
The file has no extension. You can rename it after it has been created to reflect its usage or purpose.
All files created are setup with owner and group read/write only permissions.
The following creates an empty file with auto-generated name that will be stored in "mydoc" variable. String variable "mydoc" is defined in the statement. The string "some data" is written to a newly created file:
uniq-file mydoc
write-file mydoc from "some data"
Copied!
To create a temporary file:
uniq-file temp_file temporary
...
..
delete-file temp_file
Copied!
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Unlock file
Purpose: Unlocks file.
unlock-file id <lock id>
Copied!
unlock-file will unlock file that was locked with lock-file. <lock id> is the value obtained in lock-file's "id" clause.
See lock-file.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Unused var
Purpose: Prevent compiler error if variable is not used.
unused-var <variable name> [ , ... ]
Copied!
unused-var prevents erroring out if <variable name> is unused; a list of variable names can be specified separated by a comma. Generally, you don't want to have unused variables - they typically indicate bugs or clutter. However, in some cases you might need such variables as a reminder for a future enhancement, or for some other reason it is unavoidable. In any case, you can use unused-var to shield such instances from causing errors.
In the following, variable "hw" is created and initialized. Such variable is not used at the moment, however if you would do so in the future and want to keep it, use unused-var to prevent compiler errors:
set-string hw = "Hello world"
unused-var hw
Copied!
Language
inline-code
statements
syntax-highlighting
unused-var
variable-scope
See all
documentation
Upper string
Purpose: Upper-case a string.
upper-string <string>
Copied!
upper-string converts all <string>'s characters to upper case.
The resulting "str" is "GOOD":
set-string str="good"
upper-string str
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Use cursor
Purpose: Iterate to a lesser or greater key in a tree.
use-cursor <cursor> ( current | get-lesser | get-greater ) \
[ key <key> ] \
[ value <value> ] \
[ update-value <update value> ] \
[ status <status> ]
Copied!
use-cursor uses <cursor> previously created (see read-tree, write-tree) for iteration over tree nodes with lesser or greater key values. It can also obtain keys and values for such nodes, as well as update their values.
A <cursor> has a current node, which is first computed by using "current", "get-lesser" or "get-greater" clauses, and then any other clauses are applied to it (such as "key", "value" and "update-value").
The computation of a current node is performed by using a <cursor>'s "previous current node", i.e. the current node just before use-cursor executes. If "current" clause is used, the current node remains the same as previous current node. If "get-lesser" clause is used, a node with a key that is the next lesser from the previous current will become the new current. If "get-greater" clause is used, a node with a key that is the next greater from the previous current will become the new current.
If the new current node can be found, then other use-cursor clauses are applied to it, such as to obtain a <key> or <value>, or to <update value>. If, as a result of either of these clauses, the new current node cannot be found (for instance there is no lesser or greater key in the tree), the current node will be unchanged and <status> (in "status" clause) will be GG_ERR_EXIST.
Key, value, updating value, status
"status" clause can be used to obtain <status> number, which is GG_ERR_EXIST if the new current node cannot be found, in which case the current node, <key> and <value> are unchanged. Otherwise, <status> is GG_OKAY.
The following will find a value with key "999", and then iterate in the tree to find all lesser values (in descending order):
set-string k = "999"
read-tree mytree equal k status st \
value val new-cursor cur
start-loop
if-true st equal GG_OKAY
@Value found is [<<print-out val>>] for key [<<print-out k>>]
use-cursor cur get-lesser status st value val key k
else-if
break-loop
end-if
end-loop
Copied!
For more examples, see new-tree.
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Utf text
Purpose: Convert UTF (UTF8 or UTF16) string to text.
utf-text <utf> \
[ to <text> ] \
[ length <length> ] \
[ status <status> ] \
[ error-text <error text> ]
Copied!
utf-text will convert <utf> text to <text> (specified with "to" clause). If <text> is omitted, then the result of conversion is output.
<utf> is a string that may contain UTF characters (as 2, 3 or 4 bytes representing a unicode character). Encoding creates a string that can be used as a value where text representation of UTF is required. utf-text is performed according to RFC7159 and RFC3629 (UTF standard).
Note that hexadecimal characters used for Unicode (such as \u21d7) are always lowercase. Solidus character ("/") is not escaped, although text-utf will correctly process it if the input has it escaped.
The number of bytes in <utf> to be converted can be specified with <length> in "length" clause. If <length> is not specified, it is the length of string <utf>. Note that a single UTF character can be anywhere between 1 to 4 bytes. For example "љ" is 2 bytes in length.
The status of encoding can be obtained in number <status>. <status> is the string length of the result in <text> (or the number of bytes output if <text> is omitted), or -1 if error occurred (meaning <utf> is an invalid UTF) in which case <text> (if specified) is an empty string and the error text can be obtained in <error text> in "error-text" clause.
Convert UTF string to text and verify the expected result:
set-string utf_str = "\"Doc\"\n\t\b\f\r\t⇗⇘\t▷◮𝄞ᏫⲠш\n/\"()\t"
utf-text utf_str status encstatus to text_text
(( expected_result
@\"Doc\"\n\t\b\f\r\t\u21d7\u21d8\t\u25b7\u25ee\ud834\udd1e\u13eb\u2ca0\u0448\n/\"()\t
))
if-true text_text equal expected_result and encstatus not-equal -1
@decode-text worked okay
end-if
Copied!
UTF
text-utf
utf-text
See all
documentation
Variable scope
Golf uses scope rules for variables that is similar to other programming languages.
Language
inline-code
statements
syntax-highlighting
unused-var
variable-scope
See all
documentation
Web framework for C programming language
Golf as a web framework for C programming language
Golf offers simple statements to perform complex common tasks, as well as memory safety. The C code that you'd include via call-extended statement may or may not be memory safe; thus once your application is in extended mode (see extended-mode), your application may no longer be memory safe.
To make sure a Golf application is memory safe, simply search for extended-mode statement from the root source directory:
find . -name "*.golf" -print -exec grep -l '^\s*extended\-mode' {} \;
Copied!
If no matches are found, the application is memory safe.
However, for applications that are written in C (for performance, access to hardware or OS features, or for any other reason), Golf offers a framework that can offload many tasks from your project, while you write C code where it's needed or necessary.
The benefit is that the part of your application written in Golf (which may be a vast majority of it) offers memory safety, ease of development and maintenance, server facilities and lots of functionality. Your Golf code would call your C code when needed, thus accomplishing the functionality and goals you set out to do.
Just as a note of technicality, when used in extended mode, Golf is considered a framework and not a library, because Golf code will call your C code (and not the other way around).
C language
call-extended
extended-mode
web-framework-for-C-programming-language
See all
documentation
Write array
Purpose: Store value into an array.
write-array <array> \
key <key> \
value <value> \
[ old-value <old value> ]
Copied!
write-array will store a <value> (in "value" clause) under index <key> (in "key" clause) into <array>, which must be created with new-array. <key> is a number from 0 up to (excluding) the currently allocated array size (see new-array). The type of <value> is determined when <array> is created (see "type" clause), and can be either a string, number or a boolean.
<key> and <value> are collectively called an "element".
The old value associated under index <key> is returned in <old value> (in "old-value" clause) and <value> will replace the old value.
If an <array> was created with "process-scope" clause (see new-array), then the element <value> will not be freed when the current request ends, rather it will persist while the process runs, unless deleted (see read-array with delete clause).
Writing data to an array:
new-array arr
write-array arr key 100 value "some data"
Copied!
Writing new value with the same key index and obtaining the previous value (which is "some data"):
write-array arr key 100 value "new data" old-value od
@Previous value for this key index is <<print-out od>>
Copied!
The following is an array service, where a process-scoped array is created. It provides inserting, deleting and querying indexed keys. Maximum number of keys it holds is 10,000,000 (indexed from 0 to 9,999,999). Such a service process can run indefinitely. Create file arrsrv.golf:
%% /arrsrv public
do-once
new-array arr max-size 10000000 process-scope type string
end-do-once
get-param op
get-param key
get-param data
string-number key to key_n
if-true op equal "add"
write-array arr key key_n value data old-value old_data
delete-string old_data
@Added [<<print-out key>>]
else-if op equal "delete"
read-array arr key key_n value val delete
@Deleted [<<print-out val>>]
delete-string val
else-if op equal "query"
read-array arr key key_n value val
@Value [<<print-out val>>]
end-if
%%
Copied!
Create and make the application, then run it as service:
// Create application
gg -k arr
// Make application
gg -q
// Start application (single process key service)
mgrg -w 1 arr
Copied!
Try it from a command line client (see gg):
// Add data
gg -r --req="/arrsrv/op=add/key=15/data=15" --service --app="/arr" --exec
// Query data
gg -r --req="/arrsrv/op=query/key=15" --service --app="/arr" --exec
// Delete data
gg -r --req="/arrsrv/op=delete/key=15" --service --app="/arr" --exec
Copied!
See read-array for more examples.
Array
new-array
purge-array
read-array
write-array
See all
documentation
Write fifo
Purpose: Write key/value pair into a FIFO list.
write-fifo <list> \
key <key> \
value <value>
Copied!
write-fifo adds a pair of key/value pointers to the FIFO <list>, specified with strings <key> and <value> (in "key" and "value" clauses, collectively called an "element").
It always adds elements to the end of the list.
new-fifo nf
write-fifo nf key "mykey" value "myvalue"
Copied!
FIFO
delete-fifo
new-fifo
purge-fifo
read-fifo
rewind-fifo
write-fifo
See all
documentation
Write file
Purpose: Write to a file.
write-file <file> | ( file-id <file id> ) \
from <content> \
[ length <length> ] \
[ ( position <position> ) | ( append [ <append> ] ) ] \
[ status <status> ]
Copied!
This is a simple method of writing a file. File named <file> is opened, data written, and file is closed. <file> can be a full path name, or a path relative to the application home directory (see directories).
write-file writes <content> to <file>. If "append" clause is used without boolean variable <append>, or if <append> evaluates to true, the <content> is appended to the file; otherwise the file is overwritten with <content>, unless "position" clause is used in which case file is not overwritten and <content> is written at byte <position> (with 0 being the first byte). Note that <position> can be beyond the end of file, in which case null-bytes are written between the current end of file and <position>.
File is created if it does not exist (even if "append" is used), unless "position" clause is used in which case file must exist.
If "length" is not used, then a whole string <content> is written to a file, and the number of bytes written is the length of that string. If "length" is specified, then exactly <length> bytes are written.
If "status" clause is used, then the number of bytes written is stored to <status>, unless error occurred, in which case <status> has the error code. The error code can be GG_ERR_POSITION (if <position> is negative or file does not support it), GG_ERR_WRITE (if there is an error writing file) or GG_ERR_OPEN if file cannot be open.
This method uses a <file id> that was created with open-file. You can then write (and read) file using this <file id> and the file stays open until close-file is called or the request ends.
If "position" clause is used, then data is written starting from byte <position>, otherwise writing starts from the current file position determined by the previous reads/writes or as set by using "set" clause in file-position. After each read or write, the file position is advanced by the number of bytes read or written. Position can be set passed the last byte of the file, in which case writing will fill the space between the current end of file and the current position with null-bytes.
If "length" is not used, then a whole string is written to a file, and the number of bytes written is the length of that string. If "length" is specified, then exactly <length> bytes are written.
If "append" clause is used without boolean variable <append>, or if <append> evaluates to true, then file pointer is set at the end of file and data written.
If "status" clause is used, then the number of bytes written is stored to <status>, unless error occurred, in which case <status> has the error code. The error code can be GG_ERR_POSITION (if <position> is negative or file does not support it), GG_ERR_WRITE (if there is an error writing file) or GG_ERR_OPEN if file is not open.
To overwrite file "/path/to/file" with "Hello World":
write-file "/path/to/file" from "Hello World"
Copied!
To append "Hello World" to file:
set-string path="/path/to/file"
set-string cont="Hello World"
write-file path from cont append
Copied!
To write only 5 bytes (i.e. "Hello") and get status (if successful, number "st" would be "5"):
set-string cont="Hello World"
write-file "file" from cont length 5 status st
Copied!
To write a string "Hello" at byte position 3 in the existing "file":
set-string cont="Hello"
write-file "file" from cont position 3 status st
Copied!
See open-file for an example with "file-id" clause.
Files
change-mode
close-file
copy-file
delete-file
file-position
file-storage
file-uploading
get-upload
lock-file
open-file
read-file
read-line
rename-file
stat-file
temporary-file
uniq-file
unlock-file
write-file
See all
documentation
Write hash
Purpose: Store key/value pair into a hash.
write-hash <hash> \
key <key> \
value <value> \
[ status <status> ] \
[ old-value <old value> ]
Copied!
write-hash will store string <key> (in "key" clause) and <value> (in "value" clause) into <hash>, which must be created with new-hash.
<key> and <value> are collectively called an "element".
If <key> already exists in the hash, then the old value associated with it is returned in string <old value> (in "old-value" clause) and <value> will replace the old value - in this case <status> number (in "status" clause) has a value of GG_INFO_EXIST.
If <key> did not exist, <status> will be GG_OKAY and <old value> is unchanged.
If a <hash> was created with "process-scope" clause (see new-hash), then the element (including <key> and <value>) will not be freed when the current request ends, rather it will persist while the process runs, unless deleted (see read-hash with delete clause).
Writing data to a hash:
new-hash h
write-hash h key "mykey" value "some data"
Copied!
Writing new value with the same key and obtaining the previous value (which is "some data"):
write-hash h key "mykey" value "new data" status st old-value od
if-true st equal GG_INFO_EXIST
@Previous value for this key is <<print-out od>>
end-if
Copied!
The following is a key/value service, where a process-scoped hash is created. It provides inserting, deleting and querying key/value pairs. Such a service process can run indefinitely. Create file keysrv.golf:
%% /keysrv public
do-once
new-hash h hash-size 1024 process-scope
end-do-once
get-param op
get-param key
get-param data
if-true op equal "add"
write-hash h key key value data old-value old_data status st
if-true st equal GG_INFO_EXIST
delete-string old_data
end-if
@Added [<<print-out key>>]
else-if op equal "delete"
read-hash h key (key) value val delete status st
if-true st equal GG_ERR_EXIST
@Not found [<<print-out key>>]
else-if
@Deleted [<<print-out val>>]
delete-string val
end-if
else-if op equal "query"
read-hash h key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found, queried [<<print-out key>>]
else-if
@Value [<<print-out val>>]
end-if
end-if
%%
Copied!
Create and make the application, then run it as service:
// Create application
gg -k hash
// Make application
gg -q
// Start application (single process key service)
mgrg -w 1 hash
Copied!
Try it from a command line client (see gg):
// Add data
gg -r --req="/keysrv/op=add/key=15/data=15" --service --app="/hash" --exec
// Query data
gg -r --req="/keysrv/op=query/key=15" --service --app="/hash" --exec
// Delete data
gg -r --req="/keysrv/op=delete/key=15" --service --app="/hash" --exec
Copied!
See read-hash for more examples.
Hash
get-hash
new-hash
purge-hash
read-hash
resize-hash
write-hash
See all
documentation
Write lifo
Purpose: Write key/value pair into a LIFO list.
write-lifo <list> \
key <key> \
value <value>
Copied!
write-lifo adds a pair of key/value to the LIFO <list>, specified with strings <key> and <value> (in "key" and "value" clauses, collectively called an "element").
It always adds an element so that the last one written to <list> would be the first to be read with read-lifo.
new-lifo nf
write-lifo nf key "mykey" value "myvalue"
Copied!
LIFO
delete-lifo
get-lifo
new-lifo
purge-lifo
read-lifo
rewind-lifo
write-lifo
See all
documentation
Write list
Purpose: Write key/value pair into a linked list.
write-list <list> key <key> \
value <value> \
[ append [ <append> ] ]
Copied!
write-list adds a pair of key/value strings to the linked <list>, specified with <key> and <value> (in "key" and "value" clauses, collectively called an "element").
The key/value pair is added just prior to the list's current position, thus becoming a current element.
If "append" clause is used without boolean variable <append>, or if <append> evaluates to true, then the element is added at the end of the list, and the list's current element becomes the newly added one.
Add a key/value pair to the end of the list:
new-list mylist
write-list mylist key "mykey" value "myvalue" append
Copied!
The following is a list that is process-scoped, i.e. it is a linked-list server, which can add, delete, read and position to various elements:
%% /llsrv public
do-once
new-list t process-scope
end-do-once
get-param op
get-param key
get-param data
if-true op equal "add"
write-list t key (key) value data append
@Added [<<print-out key>>] value [<<print-out data>>]
else-if op equal "delete"
position-list t first
read-list t key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found
else-if
@Deleted key [<<print-out key>>], [<<print-out val>>]
delete-list t
end-if
else-if op equal "next"
position-list t next status st
if-true st equal GG_OKAY
@Okay
else-if
@Not found
end-if
else-if op equal "last"
position-list t last status st
if-true st equal GG_OKAY
@Okay
else-if
@Not found
end-if
else-if op equal "previous"
position-list t previous status st
if-true st equal GG_OKAY
@Okay
else-if
@Not found
end-if
else-if op equal "first"
position-list t first status st
if-true st equal GG_OKAY
@Okay
else-if
@Not found
end-if
else-if op equal "query"
read-list t key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found
else-if
@Key [<<print-out key>>], value [<<print-out val>>]
end-if
else-if op equal "purge"
purge-list t
end-if
%%
Copied!
Create application:
sudo mgrg -i -u $(whoami) linkserver
Copied!
Start the server:
mgrg -w 1 linkserver
Copied!
Try it out:
gg -r --req="/llsrv/op=add/key=1/data=1" --exec --service
gg -r --req="/llsrv/op=add/key=2/data=2" --exec --service
gg -r --req="/llsrv/op=query" --exec --service
gg -r --req="/llsrv/op=previous" --exec --service
gg -r --req="/llsrv/op=query" --exec --service
Copied!
Linked list
delete-list
get-list
new-list
position-list
purge-list
read-list
write-list
See all
documentation
Write message
Purpose: Write key/value to a message.
write-message <message> key <key> value <value>
Copied!
write-message will append to <message> a key/value pair, in the form of string <key> (in "key" clause) and string <value> (in "value" clause).
<message> must have been created with new-message. In order to use write-message, a message must not have been read from (see read-message).
new-message msg
write-message msg key "key1" value "value1"
Copied!
Messages
get-message
new-message
read-message
SEMI
write-message
See all
documentation
Write string
Purpose: Create complex strings.
write-string <string>
<any code>
end-write-string [ notrim ]
Copied!
Output of any Golf code can be written into <string> with write-string. In between write-string and end-write-string you can write <any Golf code>. For instance you can use database queries, comparison statements etc., just as you would for any other Golf code.
Note that instead of write-string you can also use a shortcut "((" (and instead of end-write-string you can use "))" ), for example here a string "fname" holds a full path of a file named "config-install.golf" under the application home directory (see directories):
get-app directory to home_dir
(( fname
@<<print-out home_dir>>/config-install.golf
))
Copied!
Just like with all other Golf code, the text of every statement is trimmed both on left and write, so this:
(( mystr
@Some string
))
Copied!
is the same as:
(( mystr
@Some string <whitespaces>
))
Copied!
write-string (or "((") statement must always be on a line by itself (and so does end-write-string, or "))" statement). The string being built starts with the line following write-string, and ends with the line immediately prior to end-write-string.
All trailing whitespaces (including new lines) are removed, for example:
(( mystr
@My string
@
@
))
Copied!
the above string would have two trailing empty lines, however they will be removed. If you want to skip trimming the trailing whitespaces, use "notrim" clause in end-write-string.
- Simple
A simple example:
set-string my_str="world"
set-string my_str1="and have a nice day too!"
write-string result_str
@Hello <<print-out my_str>> (<<print-out my_str1>>)
end-write-string
print-out result_str
Copied!
The output is
Hello world (and have a nice day too!)
Copied!
- Using code inside
Here is using Golf code inside write-string, including database query and comparison statements to produce different strings at run-time:
get-param selector
set-string my_str="world"
write-string result_str
if-true selector equal "simple"
@Hello <<print-out my_string>> (and have a nice day too!)
else-if selector equal "database"
run-query @db="select name from employee" output name
@Hello <<print-out name>>
@<br/>
end-query
else-if
@No message
end-if
end-write-string
print-out result_str
Copied!
If selector variable is "simple", as in URL
https://mysite.com/<app name>/some-service?selector=simple
Copied!
the result is
Hello world (and have a nice day too!)
Copied!
If selector variable is "database", as in URL
https://mysite.com/<app name>/some-service?selector=database
Copied!
the result may be (assuming "Linda" and "John" are the two employees selected):
Hello Linda
<br/>
Hello John
<br/>
Copied!
If selector variable is anything else, as in URL
https://mysite.com/<app name>/some-service?selector=something_else
Copied!
the result is
No message
Copied!
- Using call-handlers calls inside
The following uses a call-handler inside write-string:
set-string result_str=""
write-string result_str
@<<print-out "Result from other-service">> is <<call-handler "/other-service">>
end-write-string
print-out result_str
Copied!
The "other-service" may be:
begin-handler /other-service public
@"Hello from other service"
end-handler
Copied!
The output:
Result from other-service is Hello from other service
Copied!
- Nesting
An example to nest write-strings:
write-string str1
@Hi!
write-string str2
@Hi Again!
end-write-string
print-out str2
end-write-string
print-out str1
Copied!
The result is
Hi!
Hi Again!
Copied!
Strings
copy-string
count-substring
delete-string
lower-string
match-regex
new-string
read-split
replace-string
scan-string
set-string
split-string
string-expressions
string-length
trim-string
upper-string
write-string
See all
documentation
Write tree
Purpose: Insert a key/value pair into a tree.
write-tree <tree> key <key> value <value> \
[ status <status> ] \
[ new-cursor <cursor> ]
Copied!
write-tree inserts string <key> and associated string <value> into <tree> created by new-tree.
If <key> already exists in <tree>, <status> (in "status" clause) will be GG_ERR_EXIST and nothing is inserted into <tree>, otherwise it is GG_OKAY.
If "new-cursor" clause is used, then a <cursor> will be positioned on a newly inserted tree node. You can use use-cursor to iterate to nodes with lesser and greater key values.
Insert key "k" with value "d" into "mytree", and obtain status in "st":
write-tree mytree key k value d status st
Copied!
The following is an example of a process-scoped tree. Such a tree keeps its data across the requests, for as long as the process is alive.
In a new directory, create file treesrv.golf and copy to it:
%% /treesrv public
do-once
new-tree t process-scope
end-do-once
get-param op
get-param key
get-param data
if-true op equal "add"
write-tree t key (key) value data status st
if-true st equal GG_OKAY
@Added [<<print-out key>>]
else-if
@Key exists
end-if
else-if op equal "delete"
delete-tree t key (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found [<<print-out key>>]
else-if
@Deleted [<<print-out val>>]
delete-string val
end-if
else-if op equal "query"
read-tree t equal (key) value val status st
if-true st equal GG_ERR_EXIST
@Not found, queried [<<print-out key>>]
else-if
@Value [<<print-out val>>]
end-if
end-if
%%
Copied!
Create new application ("pt" for "process tree"):
sudo mgrg -i -u $(whoami) pt
Copied!
Build application:
gg -q
Copied!
Run the tree service:
mgrg -w 1 pt
Copied!
Try it out, add key/value pairs, query, delete, query again:
# Add key=1 and data=d1
$ gg -r --req="/treesrv/op=add/key=1/data=d1" --service --exec --silent-header
Added [1]
# Add key=2 and data=d2
$ gg -r --req="/treesrv/op=add/key=2/data=d2" --service --exec --silent-header
Added [2]
# Query key=1
$ gg -r --req="/treesrv/op=query/key=1" --service --exec --silent-header
Value [d1]
# Query key=2
i$ gg -r --req="/treesrv/op=query/key=2" --service --exec --silent-header
Value [d2]
# Delete key=2
$ gg -r --req="/treesrv/op=delete/key=2" --service --exec --silent-header
Deleted [d2]
# Query key=2
$ gg -r --req="/treesrv/op=query/key=2" --service --exec --silent-header
Not found, queried [2]
Copied!
See read-tree for more examples.
Tree
delete-tree
get-tree
new-tree
purge-tree
read-tree
use-cursor
write-tree
See all
documentation
Xml doc
Purpose: Parse XML text.
xml-doc <text> to <xml> \
[ status <status> ] [ length <length> ] \
[ error-text <error text> ] \
[ error-line <line> ] \
[ error-char <char> ]
xml-doc delete <xml>
Copied!
xml-doc will parse XML <text> into <xml> variable, which can be used with read-xml to get the data.
The length of <text> may be specified with "length" clause in <length> variable, or if not, it will be the string length of <text>.
The "status" clause specifies the return <status> number, which is GG_OKAY if successful or GG_ERR_XML if there is an error in parsing, in which case <error text> in "error-text" clause is the error message. You can also obtain the error's line number (with number <line> in clause "error-line") and the character position within that line (with number <char> in clause "error-char").
The maximum depth of nested elements in XML document is 32, and the maximum length of a normalized element name is 500 (see read-xml for more on normalized names).
An XML element that is comprised of multiple anonymous sub-elements is presented as a concatenated single element; this is likely how most applications expect to see such data. All data is trimmed for whitespace on left and right.
Golf uses libxml2 library for XML parsing.
To delete an XML variable, use "delete" clause with the <xml>. This will delete all memory associated with it, and the variable <xml> itself.
Parse the following XML document and display all element names and values from it. You can use them as they come along, or store them into new-hash or new-tree for instance for searching of large documents. This also demonstrates usage of UTF characters:
%% /xml public
set-string xmld unquoted =<?xml version="1.0" encoding="UTF-8"?>\
<countries>\
<country id='1'>\
<name>USA&America</name>\
<state id='1'>Arizona\
<city id="1">\
<name>Phoenix</name>\
<population>5000000</population>\
</city>\
<city id="2">\
<name>Tuscon</name>\
<population>1000000</population>\
</city>\
</state>\
<state id='2'>California\
<city id="1">\
<name>Los Angeles</name>\
<population>19000000</population>\
</city>\
<city id="2">\
<name>Irvine</name>\
</city>\
</state>\
</country>\
<country id='2'>\
<name>Mexico</name>\
<state id='1'>Veracruz\
<city id="1">\
<name>Xalapa-Enriquez</name>\
<population>8000000</population>\
</city>\
<city id="2">\
<name>C\u00F3rdoba</name>\
<population>220000</population>\
</city>\
</state>\
<state id='2'>Sinaloa\
<city id="1">\
<name>Culiac\u00E1n Rosales</name>\
<population>3000000</population>\
</city>\
</state>\
</country>\
</countries>
xml-doc xmld to x
start-loop
read-xml x key k value v status s next
if-true s equal GG_ERR_EXIST
break-loop
end-if
text-utf v
@Key [<<print-out k>>] Value [<<print-out v>>]
end-loop
xml-doc delete x
%%
Copied!
The output would be:
Key [countries/country/id/@] Value [1]
Key [countries/country/name/] Value [USA&America]
Key [countries/country/state/id/@] Value [1]
Key [countries/country/state/city/id/@] Value [1]
Key [countries/country/state/city/name/] Value [Phoenix]
Key [countries/country/state/city/population/] Value [5000000]
Key [countries/country/state/city/id/@] Value [2]
Key [countries/country/state/city/name/] Value [Tuscon]
Key [countries/country/state/city/population/] Value [1000000]
Key [countries/country/state/] Value [Arizona]
Key [countries/country/state/id/@] Value [2]
Key [countries/country/state/city/id/@] Value [1]
Key [countries/country/state/city/name/] Value [Los Angeles]
Key [countries/country/state/city/population/] Value [19000000]
Key [countries/country/state/city/id/@] Value [2]
Key [countries/country/state/city/name/] Value [Irvine]
Key [countries/country/state/] Value [California]
Key [countries/country/id/@] Value [2]
Key [countries/country/name/] Value [Mexico]
Key [countries/country/state/id/@] Value [1]
Key [countries/country/state/city/id/@] Value [1]
Key [countries/country/state/city/name/] Value [Xalapa-Enriquez]
Key [countries/country/state/city/population/] Value [8000000]
Key [countries/country/state/city/id/@] Value [2]
Key [countries/country/state/city/name/] Value [Córdoba]
Key [countries/country/state/city/population/] Value [220000]
Key [countries/country/state/] Value [Veracruz]
Key [countries/country/state/id/@] Value [2]
Key [countries/country/state/city/id/@] Value [1]
Key [countries/country/state/city/name/] Value [Culiacán Rosales]
Key [countries/country/state/city/population/] Value [3000000]
Key [countries/country/state/] Value [Sinaloa]
Copied!
XML parsing
read-xml
xml-doc
See all
documentation
Copyright (c) 2019-2025 Gliim LLC. All contents on this web site is "AS IS" without warranties or guarantees of any kind.













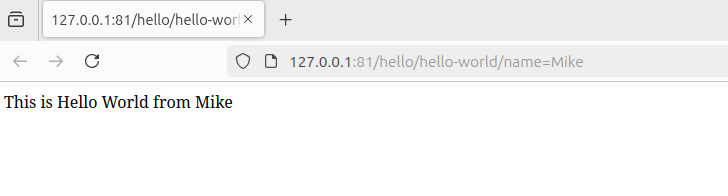




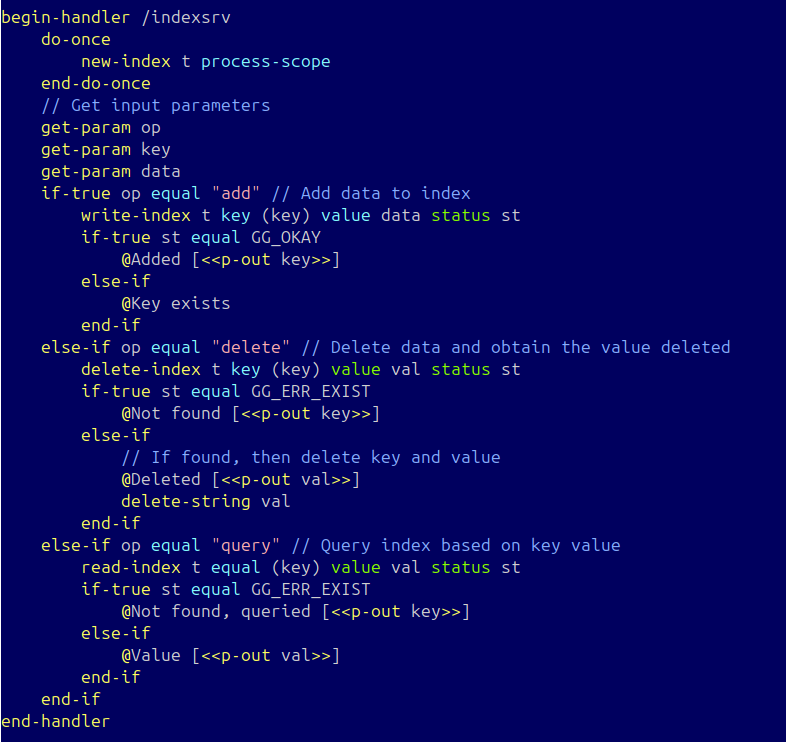
{kind=link}